ボイスエージェント評価フレームワーク:6つの柱を解説
- 公開日
- 最終更新日
ボイスエージェントは、ほぼ同時に複数のツールを連携させる必要があります。リアルタイムでお客様の発言を録音しながら、繊細なバランスで進める作業です。
これだけ多くの要素が絡む中で、ボイスエージェントのパフォーマンスを正確に評価するにはどうすればよいのでしょうか?
この記事では、エージェントの成功を評価する際に何を測定すべきかを明確にする、6つの柱からなるボイスエージェント評価フレームワークを提案します。また、業界ごとに柱の重み付けが異なる理由や、評価時によくあるミスについても触れます。
概要
- 評価すべき6つの主な柱は、TTS音声品質、会話品質、ツール利用とタスク完了、知能、コンプライアンスとセーフティ、信頼性です。
- 目指すべき主な運用目標は、MOS4.3、TSR85%以上、タイムトゥファーストオーディオ500ms未満です。
- 業界によって各柱の重み付けは異なり、導入形態によって重視するポイントも変わります。
- よくあるテストのミスは、きれいな音声だけを評価したり、P99レイテンシのスパイクを無視することです。
- ElevenLabsは、最も重要な指標でリードしています:Scribe v2はWER2.2%(Artificial Analysis、2026年6月)で業界最小、Flash v2.5とTurbo v2.5は速度でトップ(Artificial Analysis、2026年6月)、ElevenAgentsは約75msのモデル推論レイテンシを実現しています。
ボイスエージェント評価フレームワークとは?
AIボイスエージェント評価フレームワークとは、複数の観点からパフォーマンスをテストできる体系的な仕組みです。音声の忠実度から会話の流れ、法令遵守まで、あらゆる項目を評価する指標が含まれます。
テキストチャットボットと異なり、ボイスエージェントは最低でも3つの技術(自動音声認識(ASR)でユーザーの発話をテキスト化、LLMで応答生成、TTSで音声化)を組み合わせて動作します。どれか1つでも失敗すると、全体の体験が損なわれます。
この複雑さがあるからこそ、企業はプロバイダー選定や導入前にボイスエージェントを評価する必要があります。レイテンシの増加や不正確な応答は、顧客離れや最悪の場合は規制違反・評判の低下など、現実的な影響を及ぼす可能性があります。
ボイスエージェント評価フレームワークは、ベンチマークや測定可能なデータを使って、特定の用途にエージェントが適しているかどうかを判断します。ビジネスの観点では、異なるボイスモデルを評価できることで、顧客に最適なものを選択できます。
評価すべき6つのボイスエージェント評価の柱
AIエージェントの作成・導入 はこれまでになく簡単になりましたが、裏側で動くプロセスはかなり複雑です。複数の要素が連携してユーザーの話を聞き、意図を理解し、LLMに情報を渡し、音声応答を生成するため、ほぼ同時に多くの処理が行われます。
最適なボイスエージェントと提携するには、企業は厳格なフレームワークでベンチマークを行う必要があります。
テスト結果を見たい場合は、人工分析 が、さまざまな構成要素ごとにエージェント比較を提供しています。下記は、モデルごとの速度比較結果で、ElevenLabsのTurbo v2.5 とFlash v2.5が、1秒あたりの処理文字数で大きくリードしています。
