
Finetunes Music API, da a tus usuarios una identidad sonora única
- Categoría
- Producto
- Fecha
Scribe v2 es el modelo de Texto a Voz más preciso. Scribe v2 Realtime establece el estándar para transcripciones en vivo, potenciando agentes y aplicaciones en tiempo real. Ambos disponibles vía API.


Scribe v2 Realtime captura voz en vivo en menos de 150 ms con precisión excepcional, diseñado para agentes, reuniones y agentes de IA que requieren comprensión instantánea.
Scribe v2 Realtime ofrece precisión líder en la industria con latencia inferior a 150 ms, estableciendo un nuevo estándar para el reconocimiento de voz en tiempo real.
Detecta automáticamente cuándo comienza y termina el habla, segmentando con precisión para un procesamiento en vivo más fluido.
Ofreciendo una precisión excepcional en acentos, dialectos y condiciones de grabación.
Incorpora Scribe Realtime v2 en tus productos con la API. Con soporte de streaming completo y control de compromiso.


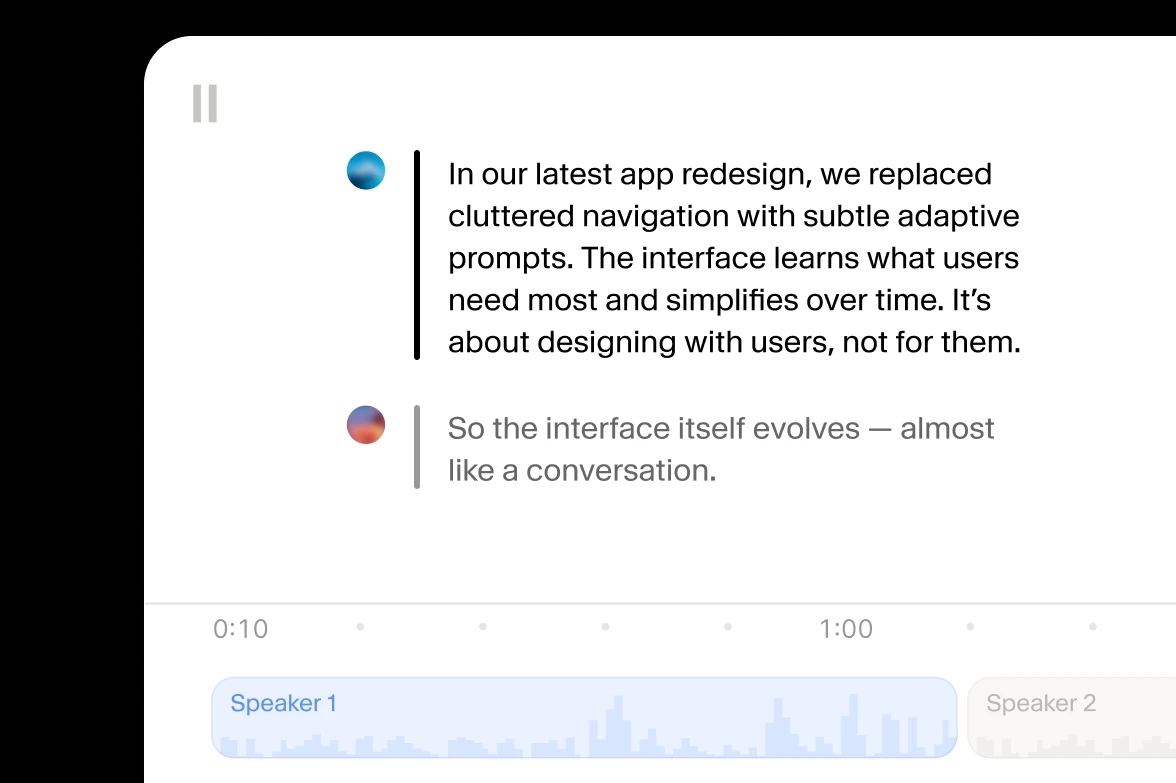
Sube audio o video en cualquier formato — MP4, MOV, MP3, WAV y más. Scribe v2 convierte automáticamente la voz en texto preciso, listo para subtítulos, captions o edición.
Scribe v2 logra una precisión líder en transcripción, entregando texto limpio y editable incluso en condiciones de audio desafiantes o con acentos diversos.
Selecciona hasta 1000 palabras o frases concretas para que Scribe las transcriba con precisión según el contexto.
Desde risas hasta pasos, Scribe v2 etiqueta cada evento sonoro, enriqueciendo tus transcripciones con todo el contexto.
Scribe v2 identifica y etiqueta de forma intuitiva a cada interlocutor, calcula los tiempos de cada entidad y oculta información sensible en las transcripciones.

Integra Scribe v2 y Scribe v2 Realtime en tu producto con la API o SDKs.

Habilita interacciones de voz en tiempo real con transcripción instantánea y de baja latencia.
.webp&w=3840&q=100)
Convierte grabaciones en texto editable, subtítulos y contenido reutilizable.
Nuestra transcripción de Texto a Voz con IA soporta más de 90 idiomas, solo selecciona el idioma y sube tu archivo de audio.














































































