Marco de evaluación de agentes de voz: los 6 pilares explicados
- Escrito por
- Jack Limebear
- Publicado
- Última actualización
EscucharEscucha este artículo
Los agentes de voz tienen que coordinar varias herramientas casi al mismo tiempo. Es un equilibrio delicado: grabar los comentarios del cliente en tiempo real con
Con tantos elementos en juego, ¿cómo puedes evaluar con precisión el rendimiento de un agente de voz?
En este artículo, te proponemos un marco de evaluación de agentes de voz basado en seis pilares que define exactamente qué medir para valorar el éxito de un agente. También veremos por qué cada sector debe ponderar estos pilares de forma diferente y los errores más comunes al evaluar.
Resumen
- Los seis pilares principales para evaluar agentes de voz son: calidad de voz TTS, calidad de la conversación, uso de herramientas y finalización de tareas, inteligencia, cumplimiento y seguridad, y fiabilidad.
- Los objetivos clave en producción son un MOS de 4,3, un TSR superior al 85% y un tiempo hasta el primer audio inferior a 500 ms.
- Cada sector dará más peso a unos pilares que a otros, según el tipo de despliegue.
- Errores comunes en las pruebas incluyen evaluar solo audio limpio e ignorar picos de latencia P99.
- En ElevenLabs destacamos en las métricas más relevantes: Scribe v2 logra el WER más bajo del sector con un 2,2% (Artificial Analysis, junio 2026), Flash v2.5 y Turbo v2.5 son los modelos más rápidos (Artificial Analysis, junio 2026) y ElevenAgents ofrece una latencia de inferencia de modelo de ~75 ms.
¿Qué es un marco de evaluación de agentes de voz?
Un marco de evaluación de agentes de voz IA es un sistema estructurado que te permite probar el rendimiento en varias dimensiones. Un marco completo incluye métricas para valorar desde la fidelidad del audio hasta el flujo de la conversación e incluso el cumplimiento normativo.
A diferencia de un chatbot de texto, un agente de voz procesa cada interacción a través de al menos tres tecnologías apiladas: reconocimiento automático de voz (ASR), que convierte las palabras del usuario en texto; un LLM que genera la respuesta; y un sistema TTS que convierte esa respuesta en audio. Si falla cualquiera de estos sistemas, la experiencia se resiente.
Por eso las empresas deben evaluar los agentes de voz antes de elegir proveedor y desplegarlos. Cualquier latencia extra o respuestas imprecisas pueden tener consecuencias reales, como pérdida de clientes o, en el peor de los casos, sanciones regulatorias y daños reputacionales.
Un marco de evaluación de agentes de voz utiliza referencias y datos medibles para definir si un agente es apto para ciertos casos de uso. Desde el punto de vista empresarial, poder comparar diferentes modelos de voz te permite elegir el mejor para tus clientes.
Los seis pilares que debes evaluar en un agente de voz
Aunque crear y desplegar un agente IA nunca ha sido tan sencillo, los procesos internos son bastante complejos. Hay varios componentes que actúan a la vez para escuchar al usuario, entender lo que quiere, enviar esa información a un LLM y luego generar una respuesta en audio, todo casi al mismo tiempo.
Si quieres trabajar con el mejor agente de voz posible, necesitas un marco riguroso para comparar.
Si te interesa más ver los resultados de las pruebas, Análisis Artificial ofrece varias comparativas de agentes según diferentes componentes. Aquí puedes ver los resultados de su comparativa de velocidad entre modelos, donde ElevenLabs Turbo v2.5 y Flash v2.5 lideran con diferencia en caracteres procesados por segundo.