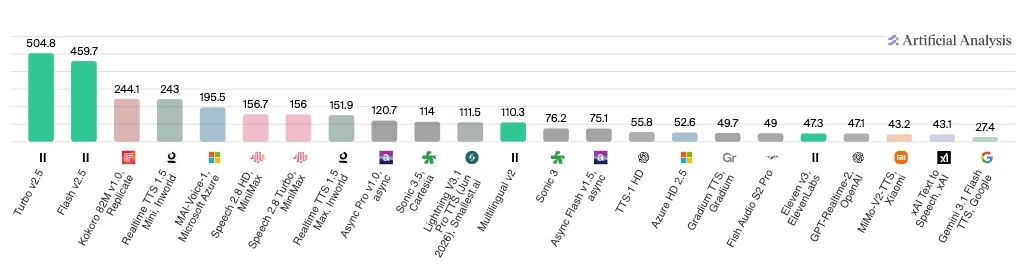
独自に実験したいデベロッパーや企業向けに、AIエージェント評価フレームワークの6つの柱を紹介します:
- TTS音声品質: 合成音声がどれだけ自然で明瞭、かつ表現豊かに聞こえるか。業界トップモデルのEleven v3は、70以上の言語で人間らしい感情表現を実現しています。
- 会話品質: モデルが人間の発話を理解し、意味を把握し、複数ターンにわたって適切に応答できるかどうか。
- ツール利用:AIエージェントが人の手を借りずに、利用可能なリソースを使ってタスクをどれだけ完了できるか。
- 知能:モデルがどれだけ論理的に考え、新しい入力に対応し、不正確または幻覚的な応答を避けられるか。
- コンプライアンスとセーフティ:すべての機能に加えて、
- 信頼性:総稼働時間や負荷時の安定したパフォーマンスなどの要素から、会話型AIエージェントが需要に応じてスケールできるかを判断します。
これらの柱はそれぞれ独立していますが、相互に連携してユーザーに高品質な体験を提供します。例えば、音声品質が向上してもレイテンシが高いままだと、顧客は応答までの待ち時間が長くなり、違和感を覚えます。
これらのボイスAI評価の柱を、さらに詳しく見ていきましょう。
TTS音声品質
まず音声品質から始めます。これはAI会話エージェントとやり取りする際、人間が最初に気づくポイントだからです。ロボットのようだったり、不自然に感じると、主観的な体験は大きく損なわれます。
国際電気通信連合(ITU-T)が定義した代表的な評価指標の1つが、Mean Opinion Score(MOS)です。MOSは1~5のスケールで、1が使い物にならない、5が優秀です。主観的な評価なので、人間のリスナーが通話後にフィードバックを集めて算出します。
このスケールでMOS3.5未満は、現代基準ではあまり良いとは言えず、顧客満足度にも影響します。
MOSは人間中心の指標ですが、実際にはいくつかの技術的要素が影響します:
- ピッチの一貫性とジッター:ピッチとジッターは、人間が自然に聞き取る言語的要素です。「ピッチ」は発話中のイントネーションの変化(例:質問時に声が上がる)を指します。ジッターは、ボイスモデルがピッチをうまく保てず、文全体で抑揚が乱れる現象です。業界基準のジッターは30msです。
- 感情表現力: 声が明瞭で正確でも、文の意図した感情に合っていなければ違和感があります。正確なトーンがないと、AI会話エージェントへの親近感が薄れ、評価も下がります。ElevenAgentsは、人間に近い感情表現力で、すべての応答に明確な感情を込められます。
- バックグラウンドノイズ: ボイスエージェントのバックグラウンドノイズには、評価すべき2つの側面があります。出力側では、自然に聞こえるように環境音を加えることがあります。入力側では、STT層でバックグラウンドノイズフィルターをオンにすることで認識精度が向上します。評価時は両方をテストしましょう:環境音が自然か、ノイズフィルターの有無でSTT精度がどう変わるかを確認してください。
MOSを算出する際は、4.3~4.5を目指しましょう。これにより、これらすべての知覚的カテゴリで高評価を示せます。人間パネルなしで大規模にMOS予測を行う場合は、UTMOSやNISQAなどのツールが利用できます。
会話品質
会話品質は、音声品質とタスク完了の間に位置する複合的な柱です。ボイスエージェントがユーザーのニーズをどれだけ正確に理解し、文脈に沿って会話を進め、複数ターンの対話を完了できるかを測定します。
