




























선거 강화 및 보호
- 카테고리
- 회사
- 날짜
Trusted by 1M+ users • Free to start

Create controllable, expressive speech layered with emotion, audio events, and immersive soundscapes.
음성이 잠시 멈췄다, [부드럽게] 생각을 정리하는 듯하다가 다시 이어갔다. 숨결 하나, 머뭇거림 하나까지 모두 의도적이고 완벽하게 타이밍이 맞았다.
이제 더 이상 합성 음성이 아니다 [따뜻하게 웃으며] - 타이밍, 감정, 단어 사이의 여백까지 이해하는 목소리였다.
텍스트가 존재감으로 변했다. [만족스럽게 한숨] 단어에 생명과 개성, 영혼이 담겼다.
Explore an ever-growing collection of expressive, lifelike voices for any use case - from narration to character creation.
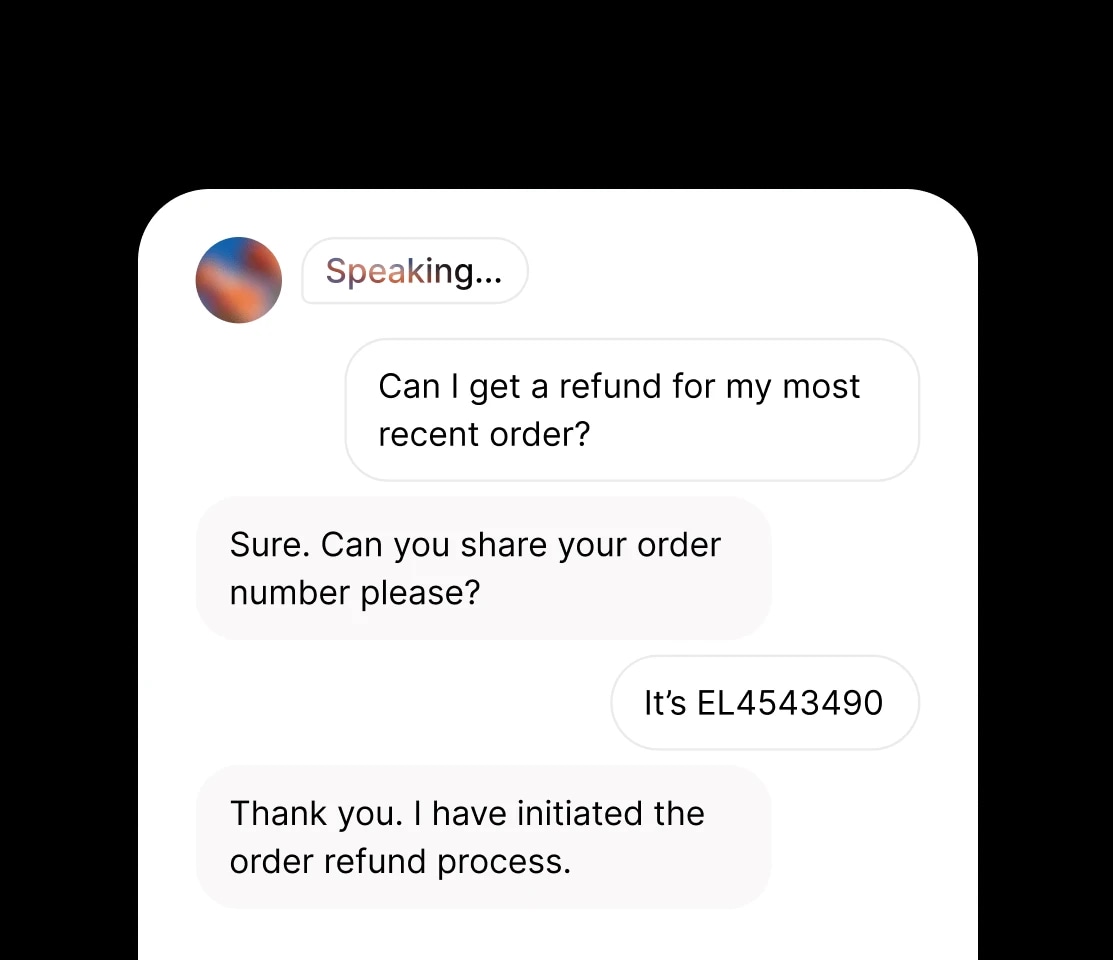
Create audio conversations where speakers share context and emotion.
Instantly replicate your own voice or craft unique AI Voices with full control.
Bring stories to life in over 70 languages, all with native-level emotion and clarity.

