Cadre d’évaluation des agents vocaux : explication des 6 piliers
- Rédigé par
- Jack Limebear
- Publié
- Dernière mise à jour
ÉcouterÉcouter cet article
Les agents vocaux doivent coordonner plusieurs outils presque simultanément. C’est un équilibre subtil entre l’enregistrement des commentaires d’un client en temps réel avec le
Avec autant d’éléments en jeu, comment évaluer précisément la performance d’un agent vocal ?
Dans cet article, nous proposons un cadre d’évaluation des agents vocaux en six piliers qui détaille exactement quoi mesurer pour juger du succès d’un agent. Nous verrons aussi pourquoi chaque secteur doit pondérer ces piliers différemment, et les erreurs courantes à éviter lors de l’évaluation.
Résumé
- Les six piliers principaux à utiliser pour évaluer un agent vocal sont la qualité de la voix TTS, la qualité de la conversation, l’utilisation des outils et la réussite des tâches, l’intelligence, la conformité et la sécurité, ainsi que la fiabilité.
- Les objectifs de production les plus importants sont un MOS de 4,3, un TSR supérieur à 85 %, et un temps de première réponse audio inférieur à 500 ms.
- Chaque secteur va pondérer ces piliers différemment, certaines applications privilégiant l’un plus que les autres.
- Les erreurs courantes lors des tests incluent le fait de n’évaluer que l’audio propre et d’ignorer les pics de latence P99.
- ElevenLabs se distingue sur les indicateurs les plus importants : Scribe v2 atteint le taux d’erreur de mots (WER) le plus bas du secteur à 2,2 % (Artificial Analysis, juin 2026), Flash v2.5 et Turbo v2.5 sont les modèles les plus rapides (Artificial Analysis, juin 2026), et ElevenAgents offre une latence d’inférence d’environ 75 ms.
Qu’est-ce qu’un cadre d’évaluation des agents vocaux ?
Un cadre d’évaluation des agents vocaux IA est un système structuré qui permet de tester la performance sur plusieurs axes. Un cadre complet inclut des indicateurs pour évaluer tout, de la fidélité audio au déroulement de la conversation, jusqu’à la conformité réglementaire.
Contrairement à un chatbot textuel, un agent vocal fait passer chaque interaction par au moins trois technologies empilées : la reconnaissance automatique de la parole (ASR), qui convertit les propos de l’utilisateur en texte ; un LLM qui génère une réponse ; et un système TTS qui transforme cette réponse en audio. Si l’un de ces systèmes échoue, c’est toute l’expérience qui s’en ressent.
Cette complexité explique pourquoi les entreprises doivent évaluer les agents vocaux avant de choisir un fournisseur et de déployer la solution. Toute latence supplémentaire ou réponse imprécise peut avoir des conséquences concrètes, comme la perte de clients ou, pire, des sanctions réglementaires et des atteintes à la réputation.
Un cadre d’évaluation des agents vocaux s’appuie sur des benchmarks et des données mesurables pour déterminer si un agent est adapté à certains cas d’usage. Pour une entreprise, comparer différents modèles vocaux permet de choisir le meilleur pour ses clients.
Les six piliers à évaluer pour un agent vocal
Même si créer et déployer un agent IA n’a jamais été aussi simple, les processus actifs en coulisses restent complexes. Plusieurs composants agissent ensemble pour écouter l’utilisateur, comprendre sa demande, transmettre l’information à un LLM, puis produire une réponse audio : de nombreuses actions quasi simultanées sont nécessaires.
Pour collaborer avec le meilleur agent vocal possible, les entreprises ont besoin d’un cadre rigoureux pour se comparer aux références du secteur.