ここでの主な指標はインテント分類精度で、一般的には85~92%、トップモデルは96%以上を記録します。85%でも高く見えますが、全体の15%が誤分類され、誤ったリソースにルーティングされていることになります。
インテント分類精度を高める技術的要素は以下の通りです:
- ターンテイキング: ターンテイキングは、ボイスエージェントが会話の自然な流れをどれだけうまく管理できるかを示します。聞く・応答する・待つタイミングを判断し、バージイン(途中割り込み)にも対応します。ElevenLabsは、マルチコンテキストWebSocketで、こうした割り込みもスムーズに処理します。
- レイテンシ:レイテンシは、ユーザーが発話を終えてからエージェントが音声応答を始めるまでの遅延です。運用レベルのボイスエージェントは、タイムトゥファーストオーディオ500ms未満、300ms以下ならさらに優秀です。ElevenLabsのFlashモデルは、約75msの業界最速モデル推論時間を実現し、この分野で優位性を持っています。
- フォールバック率: フォールバック率は、AIエージェントがユーザーを理解できず、確認や繰り返しを求める頻度を示します。主にSTT精度の影響を受け、認識層が誤認するとLLMに誤った入力が渡ります。フォールバック率は「フォールバック数/総インタラクション数×100」で算出します。
ElevenLabs Scribe V2はArtificial Analysisのスピーチtoテキストモデル評価でWER2.2%を記録
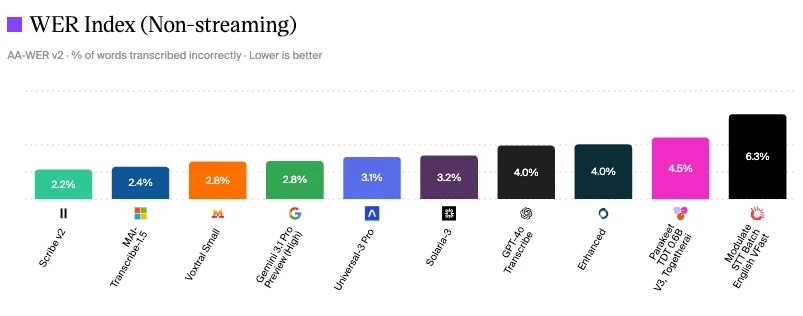
Artificial Analysisによるスピーチtoテキストモデル評価
会話品質を測る方法の1つは、各構成要素の業界ベンチマーク基準を見ることです。ご覧の通り、ElevenLabsのScribe v2は2026年6月時点でWER2.2%と最小で、聞き間違いやフォールバックが減り、インテント分類もより正確です。
会話品質は、ボイスエージェントが使われるワークフローにも左右されます。たとえばカスタマーサービスでは、エスカレーションの引き継ぎやFAQ解決の質も重要な観点となります。
ツール利用とタスク完了
会話の質が「どんな体験だったか」を測るのに対し、タスク完了は「目的が達成されたか」を測ります。エンタープライズでは、ビジネス成果に直結するため、この部分を特に重視すべきです。
ツール利用の1つの指標がスロットフィル精度です。これは、顧客情報の入力など定型タスクをどれだけ正確に完了できるかを示します。スロットフィル精度が高いほど、会話からアクションへの移行がスムーズで、情報の取りこぼしもありません。
タスク成功率(TSR)は、エージェントがエンドツーエンドでタスクをどれだけ完了できたかをパーセンテージで示します。ここでの完了は、リクエストを理解し、適切なツール(API、データベース、RAG、社内ナレッジベースなど)を使って対応できたかで判断します。
TSRの計算式は:
TSR =(完全に完了したタスク数/試行タスク総数)×100
運用レベルのボイスエージェントは、TSR85%以上を目指し、ツール呼び出しの精度や信頼性も監視しましょう。TSRの低下を防ぐには、プロンプトやモデルの変更時にリグレッションテストを必ず実施してください。わずかな変更でもTSRに大きな影響を与えることがあります。
