
























.webp&w=3840&q=80)
ElevenLabs colabora con el Gobierno del Reino Unido para llevar la voz IA a los servicios públicos y amplía su sede en Londres
- Categoría
- Empresa
- Fecha
Más de 1 millón de usuarios confían en nosotros • Empieza gratis



Narración
Voces expresivas que dan vida a audiolibros y pódcast
Anuncio
Voces persuasivas que inspiran acción y hacen que tu marca se recuerde.
Personajes
Voces divertidas y atractivas para dibujos animados o videojuegos.
Narración
Voces expresivas que dan vida a audiolibros y pódcast
Conversacional
Voces naturales perfectas para escenarios informales.
Redes sociales
Voces modernas y llamativas para contenido de formato corto

Crea voz expresiva y controlable, con emoción, eventos de audio y paisajes sonoros envolventes.
La voz hizo una pausa por un momento, [suavemente] como si estuviera reuniendo sus pensamientos antes de continuar. Cada respiración se sentía intencionada, cada vacilación perfectamente sincronizada.
Esto ya no era un discurso sintético [ríe cálidamente] - era una voz que entendía el ritmo, la emoción y el espacio entre las palabras.
El texto se transformó en presencia. [suspira satisfecho] Palabras con vida, personalidad, alma.
Explora una colección en constante crecimiento de voces realistas y expresivas para cualquier uso: desde narración hasta creación de personajes.
Crea conversaciones de audio donde los interlocutores comparten contexto y emociones.
Replica tu propia voz al instante o crea voces IA únicas con control total.
Da vida a tus historias en más de 70 idiomas, siempre con emoción y claridad nativas.
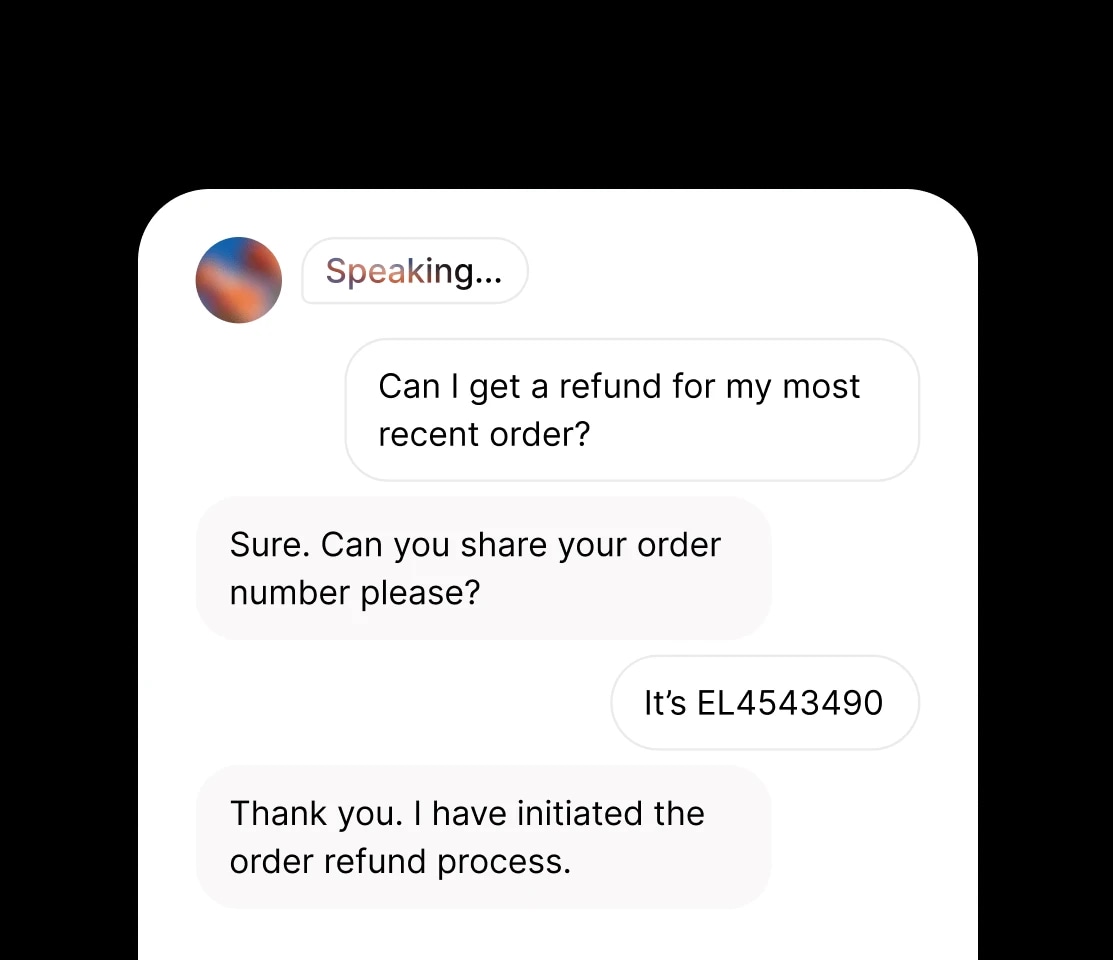