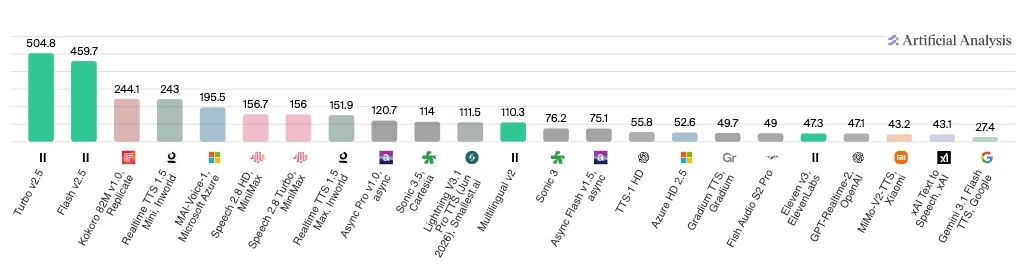
Si vous souhaitez surtout voir les résultats des tests, Analyse artificielle propose plusieurs comparaisons d’agents selon différents composants. Ci-dessous, vous pouvez voir les résultats de leur comparaison de vitesse entre modèles, avec ElevenLabs Turbo v2.5 et Flash v2.5 en tête pour le nombre de caractères traités par seconde.
Pour les développeurs ou entreprises qui veulent mener leurs propres tests, voici les six piliers d’un cadre d’évaluation d’agent IA à utiliser :
- Qualité de la voix TTS : À quel point la voix synthétisée paraît naturelle, claire et expressive pour les utilisateurs finaux. Les meilleurs modèles du secteur, comme Eleven v3, offrent un rendu humain et expressif dans plus de 70 langues.
- Qualité de la conversation : Le modèle comprend-il la parole humaine, saisit-il le sens et répond-il rapidement dans le bon contexte, même sur plusieurs échanges ?
- Utilisation des outils : Dans quelle mesure un agent IA accomplit-il des tâches avec les ressources disponibles, sans intervention humaine ?
- Intelligence : Le modèle raisonne-t-il correctement, gère-t-il les entrées inédites et évite-t-il de produire des réponses erronées ou inventées ?
- Conformité et sécurité : En plus de toutes ces fonctionnalités,
- Fiabilité : Des éléments comme la disponibilité totale et la performance constante sous charge permettent de savoir si un agent IA conversationnelle peut s’adapter à la demande.
Chacun de ces piliers est indépendant, mais ils sont liés pour offrir une expérience finale de qualité à l’utilisateur. Par exemple, si un modèle améliore la qualité de sa voix mais reste lent, le client subira des temps d’attente gênants avant d’entendre la réponse.
Voyons chaque pilier d’évaluation des agents vocaux IA plus en détail.
Qualité de la voix TTS
Nous commençons par la qualité de la voix, car c’est souvent la première chose que l’on remarque lors d’une interaction avec un agent conversationnel IA. Si la voix paraît robotique ou étrange, l’expérience sera nettement moins agréable.
L’un des premiers indicateurs d’évaluation, défini par l’Union internationale des télécommunications (UIT-T), est le Mean Opinion Score (MOS). Le MOS s’évalue sur une échelle de 1 à 5, 1 étant inutilisable et 5 excellent. Cette mesure subjective fait appel à des auditeurs humains qui donnent leur avis après un appel.
Un score MOS inférieur à 3,5 est peu impressionnant, surtout aujourd’hui, et risque d’impacter la satisfaction client.
Même si le MOS est un indicateur centré sur l’humain, plusieurs critères techniques y contribuent :
- Cohérence de la hauteur et jitter : La hauteur et le jitter sont deux éléments linguistiques que l’oreille humaine perçoit naturellement. La « hauteur » correspond à l’intonation qui varie dans la parole, par exemple quand on pose une question. Le jitter désigne la variation de la hauteur dans un modèle vocal, qui l’empêche de garder une prosodie cohérente sur une phrase. La référence du secteur pour le jitter est de 30 ms.