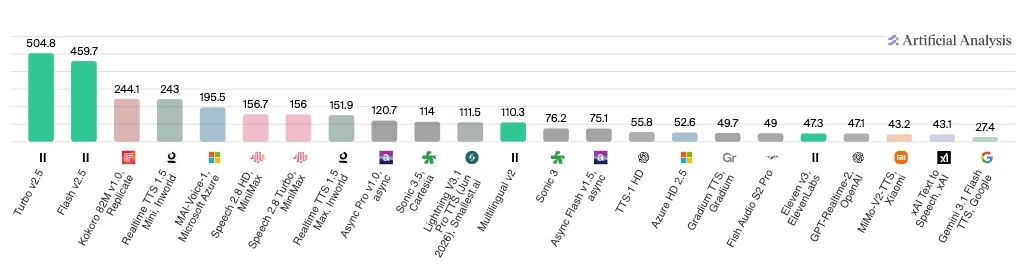
Si eres desarrollador o empresa y quieres hacer tus propios experimentos, estos son los seis pilares que debes usar para evaluar un agente IA:
- Calidad de voz TTS: Qué tan natural, clara y expresiva suena la voz sintetizada para los usuarios finales. Los mejores modelos del sector, como Eleven v3, ofrecen entonación humana y emotiva en más de 70 idiomas.
- Calidad de la conversación: ¿El modelo entiende el habla humana, interpreta el significado y responde en contexto de forma ágil en varias intervenciones?
- Uso de herramientas: Hasta qué punto un agente IA completa tareas usando los recursos disponibles sin intervención humana.
- Inteligencia: Cómo razona el modelo, gestiona entradas nuevas y evita respuestas inexactas o inventadas.
- Cumplimiento y seguridad: Además de todas las funciones,
- Fiabilidad: Componentes como el tiempo total en funcionamiento y el rendimiento constante bajo carga determinan si un agente de IA conversacional puede escalar según la demanda.
Aunque cada pilar es independiente, todos se conectan para ofrecer una experiencia final de calidad al usuario. Por ejemplo, si un modelo mejora la calidad de voz pero sigue teniendo mucha latencia, el cliente experimentará esperas incómodas antes de escuchar la respuesta.
Vamos a ver cada uno de estos pilares de evaluación de voz IA en detalle.
Calidad de voz TTS
Empezamos por la calidad de voz, ya que suele ser lo primero que nota una persona al interactuar con un agente conversacional IA. Si suena robótico o poco natural, la experiencia subjetiva será mucho peor.
Una de las métricas originales de evaluación, definida por la Unión Internacional de Telecomunicaciones (ITU-T), es el Mean Opinion Score (MOS). El MOS va de 1 a 5, donde 1 es inutilizable y 5 es excelente. Como es una medida subjetiva, se basa en oyentes humanos que dan su opinión tras una llamada.
Cualquier puntuación por debajo de MOS 3,5 es poco destacable, sobre todo hoy en día, y probablemente afectará a la satisfacción del cliente.
Aunque el MOS es la métrica principal para humanos, hay varios requisitos técnicos que influyen en esa puntuación:
- Consistencia de tono y jitter: El tono y el jitter son dos elementos lingüísticos que los humanos perciben de forma natural. El “tono” es la entonación que cambia a lo largo del discurso, como cuando subes la voz al hacer una pregunta. El jitter es cuando el modelo de voz no mantiene una prosodia coherente en una frase. El estándar del sector para jitter es 30 ms.
- Expresividad emocional: Una voz clara y precisa sigue sonando mal si el tono no encaja con la emoción de la frase. Sin señales tonales precisas, los oyentes tendrán menos conexión con los agentes conversacionales IA y los valorarán peor. ElevenAgents ofrece expresividad casi humana para que cada respuesta tenga una intención emocional clara.
- Ruido de fondo: El ruido de fondo en los agentes de voz tiene dos dimensiones que conviene evaluar. En la salida, se puede añadir ruido ambiente para que el agente suene más natural. En la entrada, el filtrado de ruido en la capa STT es una opción que mejora la precisión. Al evaluar un agente, prueba ambas: escucha si el ruido ambiente suena natural y comprueba la precisión del STT con y sin filtro de ruido.
Al calcular el MOS, deberías apuntar a 4,3-4,5, lo que demuestra puntuaciones altas en todas estas categorías perceptivas. Para predecir el MOS a escala sin paneles humanos, puedes usar herramientas como UTMOS y NISQA.
