认识 Eleven v3。
我们最具表现力的 AI 语音模型。


294/1000
由 Eleven v3 驱动
用音频标签控制情感、表达和方向
创建可控、富有表现力的语音,叠加情感、音频事件和沉浸式音效。

生成多说话人的动态对话
创建多说话人共享语境和情感的音频对话,让生成的对话更自然、更具人性化。

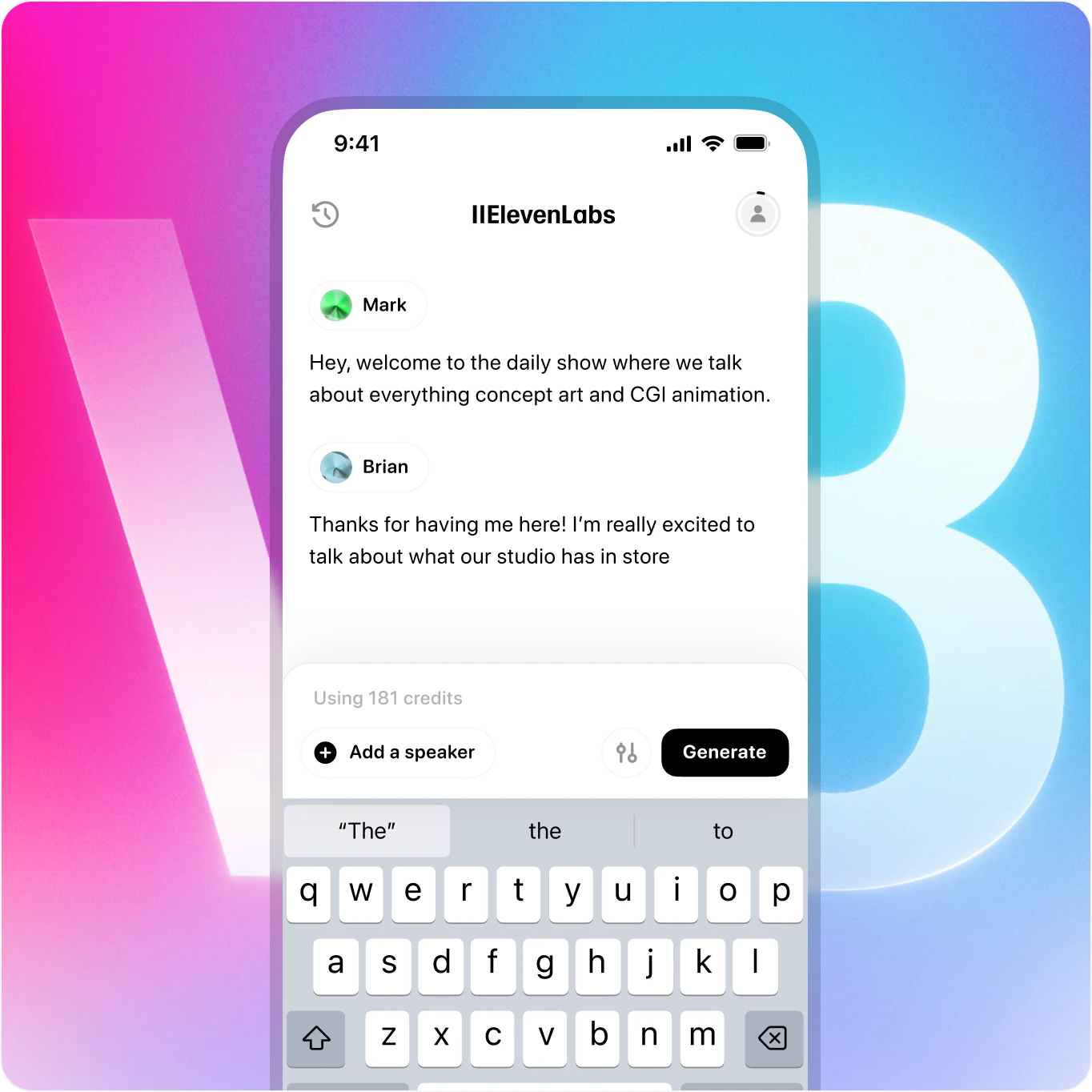
随时随地用 v3,现已支持移动端
用手机即可生成富有情感的逼真语音。AI 语音随时随地带来录音棚级表现。
70+ 种语言的人声语音
用丰富、细腻的语音覆盖全球受众,支持所有主流语言。

英语

中文

西班牙语

法语

葡萄牙语

德语

日语

意大利语

印地语
体验我们最具表现力的模型,展现丰富情感和细腻表达。
Eleven v3 不同于其他 ElevenLabs 模型,可通过内嵌音频标签控制更广的动态范围。
多说话人(对话模式)
音频标签支持
全情感、指令和音效支持
基础标签,如停顿和断句
语言
70+
29
用 Eleven v3 API 构建应用
通过内嵌音频标签,支持 70 多种语言,生成富有情感、可控方向、多说话人的逼真语音。

import { ElevenLabsClient, play } from '@elevenlabs/elevenlabs-js';
import 'dotenv/config';
const elevenlabs = new ElevenLabsClient();
const voiceId = 'JBFqnCBsd6RMkjVDRZzb';
const audio = await elevenlabs.textToSpeech.convert(voiceId, {
text: '[slowly] 那时候…… [chuckles] 没有手机。
[whispers] 只有土路和 [coughs] 大梦想。[sad] 后来发生了变化',
modelId: 'eleven_v3',
outputFormat: 'mp3_44100_128',
});
await play(audio);