- Expressivité émotionnelle : Une voix claire et précise paraît tout de même fausse si le ton ne correspond pas à l’émotion attendue dans la phrase. Sans indices de ton justes, les utilisateurs auront moins d’affinité avec les agents conversationnels IA et les noteront moins bien. ElevenAgents propose une expressivité quasi humaine pour adapter chaque réponse à l’intention émotionnelle voulue.
- Bruit de fond : Le bruit de fond dans les agents vocaux a deux aspects à évaluer. En sortie, un bruit ambiant subtil peut être ajouté pour rendre la voix plus naturelle. En entrée, le filtrage du bruit sur la couche STT est une option qui améliore la précision. Lors de l’évaluation, testez les deux : vérifiez si le bruit ambiant paraît naturel et évaluez la précision du STT avec et sans filtre.
Pour le MOS, visez un score entre 4,3 et 4,5, ce qui montre de bons résultats sur toutes ces dimensions perceptives. Pour prédire le MOS à grande échelle sans panels humains, vous pouvez utiliser des outils comme UTMOS et NISQA.
Qualité de la conversation
La qualité de la conversation est un pilier composite, entre la qualité de la voix et la réussite des tâches. Elle mesure la capacité d’un agent vocal à comprendre les besoins de l’utilisateur, à l’interrompre au bon moment et à mener un dialogue sur plusieurs échanges jusqu’à la résolution.
L’indicateur principal ici est la précision de la classification d’intention, généralement comprise entre 85 % et 92 %, les meilleurs atteignant plus de 96 %. Même 85 % signifie que 15 % du trafic entrant est mal catégorisé et orienté vers de mauvaises ressources.
Les éléments techniques qui contribuent à une bonne classification d’intention sont :
- Gestion des tours de parole : La gestion des tours de parole mesure la capacité d’un agent vocal à suivre le rythme naturel d’une conversation. Il s’agit de savoir quand écouter, répondre ou attendre plus d’informations. Cela inclut aussi la gestion des interruptions, où le modèle interrompt une réponse en cours pour en générer une nouvelle selon l’entrée reçue. ElevenLabs utilise un websocket multi-contexte pour gérer ces interruptions de façon fluide.
- Latence : La latence désigne le délai entre la fin de la phrase de l’utilisateur et le début de la réponse audio de l’agent. Un agent vocal prêt pour la production doit viser un temps de première réponse audio inférieur à 500 ms, moins de 300 ms étant idéal. Les modèles Flash de ElevenLabs offrent un temps d’inférence d’environ 75 ms, ce qui vous place en tête dans cette catégorie.
- Taux de fallback : Le taux de fallback mesure la fréquence à laquelle un agent IA ne comprend pas l’utilisateur et demande une clarification ou une répétition. C’est souvent lié à la précision du STT : si la reconnaissance vocale comprend mal, le LLM reçoit une entrée erronée. Le taux de fallback se calcule ainsi : Taux de fallback (%) = (Nombre de fallbacks / Nombre total d’interactions) * 100.
Scribe V2 d’ElevenLabs affiche le WER le plus bas à 2,2 % lors de l’évaluation Artificial Analysis des modèles Speech to Text
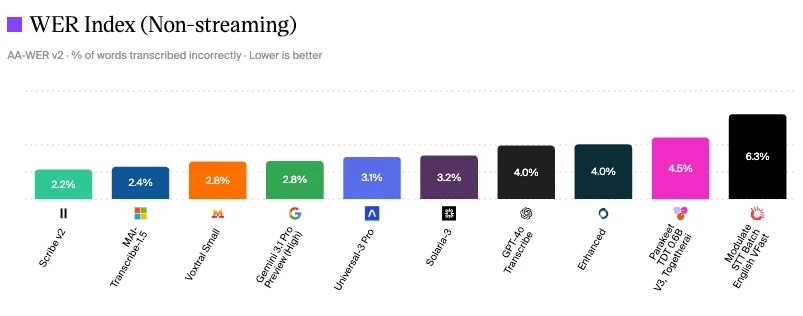
Évaluation des modèles Speech to Text par Artificial Analysis
Une façon de mesurer la qualité de la conversation est de regarder les références du secteur pour chaque composant. Comme vous pouvez le voir, Scribe v2 d’ElevenLabs affiche le taux d’erreur de mots le plus bas à 2,2 % en juin 2026, ce qui signifie moins d’erreurs d’écoute, moins de fallbacks et une meilleure classification d’intention.