Calidad de la conversación
La calidad de la conversación es un pilar que conecta la calidad de voz con la finalización de tareas. Mide cómo de bien entiende el agente las necesidades del usuario, si sabe interrumpir en contexto y mantener un diálogo de varias intervenciones hasta completarlo.
La métrica principal aquí es la precisión en la clasificación de intenciones, que suele estar entre el 85% y el 92%, y los mejores modelos superan el 96%. Aunque 85% parece alto, sigue significando que el 15% del tráfico se clasifica mal y se deriva a recursos incorrectos.
Los elementos técnicos que contribuyen a una alta precisión en la clasificación de intenciones son:
- Gestión de turnos: La gestión de turnos mide cómo el agente de voz maneja el flujo natural de la conversación. Evalúa si sabe cuándo escuchar, responder o esperar más información. También incluye la gestión de interrupciones, donde el modelo cancela una respuesta en curso y genera una nueva según la nueva entrada. ElevenLabs utiliza un websocket multicontexto para gestionar estas interrupciones de forma fluida.
- Latencia: La latencia es el tiempo que pasa desde que el usuario termina de hablar hasta que el agente empieza a responder en audio. Los agentes de voz listos para producción deben tener un tiempo hasta el primer audio inferior a 500 ms, siendo menos de 300 ms lo ideal. Los modelos Flash de ElevenLabs ofrecen un tiempo de inferencia líder de ~75 ms, lo que te permite destacar en esta categoría.
- Tasa de fallback: La tasa de fallback mide cuántas veces el agente IA no entiende al usuario y pide aclaración o repetición. Suele depender de la precisión del STT: si la capa de reconocimiento de voz interpreta mal lo que dice el cliente, el LLM recibe una entrada errónea. La tasa de fallback se calcula así: Tasa de fallback (%) = (Número de fallbacks / Total de interacciones) * 100.
Scribe V2 de ElevenLabs tiene el WER más bajo: 2,2% en la evaluación de modelos voz a texto de Artificial Analysis
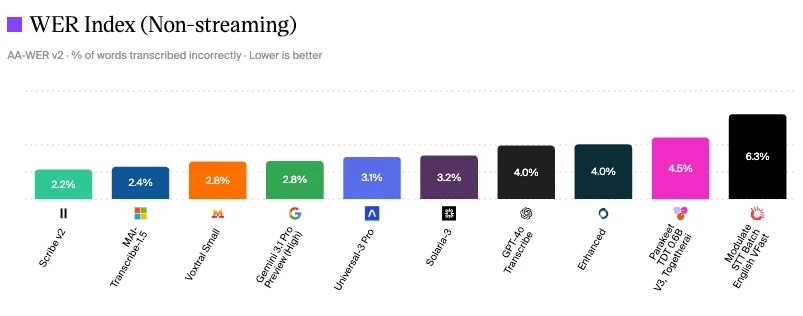
Evaluación de modelos voz a texto de Artificial Analysis
Una forma de medir la calidad de la conversación es consultar los estándares de referencia del sector para cada componente. Como puedes ver, Scribe v2 de ElevenLabs tiene el menor índice de error de palabra (WER) con un 2,2% en junio de 2026, lo que significa menos errores de escucha, menos fallbacks y una clasificación de intenciones más precisa.
Las empresas pueden ver que la calidad conversacional también depende del workflow en el que opera el agente de voz. Por ejemplo, en atención al cliente, también habría que valorar la calidad de la transferencia o la resolución de preguntas frecuentes.
Uso de herramientas y finalización de tareas
Mientras que la calidad mide cómo se sintió la conversación, la finalización de tareas mide si se logró el resultado deseado. Las empresas deben prestar especial atención a esta parte del marco de evaluación, ya que está directamente relacionada con los resultados de negocio.
Una forma de medir el uso de herramientas es la precisión en el llenado de campos (slot-fill), que indica si el agente IA puede completar tareas rutinarias, como rellenar un formulario con datos del cliente. Una alta precisión demuestra que el agente puede pasar de la conversación a la acción sin perder información.
