

























Découvrez ElevenMusic
- Catégorie
- Entreprise
- Date
Plus d'1 million d'utilisateurs nous font confiance • Essai gratuit



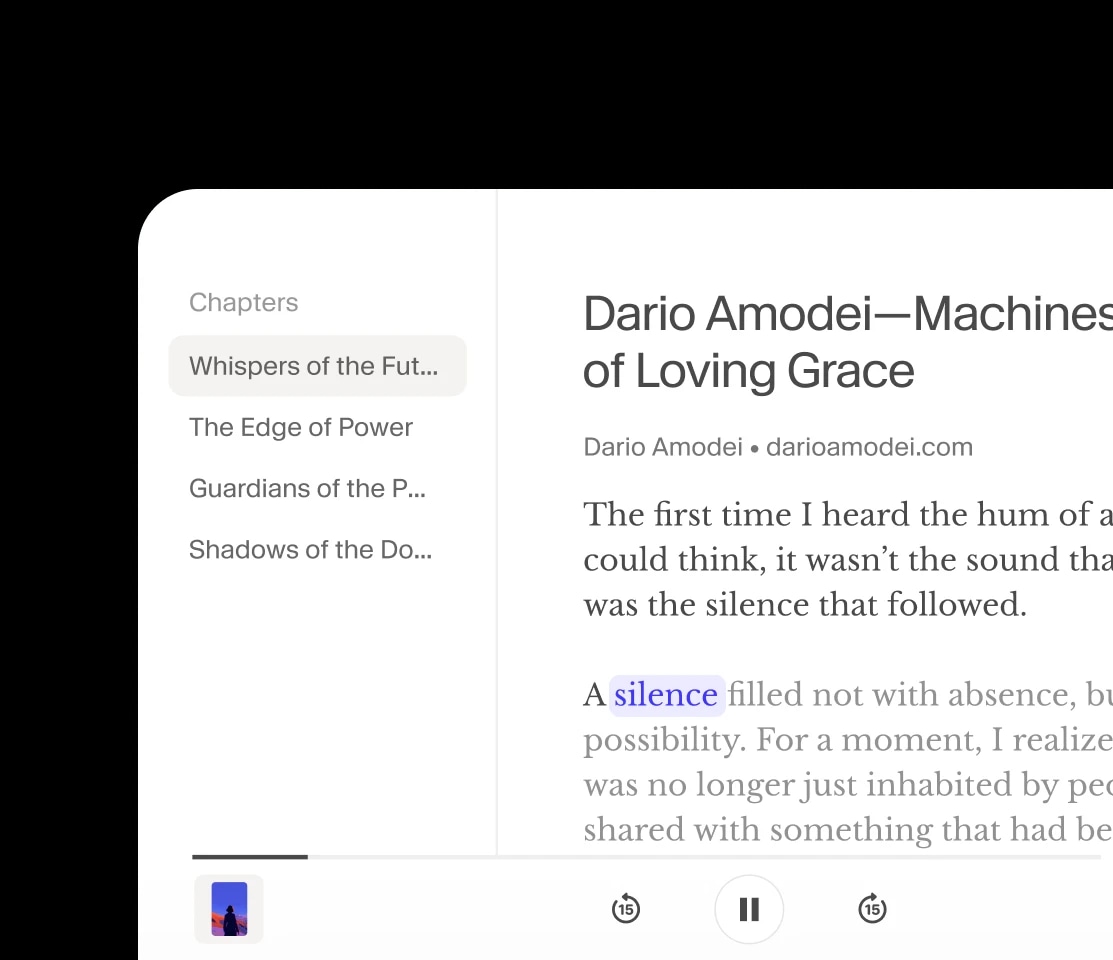
Narration
Des voix expressives qui donnent vie aux livres audio et podcasts
Publicité
Des voix convaincantes qui incitent à l’action et renforcent la mémorisation de la marque.
Personnages
Des voix ludiques et captivantes pour les dessins animés ou les jeux vidéo.
Narration
Des voix expressives qui donnent vie aux livres audio et podcasts
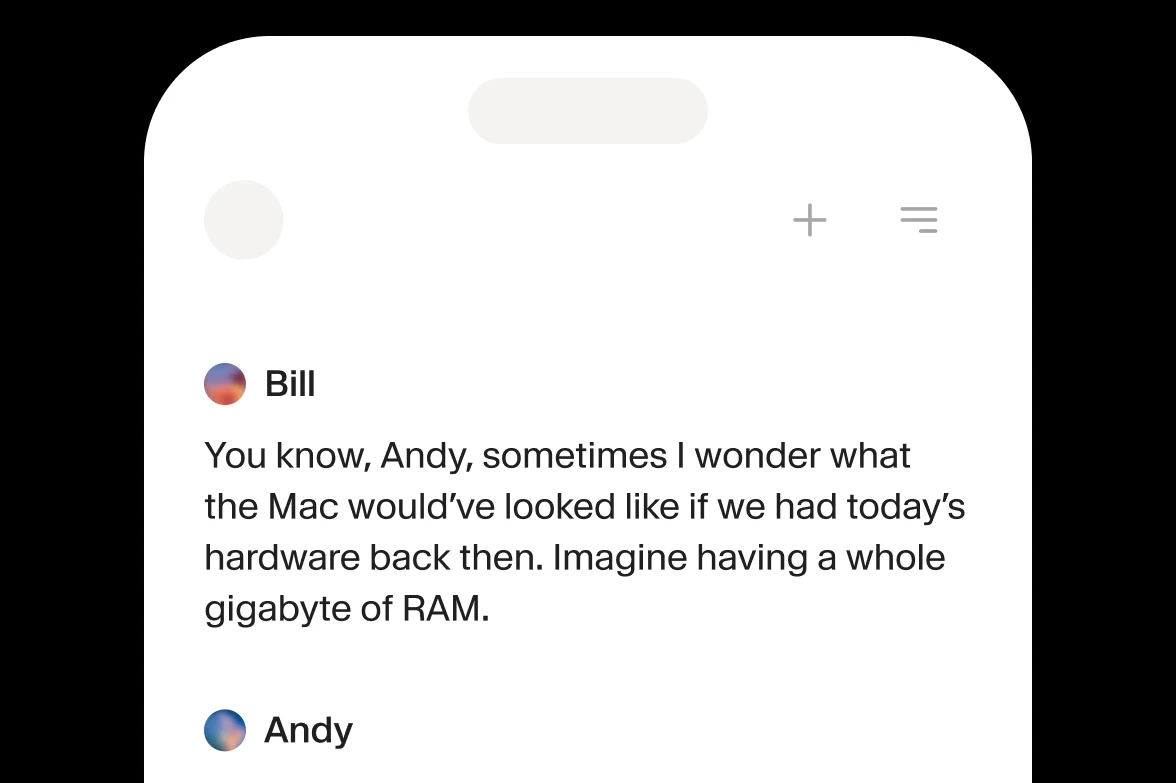
Conversationnel
Voix naturelles parfaites pour des scénarios informels.
Réseaux sociaux
Des voix tendance et accrocheuses pour du contenu court