知能
知能は、ボイスエージェントの推論力や高度な能力を示します。この柱が、IVR(自動音声応答)とボイスAIエージェントの違いを明確にします。
ここで評価すべき主な観点は:
- 幻覚リスク: 幻覚(事実と異なる情報や社内文書と矛盾する内容を生成すること)は、ボイスAIでは自信を持って話されるため特に危険です。最近の研究では、 幻覚が顧客満足度を大きく損なうことが示されています。
- スコープ外対応: インテリジェントなエージェントは、質問が自分の範囲外であることを理解し、無理に答えず適切に断ったり、会話を本来の範囲に戻すことができます。
- コンテキスト保持: 複数ターンにわたり、エージェントが以前の発言や約束を追跡できるか。これができないと、顧客は同じことを繰り返し伝えたり、矛盾した応答を受けることになります。
- 推論・マルチステップロジック: 条件分岐や複数ターンにわたる推論を正しく処理できるか。特に金融サービスなど技術的な用途では、定義されたコンテキスト内で推論できることが成功の鍵です。
これらの観点や構成要素には、サードパーティのベンチマークも存在します。たとえば、StanfordのHELM(Holistic Evaluation of Language Models)はLLMの性能を多角的に評価します。幻覚についてはTruthfulQAが、誤答の頻度を詳細に分析します。
ElevenAgentsの強みは、他のボイスプラットフォームのように単一モデルに縛られず、LLM層を自由に入れ替えられる点です。つまり、用途ごとに推論ベンチマークで最も優れたモデルを選んで組み込めます。
コンプライアンスとセーフティ
企業は、有害な出力やポリシー違反を防ぐため、アクティブなガードレールを導入する必要があります。システムレベルのプロンプト指示だけでは回避されたり上書きされる可能性があるため、独立したガードレールチェックをモデル外部で実行し、ユーザーに届く前に出力を評価し、危険な内容なら会話を停止します。
監査性も重要で、運用エージェントは意思決定や出力の詳細なログを、事後レビュー可能な形式で保持する必要があります。特に規制の厳しい業界では、事後にコンプライアンスを証明できることも重要です。
遵守すべき具体的な規制は業界ごとに異なります。よく適用されるフレームワークは:
- HIPAA: 米国医療分野で保護される健康データ向け。
- PCI-DSS: 決済カードデータを扱うエージェント向け。
- GDPR: EUおよびEU顧客を持つ企業のデータプライバシー義務。
自社のコンプライアンス状況を評価する場合、ElevenLabsはAICPA SOC2 Type IIとGDPR準拠に加え、AIUC-1認証も取得しています。AIUC-1はAIエージェント向けに設計されたセキュリティ基準です。
信頼性
信頼性は、ボイスエージェント評価フレームワークの最後の柱で、リアルタイムで安定して稼働できるかをカバーします。
ボイスエージェントを評価する際は、以下の特徴を確認しましょう:
- 稼働率:顧客向けの運用では、99.9%の稼働率が求められます。特にインバウンドサポートなど常時稼働が必要な用途では、信頼性の高い稼働率が重要です。
- グレースフルデグレード: ボイスエージェントの複雑さゆえ、どこかの構成要素が不調になった場合は、無理に動作を続けず、人間への切り替えなどで負荷やエラーを最小限に抑えるべきです。
