Conheça o Eleven v3.
Nosso modelo de voz IA mais expressivo.


Desenvolvido por Eleven v3
Controle a emoção, entrega e direção com tags de áudio
Crie falas controláveis e expressivas, repletas de emoção, eventos de áudio e paisagens sonoras imersivas.

Gere conversas dinâmicas entre múltiplos falantes
Crie conversas em áudio onde os falantes compartilham contexto e emoção, fazendo com que o diálogo gerado soe natural e humano.

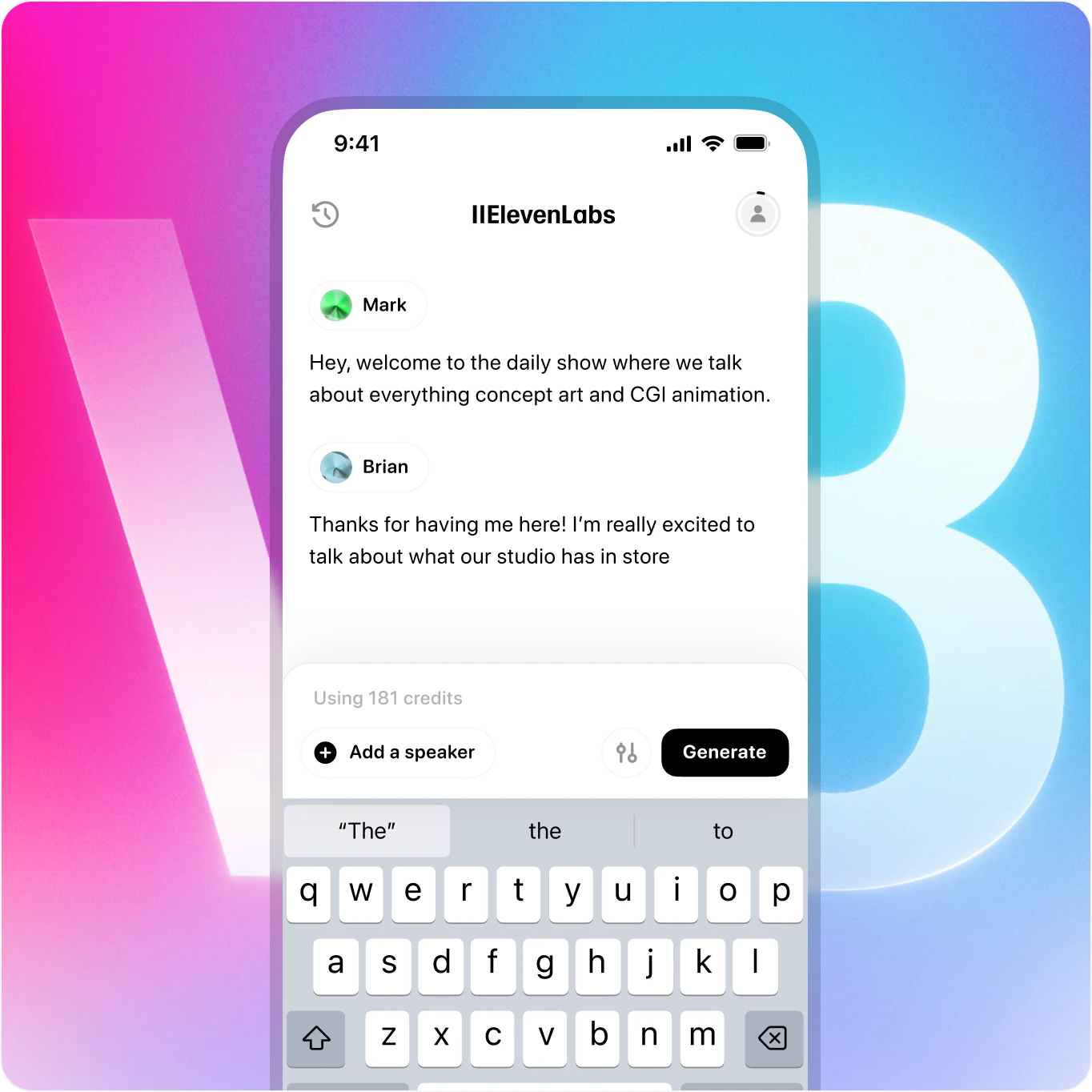
Leve o v3 para qualquer lugar - agora disponível no celular
Crie falas realistas com emoções ricas - tudo a partir do seu telefone. Nossa voz IA oferece desempenho de qualidade de estúdio de qualquer lugar.
Fala semelhante à humana em mais de 70 idiomas
Alcance audiências globais com fala expressiva e rica em nuances em todos os principais idiomas.









Experimente nosso modelo mais expressivo com profundidade emocional e entrega rica.
O Eleven v3 é diferente de outros modelos da ElevenLabs, oferecendo uma ampla gama dinâmica controlada por meio de tags de áudio embutidas.
Construa com a Eleven v3 API
Gere fala realista em mais de 70 idiomas com emoção, direção e controle de múltiplos falantes usando tags de áudio inline.

import { ElevenLabsClient, play } from '@elevenlabs/elevenlabs-js';
import 'dotenv/config';
const elevenlabs = new ElevenLabsClient();
const voiceId = 'JBFqnCBsd6RMkjVDRZzb';
const audio = await elevenlabs.textToSpeech.convert(voiceId, {
text: '[lentamente] Naquela época... [risos] não tínhamos telefones.
[sussurra] Apenas estradas de terra e [tosse] grandes sonhos. [triste] Então aconteceu',
modelId: 'eleven_v3',
outputFormat: 'mp3_44100_128',
});
await play(audio);