Nuestro modelo más avanzado y expresivo, con etiquetas de audio para controlar la emoción con precisión. Ideal para narración, gaming y producción en más de 70 idiomas.

Nuestro modelo de texto a voz más realista y emocional, con soporte para 29 idiomas. Perfecto para locuciones, audiolibros, postproducción y creación de contenido.

Modelo TTS de alta calidad y baja latencia en 32 idiomas. Ideal para desarrolladores que necesitan velocidad y soporte multilingüe.

Modelo de alta calidad y baja latencia, con buen equilibrio entre calidad y velocidad

Los mejores modelos de audio IA en un editor potente.

Genera audio expresivo en segundos con nuestras apps para iOS y Android.
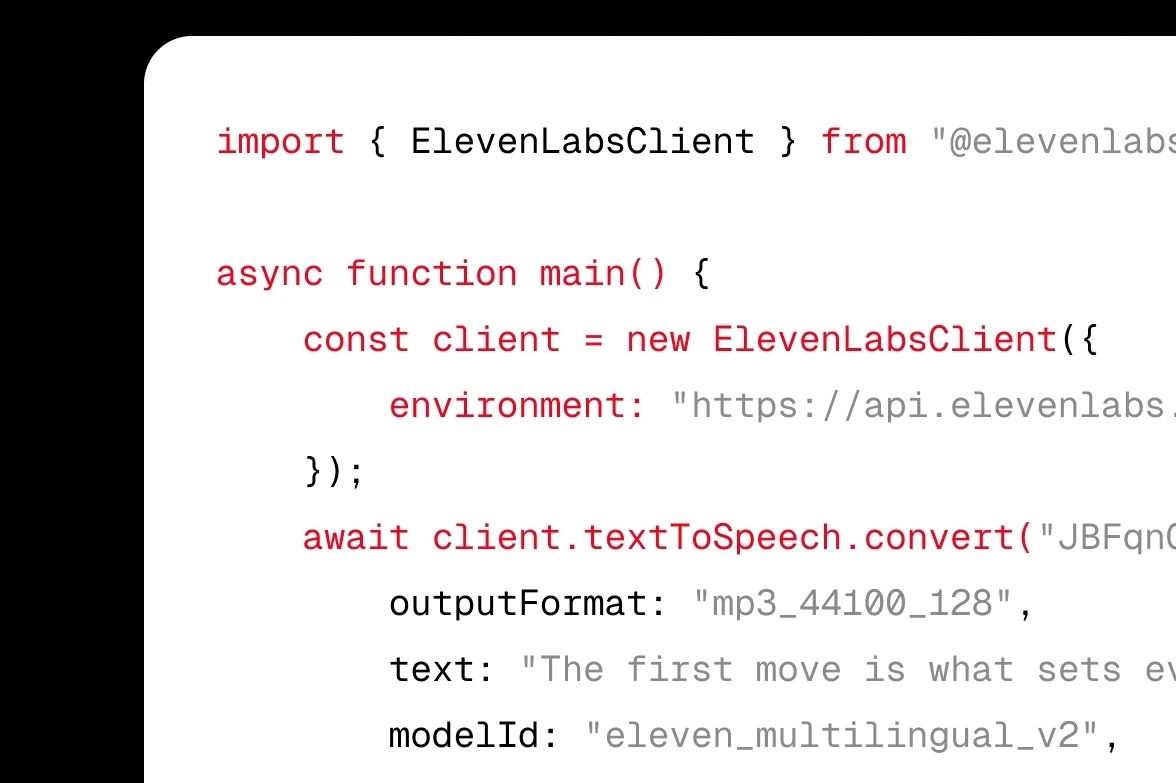
Integra Texto a Voz de ElevenLabs (TTS) en tu producto a través de API o SDK.




.webp&w=3840&q=80)
.webp&w=3840&q=80)
.webp&w=3840&q=80)
