
ElevenAgents Spotlight vorgestellt
- Kategorie
- Produkte
- Datum
Scribe v2 ist das genaueste Speech to Text-Modell. Scribe v2 Realtime setzt den Maßstab für Live-Transkriptionen – unterstützt Agenten und Echtzeitanwendungen. Beide über API verfügbar.


Scribe v2 Realtime erfasst Live-Sprache in unter 150 ms mit außergewöhnlicher Genauigkeit – entwickelt für Agenten, Meetings und KI-Agenten, die sofortiges Verständnis erfordern.
Scribe v2 Realtime liefert branchenführende Genauigkeit mit einer Latenz von unter 150 ms und setzt einen neuen Maßstab für die Echtzeit-Spracherkennung.
Erkennen Sie automatisch, wann Sprache beginnt und endet, und segmentieren Sie Sprache präzise für eine reibungslosere Live-Verarbeitung.
Bietet außergewöhnliche Genauigkeit über Akzente, Dialekte und Aufnahmebedingungen hinweg.
Integrieren Sie Scribe Realtime v2 in Ihre Produkte mit der API. Mit vollständiger Streaming-Unterstützung und Kontrollmöglichkeiten.


Laden Sie Audio oder Video in jedem Format hoch — MP4, MOV, MP3, WAV und mehr. Scribe v2 wandelt Sprache automatisch in präzisen Text um, bereit für Untertitel, Überschriften oder Bearbeitung.
Scribe v2 erreicht branchenführende Transkriptionsgenauigkeit und liefert sauberen, bearbeitbaren Text, selbst unter schwierigen Audio-Bedingungen oder bei unterschiedlichen Akzenten.
Wählen Sie bis zu 1000 bestimmte Wörter oder Sätze aus, die Scribe kontextbasiert präzise transkribiert.
Von Lachen bis zu Schritten, Scribe v2 kennzeichnet jedes Geräuschereignis und bereichert Ihre Transkripte mit dem vollständigen Kontext.
Scribe v2 erkennt und kennzeichnet intuitiv alle Sprecher, erstellt Zeitstempel für Entitäten und entfernt sensible Informationen aus Transkripten.

Integrieren Sie Scribe v2 und Scribe v2 Realtime in Ihr Produkt mit der API oder SDKs.

Ermöglichen Sie Echtzeit-Sprachinteraktionen mit sofortiger, latenzarmer Transkription.
.webp&w=3840&q=100)
Wandeln Sie Aufnahmen in bearbeitbaren Text, Untertitel und wiederverwendbare Inhalte um.
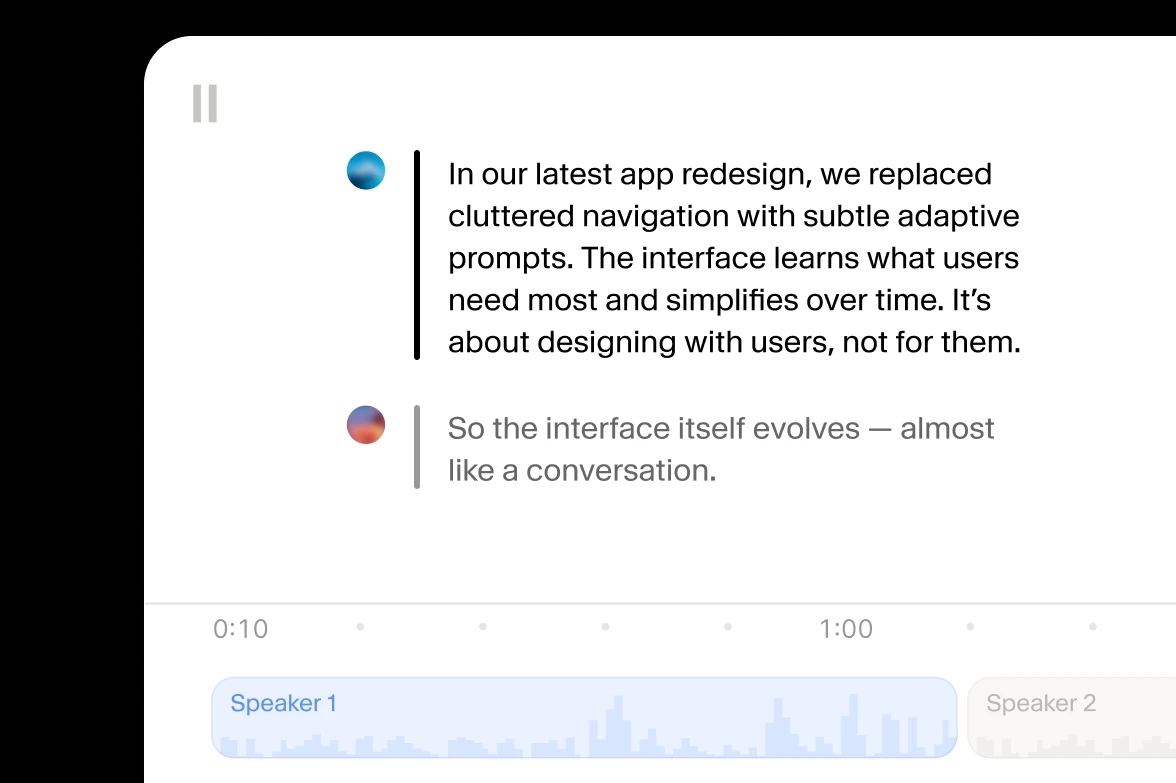
Unsere KI-Speech to Text-Transkription unterstützt über 90 Sprachen. Wählen Sie einfach die Sprache aus und laden Sie Ihre Audiodatei hoch.












































































.png&w=3840&q=80)
.png&w=3840&q=80)
