Conoce Eleven v3.
Nuestro modelo de voz IA más expresivo.


Desarrollado por Eleven v3
Controla la emoción, la entrega y la dirección con etiquetas de audio
Crea voz controlable y expresiva con capas de emoción, eventos de audio y paisajes sonoros envolventes.

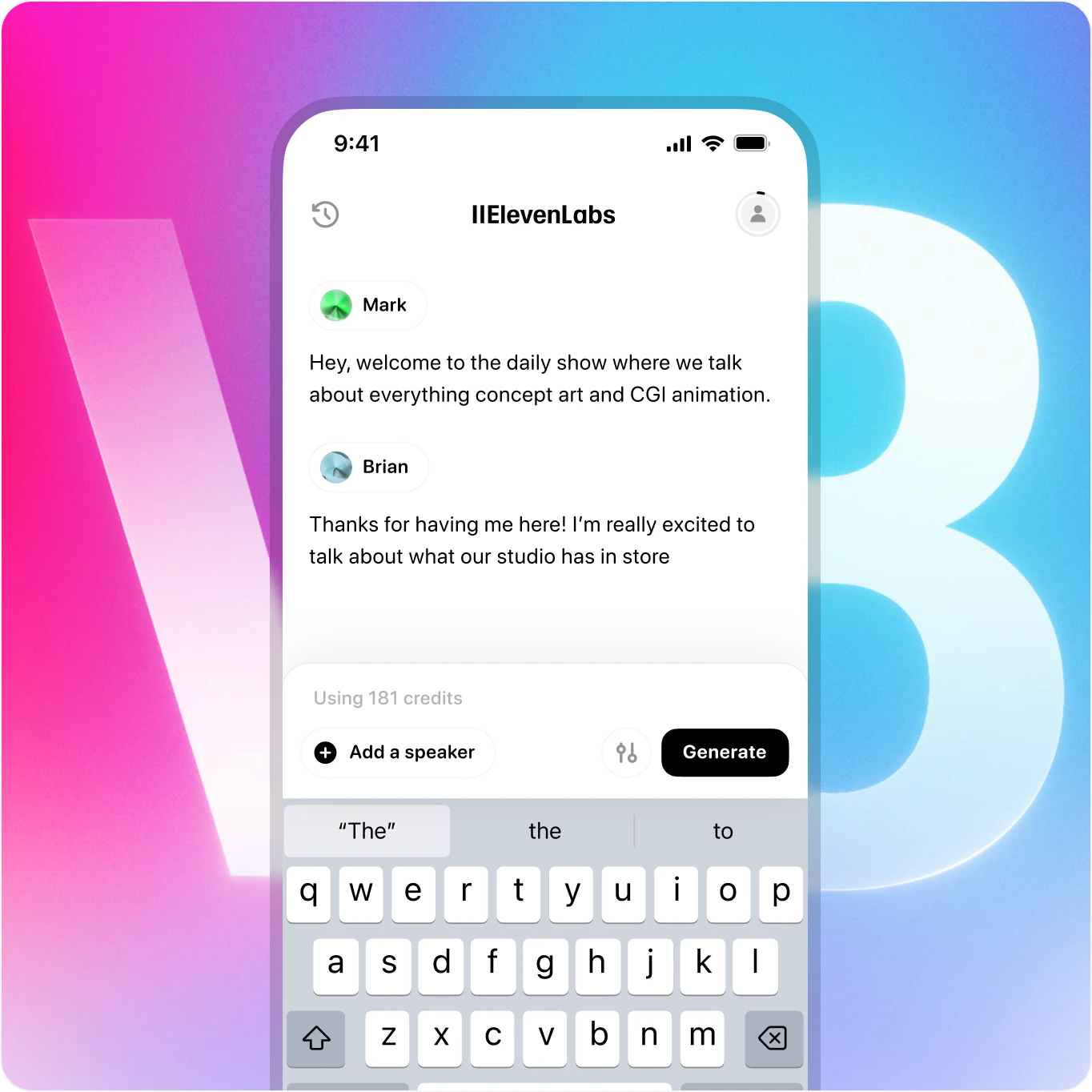
Genera conversaciones dinámicas entre múltiples hablantes
Crea conversaciones de audio donde los hablantes comparten contexto y emoción, haciendo que el diálogo generado suene natural y humano.

Lleva v3 a cualquier lugar - ahora disponible en móvil
Crea voces realistas con emociones intensas, todo desde tu teléfono. Nuestra voz IA ofrece un rendimiento de calidad de estudio desde cualquier lugar.
Voz similar a la humana en más de 70 idiomas
Llega a audiencias globales con voz expresiva y matizada en todos los idiomas principales.









Experimenta nuestro modelo más expresivo con profundidad emocional y una entrega rica.
Eleven v3 es diferente a otros modelos de ElevenLabs, ofreciendo un amplio rango dinámico controlado mediante etiquetas de audio en línea.
Crea con la API Eleven v3
Genera voz realista en más de 70 idiomas con emoción, dirección y control de múltiples hablantes usando etiquetas de audio en línea.

import { ElevenLabsClient, play } from '@elevenlabs/elevenlabs-js';
import 'dotenv/config';
const elevenlabs = new ElevenLabsClient();
const voiceId = 'JBFqnCBsd6RMkjVDRZzb';
const audio = await elevenlabs.textToSpeech.convert(voiceId, {
text: '[lentamente] En aquel entonces... [risas] no teníamos teléfonos.
[susurra] Solo caminos de tierra y [tose] grandes sueños. [triste] Luego sucedió',
modelId: 'eleven_v3',
outputFormat: 'mp3_44100_128',
});
await play(audio);