- 負荷時のパフォーマンス: 負荷テストでは、想定ピークの2倍以上の同時接続をシミュレーションしましょう。大規模時にのみ現れるレイテンシ増加や性能低下を特定できます。
他の条件をすべて満たしていても、顧客需要にスケールできなければ使い物になりません。ElevenAgentsは100万以上のクリエイターや企業に信頼され、エンタープライズ規模の導入でもパフォーマンス基準を維持しています。
ボイスエージェントのMOSを測定する方法(ステップバイステップ)
自社でMOSを手動測定したい場合は、多数の人間リスナーと実際の会話から抽出した音声クリップが必要です。フィードバック収集・平均化・データ解釈という構造化されたプロセスです。
実際にボイスエージェントのMOSを測定する手順は以下の通りです:
- テストセットの準備: エージェントの音声出力から、100クリップ以上の会話を幅広くサンプルします。
- 評価セッションの実施: 人間リスナーに、コミュニケーション体験の質を1~5で評価してもらいます。
- 評価の集計とスコア算出: 各クリップの評価を平均し、全サンプルの平均を出してMOSとします。MOS4.3以上なら運用準備が整っています。
手作業で手間はかかりますが、この方法なら選んだボイスエージェントのMOSを正確に把握できます。大規模にテストしたい場合は、NISQAなどの自動ツールでMOSスコアをプログラム的に予測できます。これらをパイプラインに組み込めば、MOSを継続的に監視できます。
AIと人間のテストベンチマーク:FCR、AHT、CSAT
MOSを継続的に測定することでモデルの進化や劣化を確認できますが、人間のパフォーマンスと比較することで、さらに深い洞察が得られます。実際に人間が同じ役割でどの程度達成しているかを見ることで、ボイスエージェントが理想にどれだけ近いかが分かります。
AIと人間のテストベンチマークで考慮すべき指標をいくつか紹介します。
AIエージェントは、人間のFCRやCSATに匹敵しつつ、AHTを大幅に短縮できるはずです。AHTが短縮されるのは、AIエージェントが一般的な会話を多く処理するためです。多くの企業では、AIエージェントが一次対応を行い、複雑な案件のみ人間に引き継ぐワークフローを採用しています。
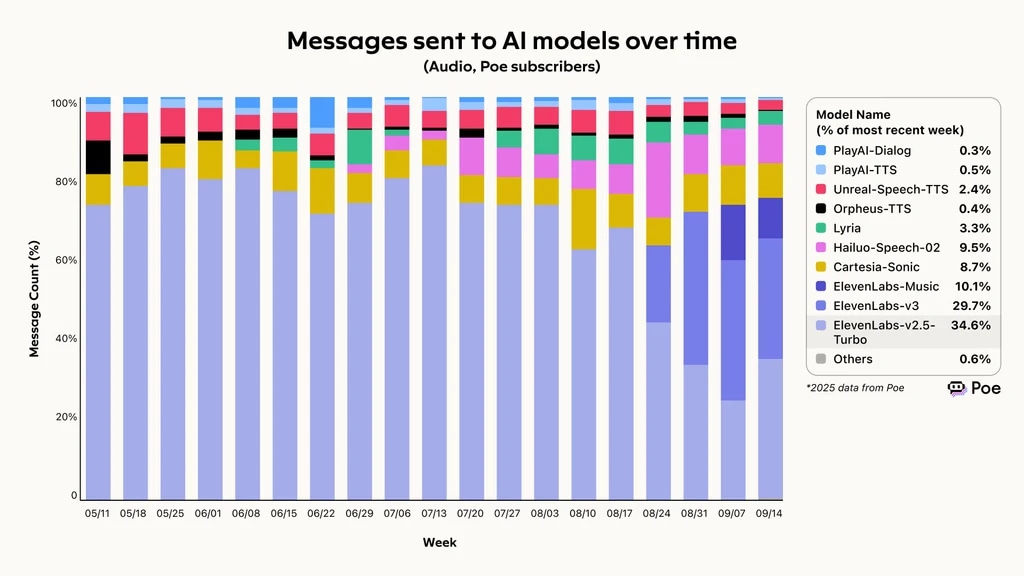
AI比較集約サービスPoeの2025年データによると、ElevenLabsはリクエスト対応能力で最も高い実績を維持し、全リクエストの74.4%を完了しました。この成功により利用が急増し、Eleven v3とv2.5-TurboはAIモデルへのメッセージ送信の60%以上を占めています。
AIモデルへのメッセージ送信推移、ElevenLabsがpoeボイスエージェント評価フレームワークでリード
よくあるボイスエージェントテストのミス
ボイスエージェント評価フレームワークに従うと、理想的なケースだけをテストしたくなります。しかし実際には、顧客がボイスAIとやり取りする日常体験は、必ずしも理想的な条件ではありません。
よくあるボイスエージェントテストのミスと、その対策を3つ紹介します:
- 簡単なケースだけをテストする: 特にMOS用の音声クリップ選定時は、イレギュラーなケースも必ず含めましょう。バックグラウンドノイズや訛りのある発話は現実で非常に多いため、「きれいな」音声だけでテストするとMOSが過大評価されます。