Les entreprises peuvent constater que la qualité conversationnelle dépend aussi du workflow dans lequel l’agent vocal intervient. Par exemple, en service client, il faut aussi prendre en compte la qualité du transfert d’escalade ou la résolution des FAQ.
Utilisation des outils et réussite des tâches
Si la qualité mesure le ressenti de la conversation, la réussite des tâches mesure si elle aboutit à un résultat concret. Les entreprises doivent accorder une attention particulière à cette partie du cadre d’évaluation, car elle est directement liée aux résultats business.
Un indicateur d’utilisation des outils est la précision du remplissage des champs (slot-fill), qui mesure la capacité des agents IA à accomplir des tâches courantes, comme remplir un formulaire avec les informations d’un client. Une bonne précision montre que l’agent passe sans accroc de la conversation à l’action, sans perte d’information.
Le taux de réussite des tâches (TSR) est un pourcentage des tâches menées à bien de bout en bout par un agent. La réussite dépend ici de la capacité de l’agent à comprendre la demande puis à utiliser les bons outils connectés (API, bases de données, RAG, bases de connaissances internes) pour aider.
La formule du TSR est :
TSR = (Tâches entièrement réalisées / Total des tâches tentées) x 100
Un agent vocal prêt pour la production doit viser un TSR supérieur à 85 %, en surveillant la précision et la fiabilité des appels d’outils. Pour éviter toute baisse de TSR, testez systématiquement toute modification de prompt ou de modèle connecté. Même un petit écart peut avoir un impact important.
Intelligence
L’intelligence mesure la capacité de raisonnement et les fonctions avancées d’un agent vocal. C’est ce pilier qui distingue clairement un IVR classique d’un agent vocal IA.
Les dimensions clés à évaluer ici sont :
- Risque d’hallucination : Les hallucinations, où un agent fournit des informations inexactes ou incohérentes avec les documents de l’entreprise, sont particulièrement problématiques en audio IA car elles peuvent être prononcées avec assurance.Des études récentes montrent que les hallucinations courantes nuisent fortement à la satisfaction client avec les agents vocaux.
- Gestion des demandes hors périmètre : Un agent intelligent sait quand une question sort de son domaine de compétence et répond de façon appropriée. Plutôt que d’inventer une réponse, il refuse ou redirige la conversation vers un sujet pertinent.
- Rétention du contexte : Sur plusieurs échanges, l’agent peut-il suivre les entités et engagements pris précédemment ? Sinon, les clients risquent de devoir se répéter ou d’obtenir des réponses contradictoires.
- Raisonnement et logique multi-étapes : L’agent gère-t-il correctement la logique conditionnelle ou les inférences en chaîne sur plusieurs échanges ? C’est crucial dans les cas d’usage techniques, comme les services financiers, où la capacité à raisonner dans un contexte défini est essentielle.
Il existe plusieurs benchmarks tiers pour ces dimensions. Par exemple, le benchmark HELM de Stanford évalue les LLM sur différents critères. Pour les hallucinations, TruthfulQA analyse la fréquence des réponses fausses.
Un avantage d’ElevenAgents est que, contrairement à certaines plateformes vocales qui imposent un seul modèle, vous pouvez changer complètement la couche LLM. En pratique, cela signifie que vous pouvez choisir le modèle le plus performant sur les benchmarks de raisonnement pour votre cas d’usage.