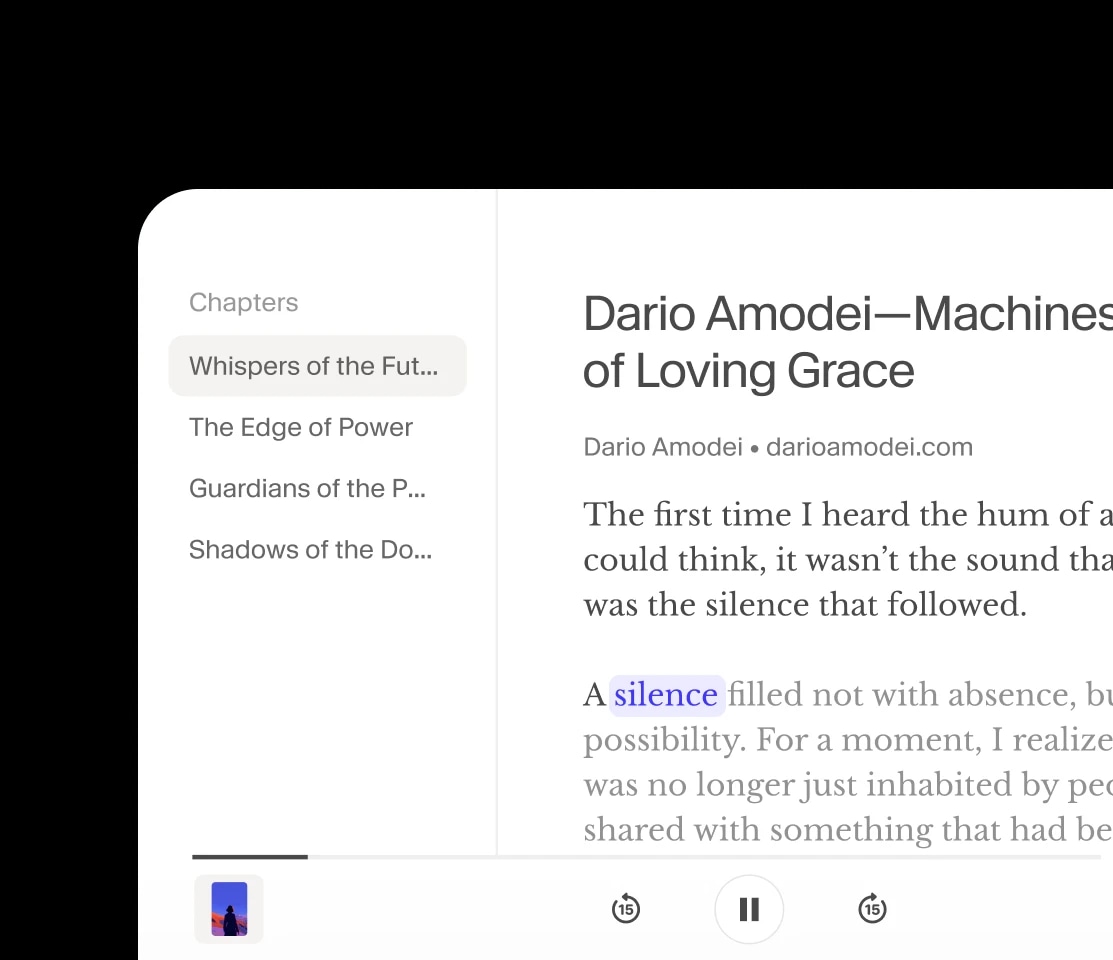

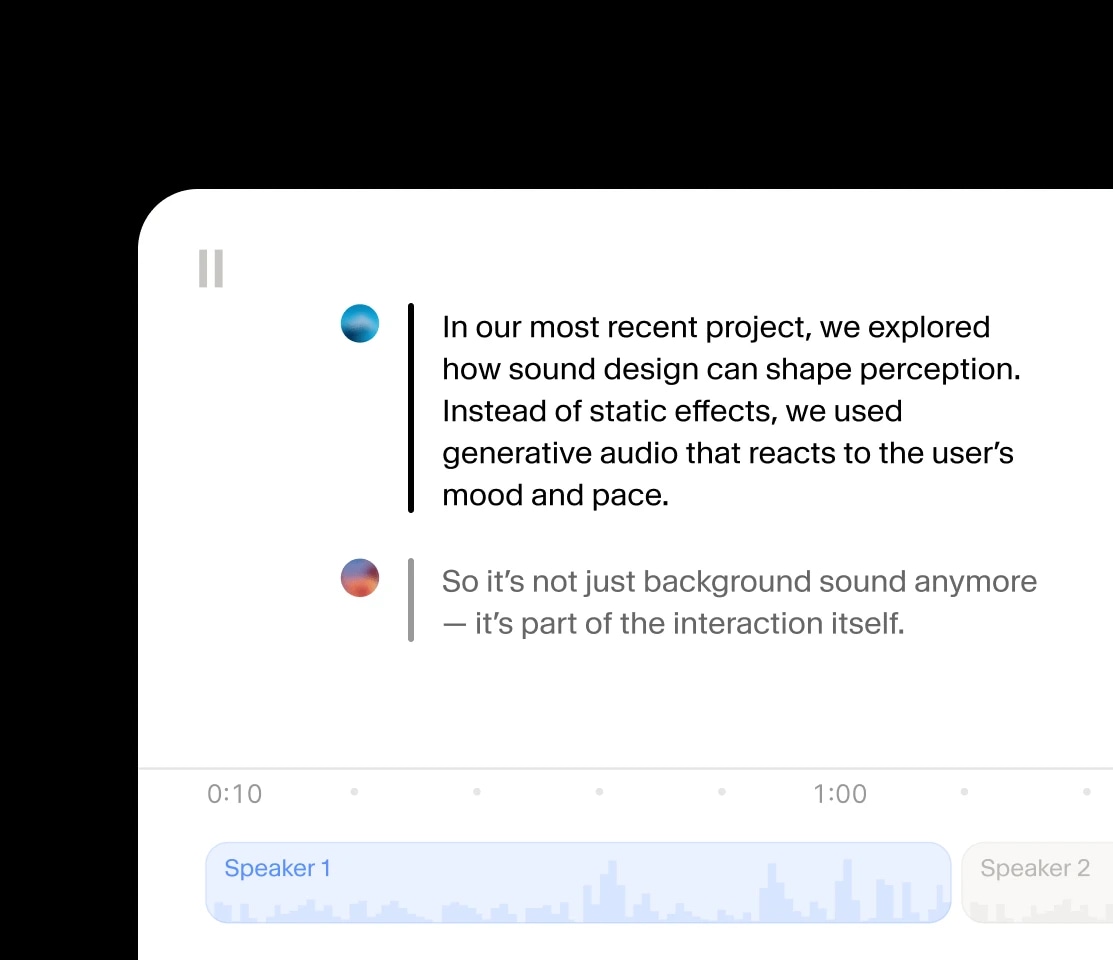

Our most advanced, expressive model with audio tags for precise emotional control. Best for storytelling, gaming and media production in 70+ languages.

Our most lifelike, emotionally rich text to speech model supporting 29 languages. Best for voiceovers, audiobooks, post-production and content creation.

Our high quality, low latency TTS model in 32 languages. Best for developer use cases where speed matters and you need non-English languages

High quality, low-latency model with a good balance of quality and speed

The best AI audio models in one powerful editor.

