



























.png&w=3840&q=80)
ElevenLabs 正式进入加拿大
- 分类
- 公司
- 日期
Trusted by 1M+ users • Free to start

Create controllable, expressive speech layered with emotion, audio events, and immersive soundscapes.
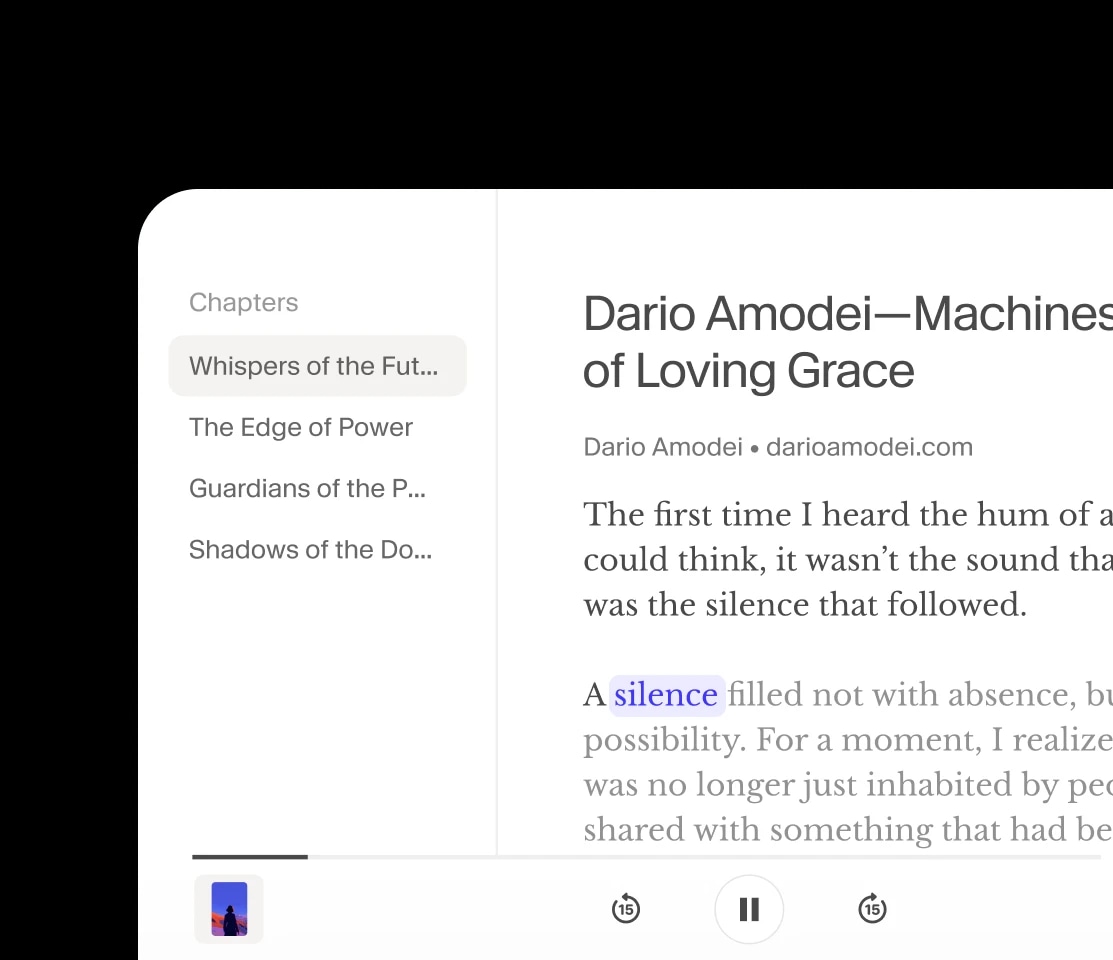
声音停顿了一下,[轻声] 仿佛在思考,随后继续。每一次呼吸都很有节奏,每一次停顿都恰到好处。
这已不再是合成语音,[温暖地笑] ——而是懂得节奏、情感和停顿的声音。
文字变得有存在感。[满足地叹气] 文字被赋予了生命、个性和灵魂。