Conformité et sécurité
Les entreprises doivent mettre en place des garde-fous actifs pour éviter les sorties nuisibles ou contraires aux politiques. Contrairement aux instructions système, qui peuvent être contournées, les garde-fous indépendants fonctionnent comme une couche séparée du modèle. Ils évaluent les réponses avant qu’elles n’atteignent l’utilisateur et stoppent la conversation si elle dévie vers un sujet risqué.
L’auditabilité est aussi essentielle : les agents en production doivent conserver des journaux détaillés des décisions et sorties, dans un format permettant une relecture a posteriori. Dans les secteurs très réglementés, prouver la conformité après coup est aussi important que de la respecter en temps réel.
Les réglementations à respecter varient selon le secteur. Voici les cadres les plus courants :
- HIPAA : Pour les données de santé protégées dans le secteur médical américain.
- PCI-DSS : Pour tout agent traitant des données de carte bancaire.
- RGPD : Obligations de confidentialité des données pour l’UE et les entreprises ayant des clients dans l’UE.
Pour les entreprises qui évaluent leur conformité, ElevenLabs est conforme SOC II Type II et RGPD, et a obtenu la certification AIUC-1. L’AIUC-1 est une norme de sécurité conçue spécifiquement pour les agents IA.
Fiabilité
La fiabilité est le dernier pilier de notre cadre d’évaluation, et concerne la capacité d’un agent à délivrer des résultats constants en temps réel.
Pour évaluer un agent vocal, vérifiez les points suivants :
- Disponibilité : Toute solution orientée client doit viser 99,9 % de disponibilité pour éviter les interruptions. C’est crucial pour les usages en continu, comme le support entrant.
- Dégradation maîtrisée : Vu la complexité des agents vocaux, si un composant commence à faillir, l’agent doit gérer cette dégradation de façon maîtrisée. Concrètement, cela signifie transférer à un humain plutôt que de continuer à fonctionner en mode dégradé ou en renvoyant des erreurs.
- Performance sous charge : Les tests de charge doivent simuler au moins 2 fois votre pic de trafic attendu avant la mise en production. Tester sous forte contrainte permet de détecter les hausses de latence ou la baisse de performance qui n’apparaissent qu’à grande échelle.
Même un modèle performant sur tous les autres critères peut devenir inutilisable s’il ne s’adapte pas à la demande. ElevenAgents est utilisé par 1 000 000 de créateurs et d’entreprises leaders, preuve de la capacité de la plateforme à déployer à grande échelle sans compromis sur la performance.
Comment mesurer le MOS pour les agents vocaux (étape par étape)
Si vous souhaitez mesurer le MOS manuellement, il vous faudra un large panel d’auditeurs humains et une sélection d’extraits audio issus de vraies conversations. C’est un processus structuré qui implique de recueillir les avis, de faire la moyenne, puis d’interpréter les résultats.
Voici comment mesurer le MOS pour les agents vocaux en pratique :
- Préparez votre jeu de tests : Sélectionnez un échantillon représentatif de sorties audio de votre agent, avec au moins 100 extraits couvrant différents types de conversations.
- Lancez la session de notation : Demandez à vos auditeurs d’évaluer chaque extrait sur une échelle de 1 à 5 selon la qualité de l’expérience.
- Agrégerez les notes et calculez le score : Faites la moyenne des notes pour chaque extrait, puis la moyenne de tous les extraits pour obtenir le MOS global. Un MOS de 4,3 ou plus indique que votre agent vocal est prêt pour la production.
Même si ce processus est manuel, il vous donnera un MOS fiable pour votre agent. Pour tester à grande échelle, vous pouvez remplacer les auditeurs humains par des outils automatisés comme NISQA, qui prédisent le MOS de façon programmatique. Vous pouvez intégrer ces systèmes à vos pipelines pour surveiller le MOS en continu.