La Tasa de Éxito de Tareas (TSR) es una métrica porcentual de las tareas completadas de principio a fin por el agente. Aquí se mide la capacidad del agente para entender la petición y usar las herramientas conectadas (APIs, bases de datos, RAG y bases de conocimiento internas) para ayudar.
La fórmula para el TSR es:
TSR = (Tareas completadas / Total de tareas intentadas) x 100
Los agentes de voz listos para producción deben apuntar a un TSR superior al 85%, monitorizando la precisión y fiabilidad en el uso de herramientas. Para evitar caídas en tu TSR, haz pruebas de regresión ante cualquier cambio en prompts o modelos conectados. Incluso una pequeña desviación puede tener consecuencias importantes.
Inteligencia
La inteligencia recoge la capacidad de razonamiento y funciones avanzadas de un agente de voz. Este pilar marca la diferencia entre un IVR tradicional y un agente de voz IA.
Las dimensiones clave a evaluar aquí son:
- Riesgo de alucinación: Las alucinaciones, cuando el agente da información incorrecta o incoherente con los documentos de la empresa, son especialmente problemáticas en voz IA porque pueden sonar muy convincentes.Estudios recientes indican que las alucinaciones frecuentes dañan mucho la satisfacción del cliente con los agentes de voz.
- Gestión de temas fuera de alcance: Los agentes inteligentes saben cuándo una pregunta está fuera de su dominio y responden de forma adecuada. En vez de inventar una respuesta, rechazan o redirigen la conversación a un terreno contextualizado.
- Retención de contexto: ¿Puede el agente seguir entidades y compromisos a lo largo de varias intervenciones? Sin esta capacidad, los clientes pueden tener que repetirse o recibir respuestas contradictorias.
- Razonamiento y lógica de varios pasos: ¿El agente gestiona correctamente lógica condicional o cadenas de inferencias en varias intervenciones? Esto es clave en casos técnicos, como servicios financieros, donde razonar en un contexto definido es esencial.
Existen varias referencias externas para estas dimensiones. Por ejemplo, la evaluación HELM de Stanford mide el rendimiento de LLM en distintas categorías. Para alucinaciones, TruthfulQA analiza con detalle la frecuencia de respuestas falsas.
Una ventaja de ElevenAgents es que, a diferencia de otras plataformas de voz que te obligan a usar un único modelo, puedes cambiar completamente la capa LLM. Así puedes elegir el modelo que mejor rinda en razonamiento para tu caso de uso.
Cumplimiento y seguridad
Las empresas deben implementar barreras activas para evitar respuestas dañinas o que incumplan políticas. A diferencia de las instrucciones de prompt a nivel de sistema, que pueden ser sorteadas, las comprobaciones independientes funcionan como una capa separada fuera del modelo. Evalúan las salidas antes de llegar al usuario y detienen la conversación si se desvía hacia temas peligrosos.
La auditabilidad es otro requisito: los agentes en producción deben mantener registros detallados de decisiones y salidas en un formato que permita revisiones posteriores. En sectores regulados, demostrar cumplimiento a posteriori es tan importante como cumplir desde el principio.
Las normativas concretas que debe cumplir tu empresa varían según el sector. Algunos de los marcos más habituales son:
- HIPAA: Para datos de salud protegidos en el sector sanitario de EE. UU.
- PCI-DSS: Para cualquier agente que gestione datos de tarjetas de pago.
- RGPD: Obligaciones de privacidad de datos para la UE y empresas con clientes en la UE.
Para empresas que evalúan su cumplimiento, ElevenLabs cuenta con certificación AICPA SOC Tipo II y cumple con RGPD, además de haber conseguido la certificación AIUC-1. La AIUC-1 es un estándar de seguridad diseñado específicamente para agentes IA.
Fiabilidad
La fiabilidad es el último pilar de nuestro marco de evaluación, y cubre si el agente puede responder de forma constante en tiempo real.