- 解決より囲い込みを優先する:ユーザーをエージェント内に留めることだけを最適化すると、囲い込み率は上がっても成果は改善しません。FCRが低いのに囲い込み率が高い場合、ユーザーは同じループを繰り返し、ストレスを感じます。希望する場合は人間エージェントに繋げる仕組みも用意しましょう。
- レイテンシパーセンタイルを無視する:SLAではP95レベルのレイテンシがよく使われますが、最後の5%も実際の顧客です。1万件の通話を処理するシステムなら、5%でも500人が遅い会話を体験しています。SLAの目標は中央値やP95だけでなく、P99を重視しましょう。
これらを意識することで、理想的な平均値ではなく、公平で実態に即した基準を作れます。
用途別評価の重要性
このフレームワークで示した6つの柱は指針となりますが、各柱の重み付けは業界によって異なります。たとえば金融サービス業ではコンプライアンスやツール利用が重視され、消費者向けブランドではTTS音声品質が最重要となる場合もあります。
用途別評価の実例と、各柱のバランスがどう変わるかを2つ紹介します。
カスタマーサポート
コールセンターなど特定業界では、一次解決率(FCR)など他のタスク完了指標も重要です。人の手を借りずに着信を処理できれば、カスタマーサービス担当者の負担を大幅に減らせます。McKinseyの試算では、 ボイスエージェント導入でコールセンターの対応件数を最大50%削減できるとされています。
タスク成功率ほどではありませんが、囲い込み率も考慮すべき指標です。囲い込み率が高くてもFCRが低い場合、顧客は解決せずに長時間拘束され、フラストレーションが溜まります。
他に追跡すべき指標はAHTで、AIエージェントは定型問題を素早く解決することが求められます。そのためカスタマーサポート分野では、会話品質(特にターンテイキングやフォールバック率)が他の分野より重視されます。
ヘルスケア
ヘルスケアは規制が非常に厳しい分野で、コンプライアンス要件がボイスエージェント運用を非常に繊細にします。コンプライアンスが中心課題となり、このフレームワークのセーフティ柱の重み付けが大きくなり、知能も最重要となります。
ヘルスケアチャットボットは、予約管理、遠隔医療アクセス、症状トリアージ、保険対応などを扱う必要があります。これらは高い知能とツール利用力が求められ、業界や役割ごとに重視する柱が変わることを示しています。
どの分野でも、ボイスエージェント評価の柱を理解し、バランスよく適用することで、最適なエージェントを見つけやすくなります。
高性能・低レイテンシのElevenAgentsで構築
どのプラットフォームで構築するかは、実際のワークフローでボイスエージェントがどう動くかに直結します。特に顧客対応では、すべてのカテゴリでエージェントが期待を超えることが重要です。
ElevenAgentsは運用向けボイス導入に最適化されており、業界トップのTTS(Eleven v3)、リアルタイムSTT(Scribe v2)、エージェントオーケストレーション層を組み合わせてエンタープライズ規模に対応しています。すべての構成要素がこのフレームワークのベンチマークを満たすよう設計されており、顧客に高品質な体験を提供できます。
選択肢を比較中でも、すぐに構築を始めたい場合でも、ElevenLabsなら最適な道があります。ぜひElevenAgentsプラットフォームで用途との相性を確認するか、サインアップして今日から構築を始めてください。