Benchmarks IA vs humain : FCR, AHT et CSAT
Calculer le MOS dans le temps permet de suivre l’évolution d’un modèle, mais vous pouvez ajouter du contexte en comparant avec la performance humaine. Voir ce que les humains réalisent dans des rôles similaires montre si votre agent vocal s’approche du niveau idéal.
Voici quelques indicateurs à prendre en compte pour comparer IA et humains.
Les agents IA doivent pouvoir égaler le FCR et le CSAT humains tout en améliorant nettement l’AHT. Cette amélioration vient du fait que les agents IA gèrent souvent des conversations plus générales que les agents humains. Beaucoup d’entreprises mettent en place un workflow où les agents IA sont les premiers interlocuteurs, puis transfèrent à un humain si la demande est trop complexe.
Les données 2025 de Poe, un agrégateur de comparaison IA, montrent que ElevenLabs a conservé la meilleure capacité globale à répondre aux demandes, avec 74,4 % de toutes les requêtes traitées. Ce succès se traduit par une adoption rapide, Eleven v3 et v2.5-Turbo représentant plus de 60 % des messages envoyés aux modèles IA au fil du temps.
Messages envoyés aux modèles IA dans le temps, ElevenLabs en tête du cadre d’évaluation Poe des agents vocaux
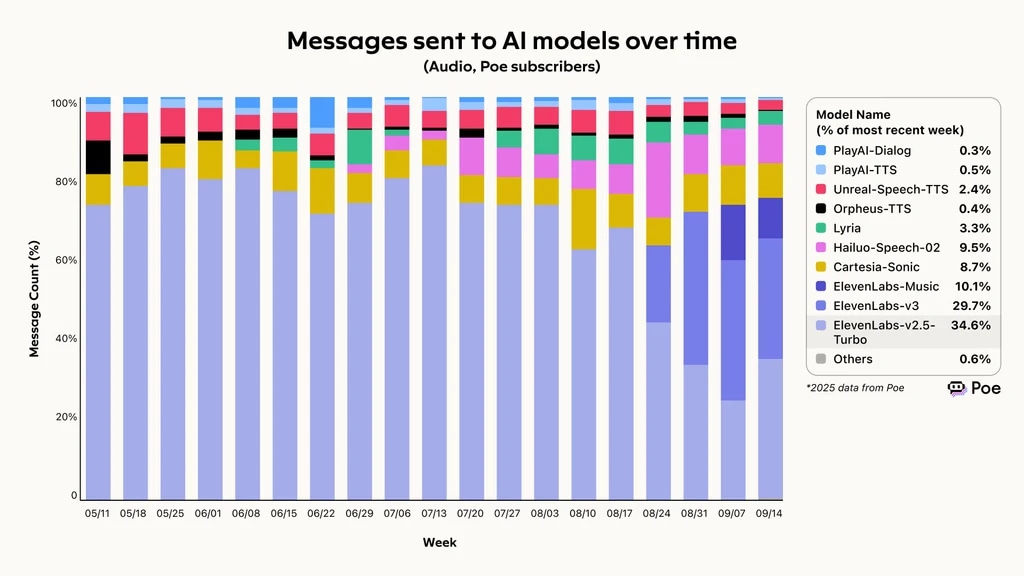
Messages envoyés aux modèles IA dans le temps, selon le benchmark Poe
Erreurs courantes lors des tests d’agents vocaux
Quand on suit un cadre d’évaluation, il est tentant de tester les scénarios idéaux. En réalité, l’expérience quotidienne des clients avec vos systèmes vocaux IA ne se déroule pas dans des conditions parfaites.
Voici trois erreurs courantes lors des tests d’agents vocaux et comment les corriger :
- Tester uniquement le chemin le plus facile : Surtout lors du choix des extraits audio pour le MOS, incluez des cas limites. Les extraits avec bruit de fond ou accent sont très fréquents en réalité, donc tester uniquement sur de l’audio « propre » fausse le MOS.