Explore an ever-growing collection of expressive, lifelike voices for any use case - from narration to character creation.
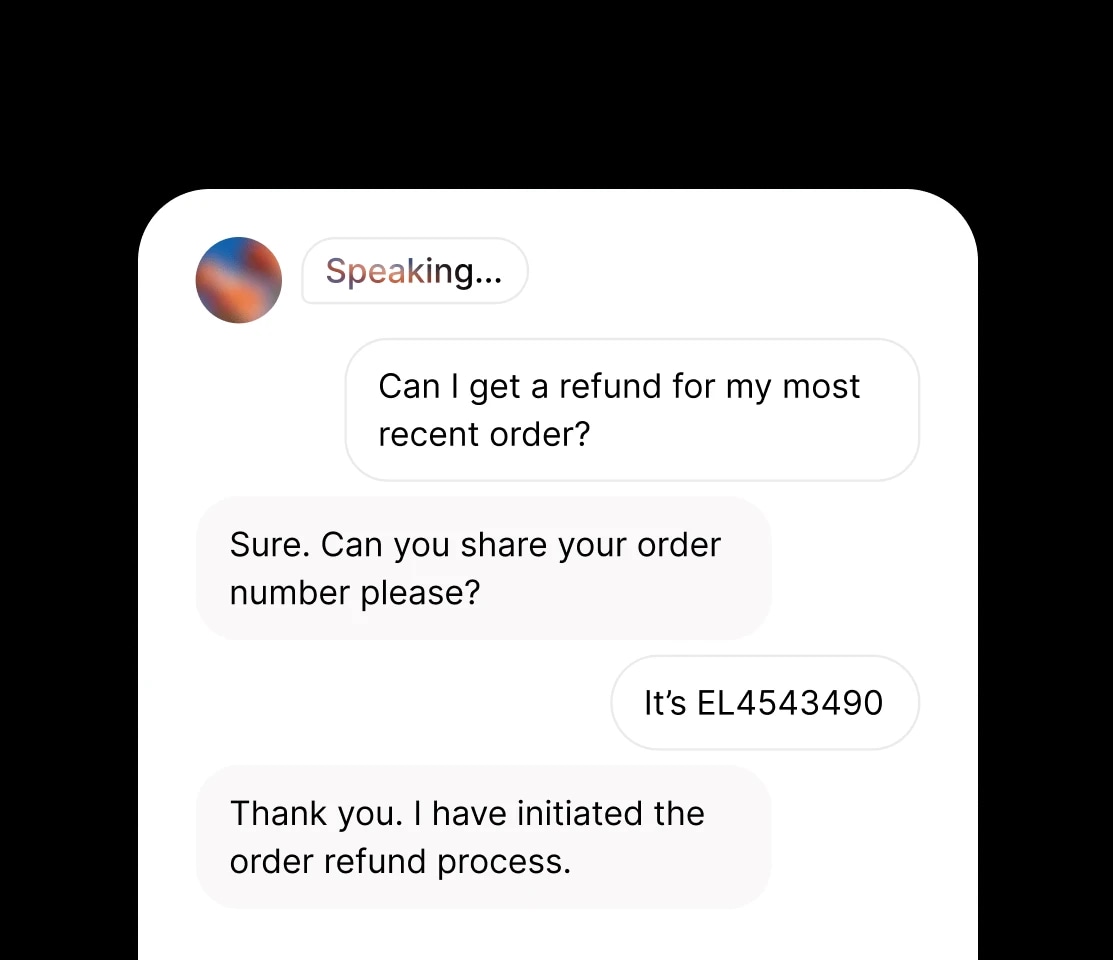
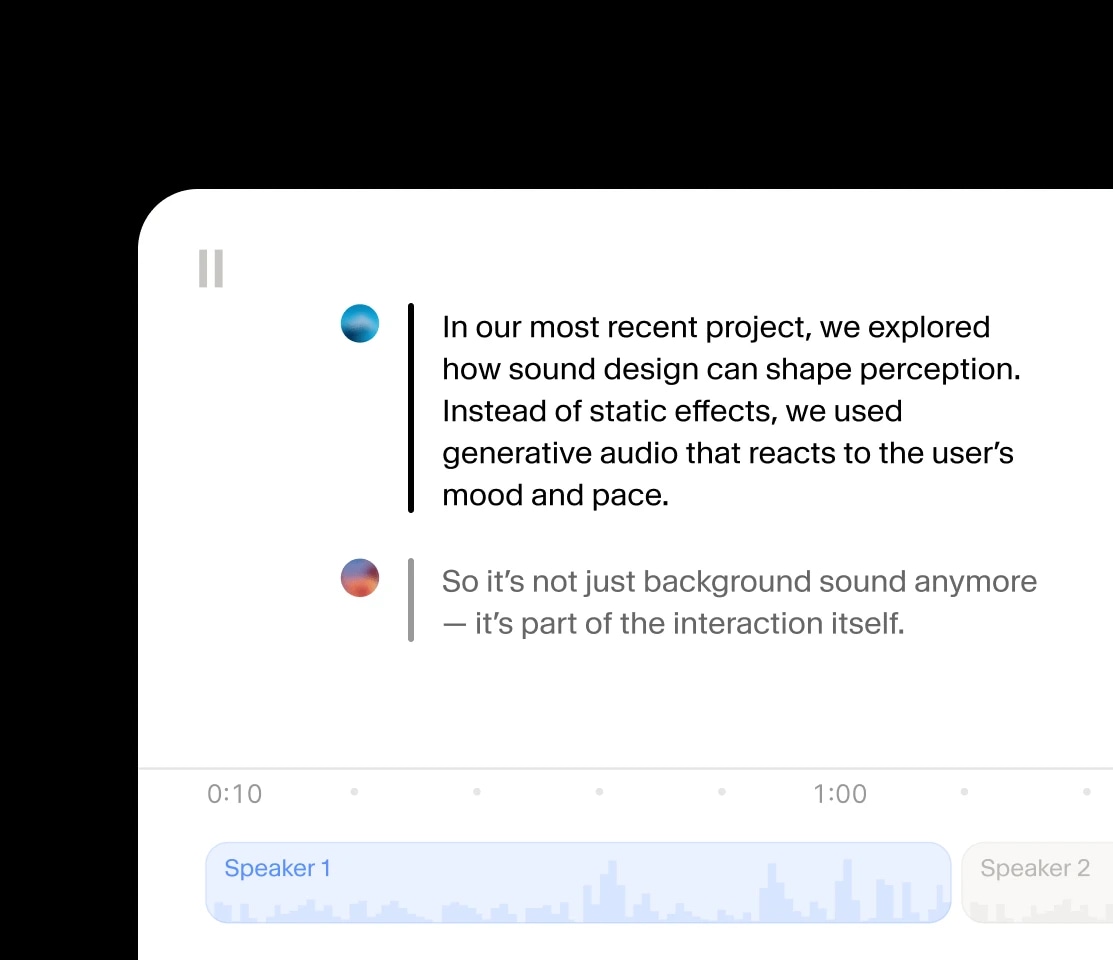
Create audio conversations where speakers share context and emotion.
Instantly replicate your own voice or craft unique AI Voices with full control.
Bring stories to life in over 70 languages, all with native-level emotion and clarity.