Al evaluar un agente de voz, fíjate en estas características:
- Disponibilidad: Cualquier despliegue de cara al cliente espera un 99,9% de disponibilidad para evitar caídas. Especialmente en casos de uso 24/7, como soporte entrante, la fiabilidad es clave.
- Degradación controlada: Por la complejidad interna de los agentes de voz, si un componente falla, el agente debe gestionar esa degradación de forma controlada. En la práctica, eso significa derivar a un humano en vez de seguir funcionando con errores o sobrecarga.
- Rendimiento bajo carga: Las pruebas de carga deben simular al menos el doble de tu pico esperado de concurrencia antes de salir a producción. Probar bajo presión permite detectar aumentos de latencia o caídas de rendimiento que solo aparecen a gran escala.
Incluso un modelo de alta calidad puede ser inutilizable si no escala con la demanda. ElevenAgents es la opción de confianza para 1.000.000 de creadores y empresas líderes, demostrando que la plataforma puede desplegarse a escala empresarial sin perder rendimiento.
Cómo medir el MOS en agentes de voz (paso a paso)
Si quieres medir el MOS manualmente, necesitarás un grupo grande de oyentes humanos y una selección de clips de audio de conversaciones reales. Es un proceso estructurado que implica recoger opiniones, promediar y analizar los datos.
Así puedes medir el MOS en la práctica:
- Prepara tu conjunto de pruebas: Selecciona una muestra representativa de salidas de audio de tu agente, con al menos 100 clips de distintas conversaciones.
- Realiza la sesión de valoración: Pide a los oyentes que puntúen cada clip del 1 al 5 según la calidad de la experiencia.
- Agrega y calcula las puntuaciones: Haz la media de las puntuaciones de cada clip y luego la media de todos los clips para obtener el MOS global. Un MOS de 4,3 o más indica que tu agente está listo para producción.
Aunque es un proceso manual, te dará un MOS fiable para tu agente de voz. Si quieres hacer la prueba a escala, puedes sustituir oyentes humanos por herramientas automáticas como NISQA, que predicen el MOS de forma programada. Puedes integrar estos sistemas en tus flujos activos para monitorizar el MOS de forma continua.
Comparativa de IA vs humanos: FCR, AHT y CSAT
Calcular el MOS de forma periódica sirve para ver mejoras o retrocesos en el modelo, pero puedes añadir contexto comparando con el rendimiento humano. Ver lo que logran los humanos en roles similares te ayuda a saber si tu agente de voz se acerca al nivel ideal.
Estas son algunas métricas a tener en cuenta en la comparativa IA vs humanos.
Los agentes IA deberían igualar el FCR y CSAT humanos, mejorando notablemente el AHT. Esta mejora se debe a que los agentes IA suelen gestionar conversaciones más generales que los humanos. Muchas empresas usan un workflow donde los agentes IA son la primera línea y solo pasan llamadas a humanos si son demasiado complejas.
Los datos de 2025 de Poe, un agregador de comparativas IA, muestran que ElevenLabs mantuvo la mayor capacidad global para resolver peticiones, completando el 74,4% de todas las solicitudes. Este éxito se traduce en un uso creciente, con Eleven v3 y v2.5-Turbo sumando más del 60% de los mensajes enviados a modelos IA a lo largo del tiempo.