La voix fit une pause un instant, [doucement] comme si elle rassemblait ses pensées avant de continuer. Chaque respiration semblait intentionnelle, chaque hésitation parfaitement synchronisée.
Ce n'était plus un discours synthétique [rit chaleureusement] - c'était une voix qui comprenait le timing, l'émotion et l'espace entre les mots.
Le texte s'est transformé en présence. [soupire avec satisfaction] Des mots animés, dotés de personnalité, d'âme.
Créez une parole expressive et contrôlable, enrichie d’émotions, d’événements audio et d’ambiances immersives.
Découvrez une collection grandissante de voix expressives et réalistes pour tous les usages, de la narration à la création de personnages.
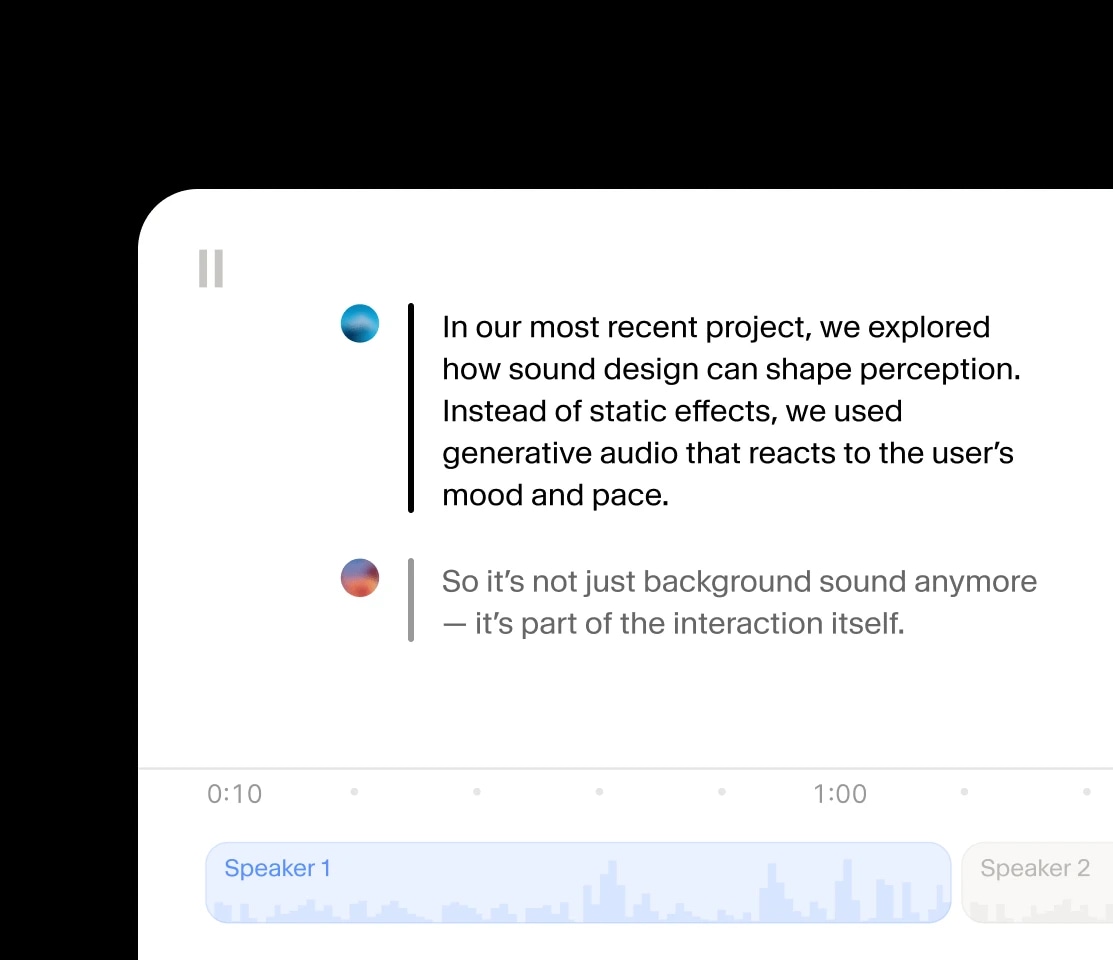
Créez des conversations audio où les intervenants partagent contexte et émotions.
Répliquez instantanément votre propre voix ou créez des voix IA uniques avec un contrôle total.
Donnez vie à vos histoires dans plus de 70 langues, avec émotion et clarté dignes d’un natif.
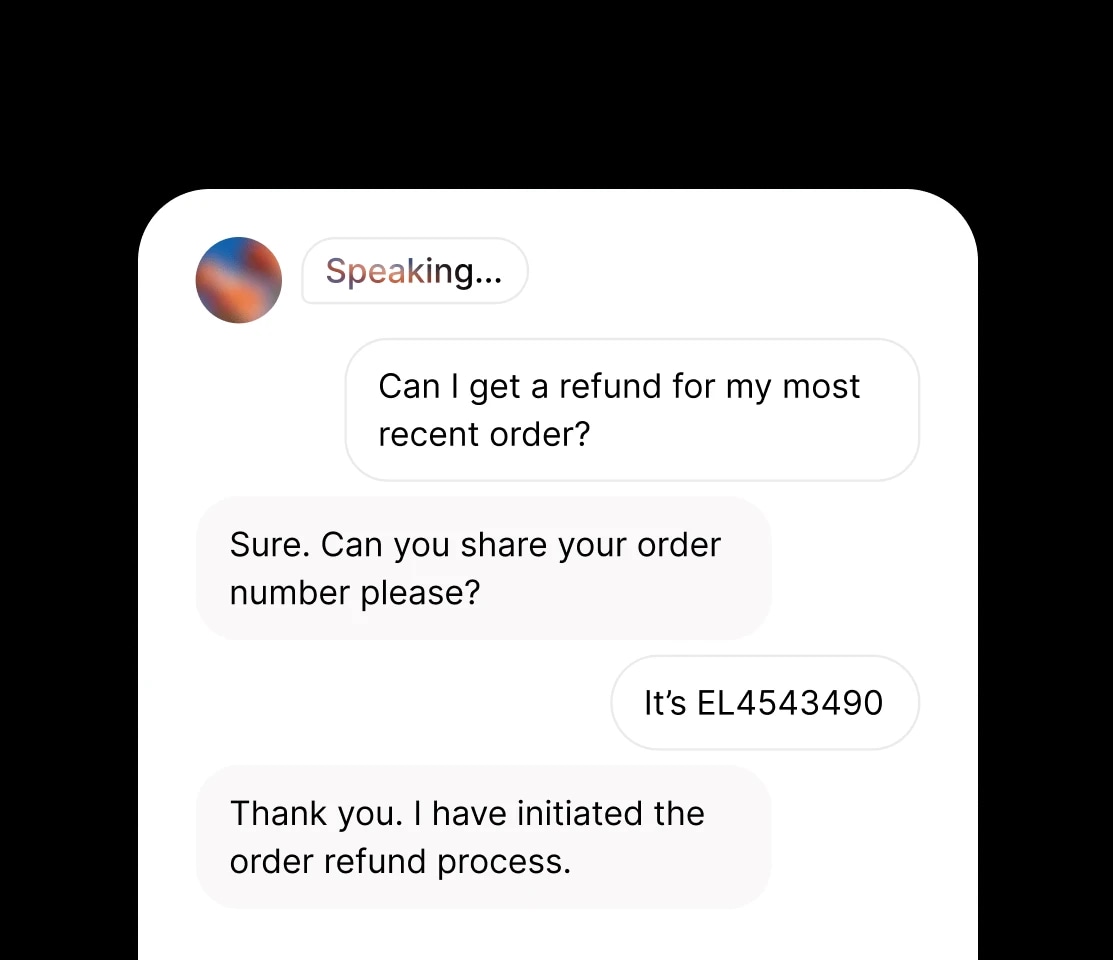