Our most advanced, expressive model with audio tags for precise emotional control. Best for storytelling, gaming and media production in 70+ languages.

Our most lifelike, emotionally rich text to speech model supporting 29 languages. Best for voiceovers, audiobooks, post-production and content creation.

Our high quality, low latency TTS model in 32 languages. Best for developer use cases where speed matters and you need non-English languages

High quality, low-latency model with a good balance of quality and speed

The best AI audio models in one powerful editor.

Generate expressive audio in seconds using our iOS and Android apps.
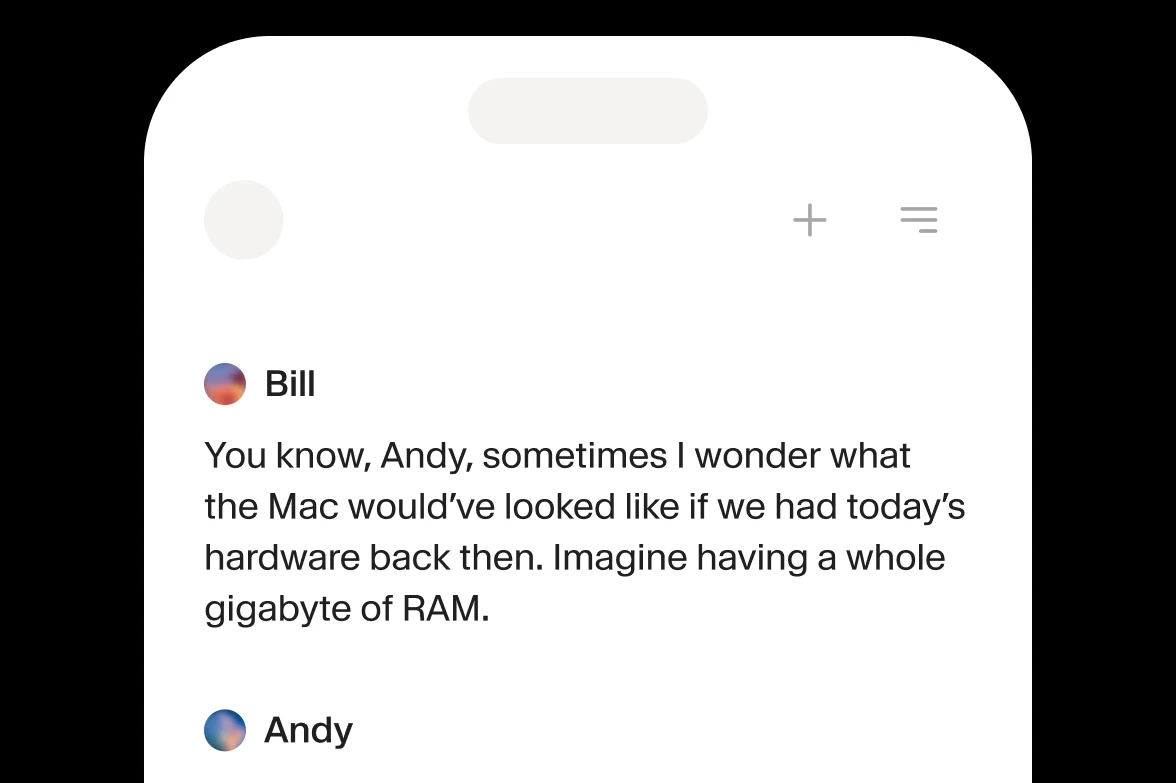
Integrate ElevenLabs Text to Speech (TTS) into your product via APIs or SDKs.

.jpg&w=3840&q=80)

.jpg&w=3840&q=80)


.png&w=3840&q=80)