- Prioriser la rétention sur la résolution : Optimiser vos modèles pour garder les utilisateurs dans le système gonfle le taux de rétention sans améliorer les résultats. Si votre FCR est bas malgré un taux de rétention élevé, l’agent fait tourner les utilisateurs en rond. Prévoyez toujours la possibilité de parler à un humain si l’utilisateur le souhaite.
- Ignorer les percentiles de latence : Les SLA désignent souvent la latence au niveau P95. Ce chiffre est important pour garantir une expérience cohérente à la majorité, mais les 5 % restants sont aussi de vrais clients. À grande échelle, 5 % d’un système qui gère 10 000 appels par jour, c’est encore 500 personnes qui subissent une conversation lente. Faites du P99 votre objectif SLA principal, pas seulement la médiane ou le P95.
En gardant cela en tête, vous pouvez établir des références justes et représentatives, plutôt que de vous baser sur des moyennes idéalisées.
Pourquoi faire des évaluations spécifiques à chaque cas d’usage
Même si les six piliers de ce cadre donnent une direction, leur pondération dépend de votre secteur. Par exemple, une entreprise de services financiers privilégiera la conformité et l’utilisation des outils, tandis qu’une marque grand public misera sur la qualité de la voix TTS.
Voici deux exemples d’évaluations spécifiques à un cas d’usage et comment elles modifient l’équilibre des piliers.
Support client
Dans certains secteurs, comme les centres d’appels, d’autres indicateurs comme la résolution au premier appel (FCR) sont essentiels. Gérer un appel entrant sans intervention humaine réduit fortement la charge sur les agents humains.Selon McKinsey, les centres d’appels utilisant des agents vocaux peuvent réduire le volume d’interactions de 50 %.
Même si ce n’est pas aussi important que le taux de réussite des tâches, un autre indicateur à suivre est le taux de rétention. Il mesure la durée totale d’un appel. Si votre taux de rétention est élevé mais votre FCR bas, vos agents retiennent les clients sans résoudre leur problème. Cela peut vite devenir frustrant.
D’autres indicateurs à suivre sont l’AHT, les agents IA devant résoudre rapidement les problèmes courants. Le support client privilégiera donc la qualité de la conversation, notamment la gestion des tours de parole et le taux de fallback.
Santé
La santé est un secteur très réglementé, avec des exigences strictes qui rendent l’utilisation d’agents vocaux très délicate. La conformité est centrale, ce qui fait pencher le pilier sécurité du cadre vers cet aspect et l’intelligence avant tout.
Les chatbots santé doivent gérer la prise de rendez-vous, l’accès à la télémédecine, le triage des symptômes et les questions d’assurance. Tout cela exige beaucoup d’intelligence et une bonne utilisation des outils, ce qui montre encore que les besoins du secteur influencent le pilier le plus important.
Quel que soit votre secteur, comprendre les piliers de l’évaluation des agents vocaux et les appliquer de façon équilibrée vous aidera à trouver les meilleurs agents pour vous.
Construisez avec ElevenAgents pour des performances élevées et une faible latence
La plateforme sur laquelle vous développez influence directement la performance de vos agents vocaux en conditions réelles. Surtout face à vos clients, vous devez être sûr que votre agent excelle dans chaque catégorie.
ElevenAgents est conçu pour les déploiements vocaux en production, combinant le meilleur du TTS avec Eleven v3, le STT en temps réel grâce à Scribe v2, et une couche d’orchestration d’agents pensée pour l’échelle entreprise. Chaque composant est conçu pour répondre aux benchmarks de ce cadre, afin de garantir des expériences de qualité à vos clients.
Que vous soyez en phase de réflexion ou prêt à vous lancer, ElevenLabs a une solution pour vous. Découvrez la plateforme ElevenAgents pour voir comment elle s’adapte à votre cas d’usage, ou inscrivez-vous et commencez à créer dès aujourd’hui.