Notre modèle le plus avancé et expressif, avec balises audio pour un contrôle émotionnel précis. Idéal pour la narration, le jeu vidéo et la production média dans plus de 70 langues.

Notre modèle text to speech le plus réaliste et riche en émotions, compatible avec 29 langues. Parfait pour voix off, livres audio, post-production et création de contenu.

Notre modèle TTS de haute qualité et faible latence en 32 langues. Idéal pour les développeurs qui ont besoin de rapidité et de langues non-anglophones.

Modèle de haute qualité et faible latence, avec un bon équilibre entre qualité et rapidité

Les meilleurs modèles audio IA réunis dans un éditeur puissant.

Générez de l’audio expressif en quelques secondes avec nos applications iOS et Android.
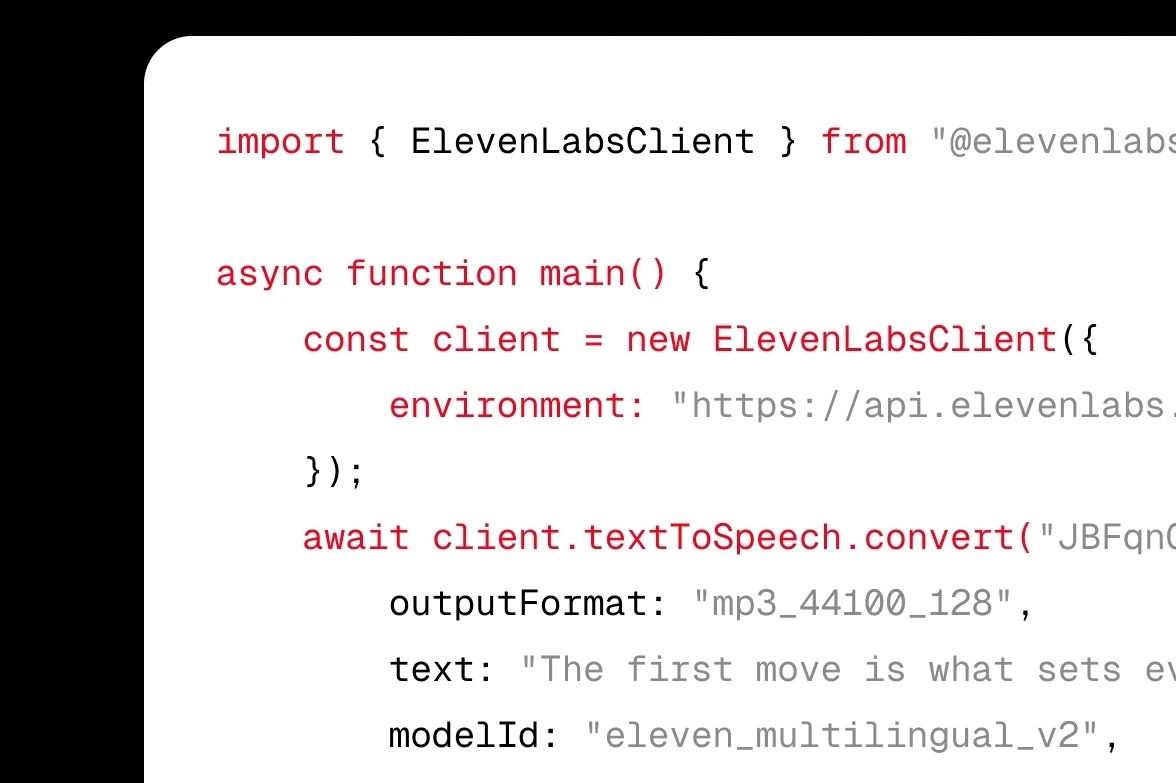
Intégrez ElevenLabs Text to Speech (TTS) à votre produit via API ou SDK.

%20(1).webp&w=3840&q=80)





