
References पेश कर रहे हैं: Music v2 के लिए साउंड कंट्रोल
- श्रेणी
- प्रोडक्ट
- तारीख
Scribe v2 सबसे सटीक स्पीच टू टेक्स्ट मॉडल है। Scribe v2 Realtime लाइव ट्रांसक्रिप्शन के लिए मानक स्थापित करता है - एजेंट्स और रियल-टाइम एप्लिकेशन्स को शक्ति देता है। दोनों API के माध्यम से उपलब्ध हैं।


Scribe v2 Realtime 150 ms से कम समय में लाइव स्पीच को पकड़ता है, एजेंट्स, मीटिंग्स और AI एजेंट्स के लिए बनाया गया है जो तुरंत समझ की मांग करते हैं।
Scribe v2 Realtime उद्योग-अग्रणी सटीकता के साथ 150 ms से कम विलंबता प्रदान करता है, रियल-टाइम स्पीच पहचान के लिए एक नया मानक स्थापित करता है।
स्वचालित रूप से पता लगाएं जब स्पीच शुरू और बंद होती है, सटीकता के साथ स्पीच को सेगमेंट करें ताकि लाइव प्रोसेसिंग स्मूथ हो सके।
उच्चारण, बोलियों और रिकॉर्डिंग स्थितियों में उत्कृष्ट सटीकता प्रदान करता है।
API के साथ Scribe Realtime v2 को अपने प्रोडक्ट्स में बनाएं। फुल-स्ट्रीमिंग सपोर्ट और कमिट कंट्रोल के साथ।


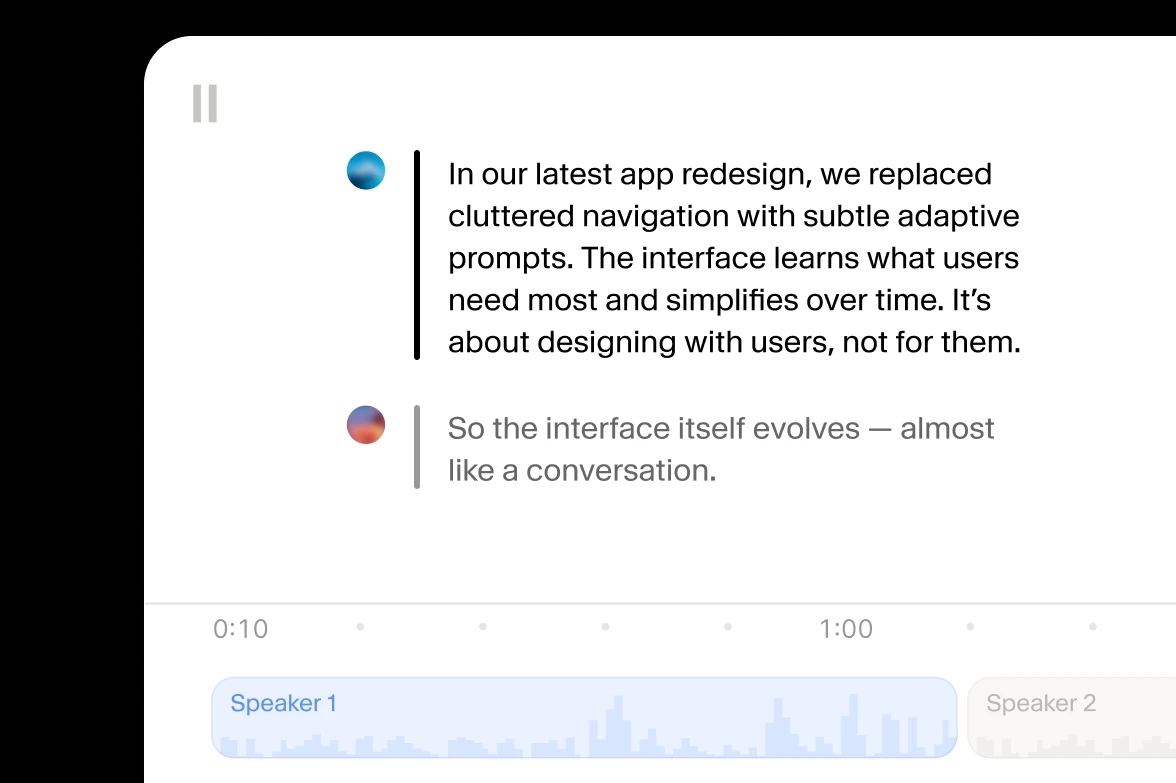
किसी भी फॉर्मेट में ऑडियो या वीडियो अपलोड करें — MP4, MOV, MP3, WAV, और अधिक। Scribe v2 स्वचालित रूप से स्पीच को सटीक टेक्स्ट में बदलता है, जो कैप्शन, सबटाइटल या एडिटिंग के लिए तैयार है।
Scribe v2 उद्योग-अग्रणी ट्रांसक्रिप्शन सटीकता प्राप्त करता है, चुनौतीपूर्ण ऑडियो स्थितियों या विविध उच्चारणों में भी साफ, एडिटेबल टेक्स्ट प्रदान करता है।
Scribe के लिए 1000 तक खास शब्द या वाक्य चुनें, ताकि वह संदर्भ के हिसाब से उन्हें सही-सही ट्रांसक्राइब कर सके।
हंसी से लेकर कदमों तक, Scribe v2 हर साउंड इवेंट को टैग करता है, आपके ट्रांसक्रिप्ट्स को पूर्ण संदर्भ के साथ समृद्ध करता है।
Scribe v2 हर स्पीकर को आसानी से पहचानता और लेबल करता है, एंटिटी के टाइमस्टैम्प निकालता है, और ट्रांसक्रिप्ट से संवेदनशील जानकारी हटा देता है।

API या SDKs के साथ Scribe v2 और Scribe v2 Realtime को अपने प्रोडक्ट में इंटीग्रेट करें।

तुरंत, कम विलंबता ट्रांसक्रिप्शन के साथ रियल-टाइम वॉइस इंटरैक्शन सक्षम करें।
.webp&w=3840&q=100)
रिकॉर्डिंग्स को एडिटेबल टेक्स्ट, कैप्शन और पुनः उपयोग योग्य सामग्री में बदलें।
हमारा AI स्पीच टू टेक्स्ट ट्रांसक्रिप्शन 90+ भाषाओं का समर्थन करता है, बस भाषा चुनें और अपनी ऑडियो फ़ाइल अपलोड करें।














































