Generate expressive audio in seconds using our iOS and Android apps.
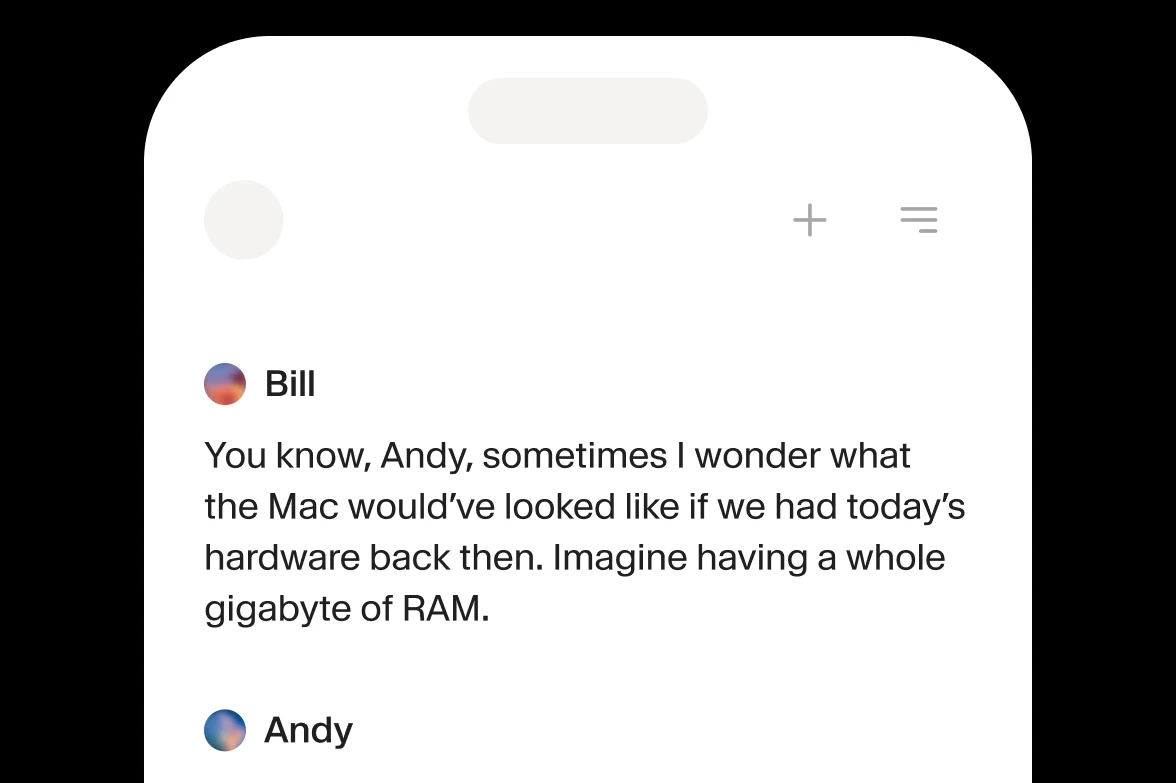
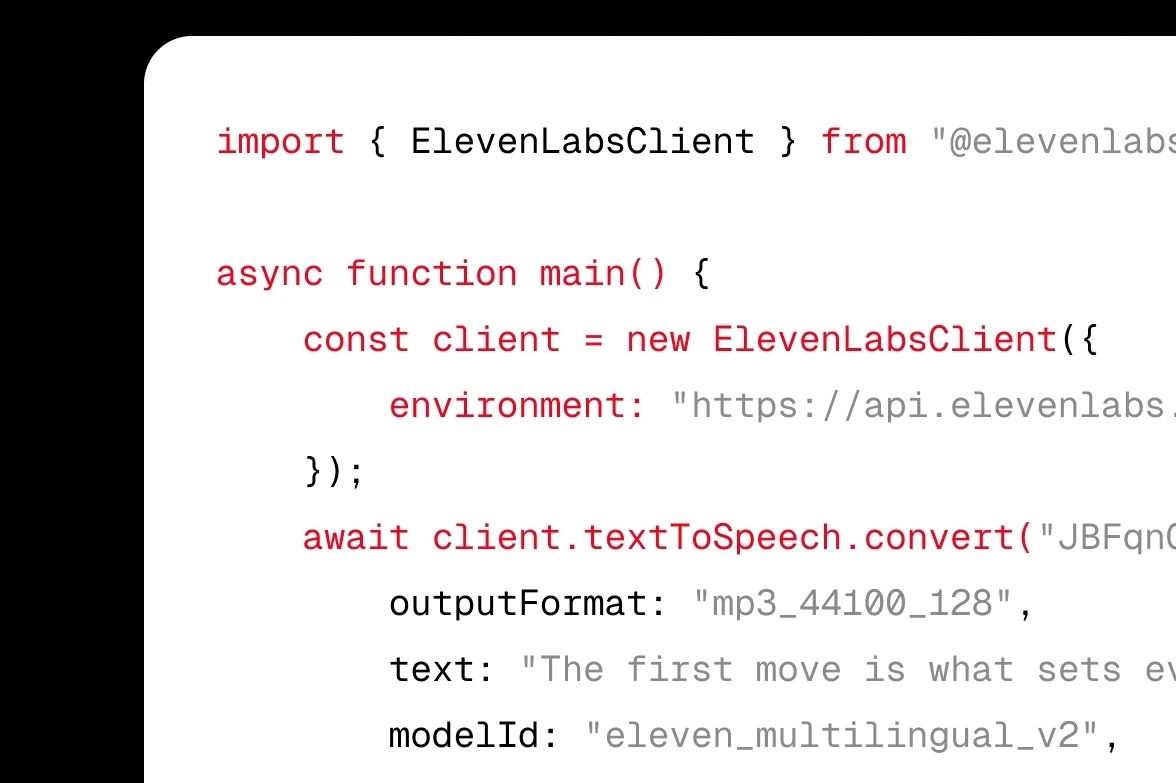
Integrate ElevenLabs Text to Speech (TTS) into your product via APIs or SDKs.
.png&w=3840&q=80)

.jpg&w=3840&q=80)

.jpg&w=3840&q=80)


.png&w=3840&q=80)
