मिलिए Eleven v3 से।
हमारा सबसे अभिव्यक्तिपूर्ण AI वॉइस मॉडल।


294/1000
Eleven v3 द्वारा संचालित
भावना, प्रस्तुति और दिशा को ऑडियो टैग्स के साथ नियंत्रित करें
भावनाओं, ऑडियो घटनाओं और इमर्सिव साउंडस्केप्स के साथ परतदार, अभिव्यक्तिपूर्ण स्पीच बनाएं।

कई वक्ताओं के बीच गतिशील वार्तालाप उत्पन्न करें
ऑडियो वार्तालाप बनाएं जहां वक्ता संदर्भ और भावना साझा करते हैं, जिससे उत्पन्न संवाद प्राकृतिक और मानवीय लगता है।

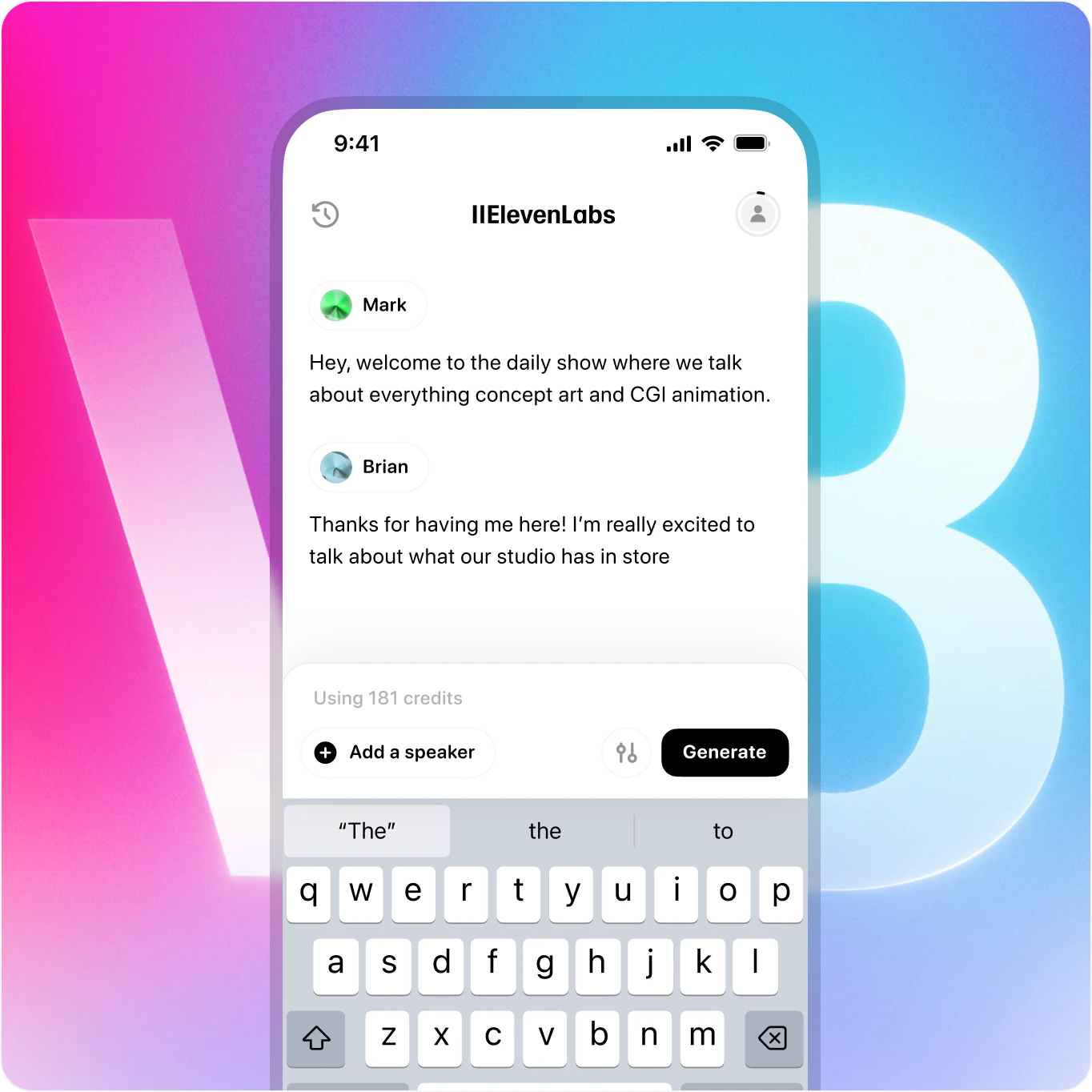
v3 को कहीं भी ले जाएं - अब मोबाइल पर उपलब्ध
अपने फोन से ही समृद्ध भावनाओं के साथ जीवंत भाषण बनाएं। हमारी वॉइस AI कहीं से भी स्टूडियो-गुणवत्ता का प्रदर्शन देती है।
70+ भाषाओं में मानव जैसी स्पीच
प्रत्येक प्रमुख भाषा में अभिव्यक्तिपूर्ण और सूक्ष्म स्पीच के साथ वैश्विक दर्शकों तक पहुंचें।

अंग्रेज़ी

चीनी

स्पेनिश

फ्रेंच

पुर्तगाली

जर्मन

जापानी

इटालियन

हिंदी
हमारे सबसे अभिव्यक्तिपूर्ण मॉडल का अनुभव करें जिसमें भावनात्मक गहराई और समृद्ध प्रस्तुति है।
Eleven v3 अन्य ElevenLabs मॉडल्स से अलग है, जो इनलाइन ऑडियो टैग्स के माध्यम से एक विस्तृत डायनामिक रेंज प्रदान करता है।
कई वक्ता (संवाद मोड)
टैग समर्थन
भावनाओं, घटनाओं, समग्र दिशा, ताल का पूरा रेंज
मानक जैसी विराम, ब्रेक
भाषाएँ
70+
29
Eleven v3 API के साथ निर्माण करें
इनलाइन ऑडियो टैग्स का उपयोग करके 70+ भाषाओं में भावनाओं, दिशा और मल्टी-स्पीकर नियंत्रण के साथ जीवन्त भाषण उत्पन्न करें।

import { ElevenLabsClient, play } from '@elevenlabs/elevenlabs-js';
import 'dotenv/config';
const elevenlabs = new ElevenLabsClient();
const voiceId = 'JBFqnCBsd6RMkjVDRZzb';
const audio = await elevenlabs.textToSpeech.convert(voiceId, {
text: '[धीरे से] उस समय... [हँसते हुए] हमारे पास फोन नहीं थे।
[फुसफुसाते हुए] सिर्फ मिट्टी की सड़कें और [खांसते हुए] बड़े सपने। [दुखी] फिर यह हुआ',
modelId: 'eleven_v3',
outputFormat: 'mp3_44100_128',
});
await play(audio);