Mensajes enviados a modelos IA a lo largo del tiempo, ElevenLabs liderando el marco de evaluación de agentes de voz de Poe
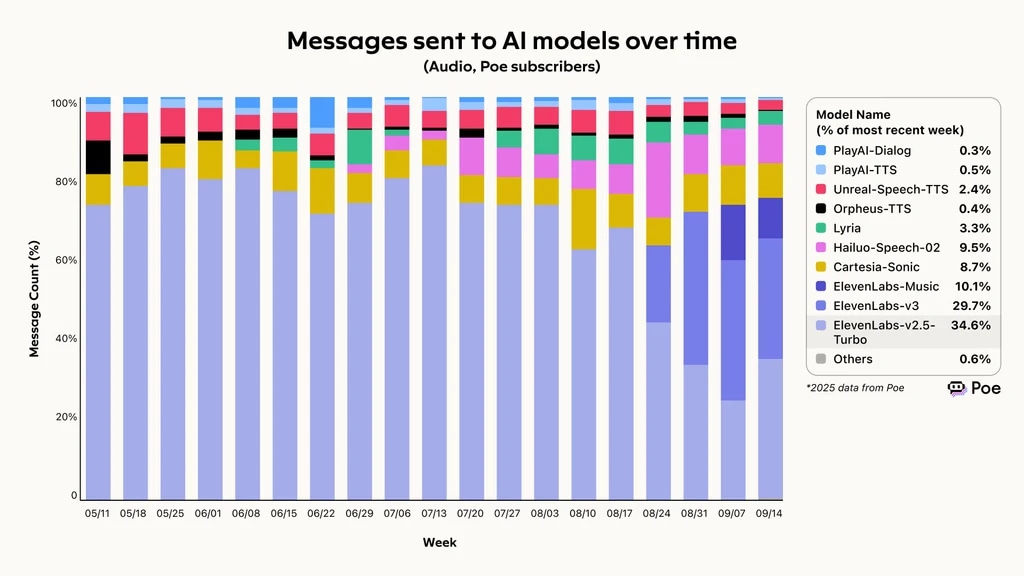
Mensajes enviados a modelos IA a lo largo del tiempo, según Poe
Errores comunes al probar agentes de voz
Al seguir un marco de evaluación de agentes de voz, es tentador probar solo los mejores casos. Pero la experiencia real de los clientes con tus sistemas de voz IA no se da en condiciones ideales.
Estos son tres errores comunes al probar agentes de voz y cómo solucionarlos:
- Probar solo el camino fácil: Especialmente al elegir clips de audio para el MOS, asegúrate de incluir casos límite. Los clips con ruido de fondo o acentos son muy habituales, así que probar solo con audio “limpio” hará que el MOS no refleje la realidad.
- Priorizar la contención sobre la resolución: Optimizar tus modelos para mantener a los usuarios dentro del sistema infla la tasa de contención sin mejorar los resultados. Si tu FCR es bajo pese a una alta contención, el agente está haciendo que los usuarios den vueltas sin resolver nada. Permite siempre que los usuarios puedan hablar con agentes humanos si lo desean.
- Ignorar los percentiles de latencia: Los SLA suelen fijar la latencia en el nivel P95. Aunque es importante para la mayoría de usuarios, no olvides que el 5% restante también son clientes reales. A escala, el 5% de un sistema que gestiona 10.000 llamadas diarias son 500 personas con una conversación lenta. Fíjate en el P99 como objetivo principal de SLA, no solo en la mediana o el P95.
Si tienes en cuenta estos puntos, podrás establecer referencias justas y representativas en vez de trabajar con medias idealizadas.
Por qué hacer evaluaciones específicas según el caso de uso
Aunque los seis pilares de este marco sirven de guía, el peso de cada uno depende del sector. Por ejemplo, una empresa de servicios financieros priorizará el cumplimiento y el uso de herramientas, mientras que una marca de consumo dará más importancia a la calidad de voz TTS.
Aquí tienes dos ejemplos de evaluaciones específicas y cómo pueden cambiar el peso de cada pilar.
Atención al cliente
En sectores como los call centers, otras métricas como la Resolución en la Primera Llamada (FCR) son clave. Poder gestionar una llamada entrante sin intervención humana reduce mucho la carga sobre los agentes humanos.Según McKinsey los call centers que usan agentes de voz pueden reducir el volumen de interacciones hasta un 50%.
Aunque no es tan importante como la tasa de éxito de tareas, otra métrica a considerar es la tasa de contención, que mide la duración total de la llamada. Si la contención es alta pero el FCR bajo, los agentes mantienen a la gente en línea sin resolver el problema, lo que genera frustración.
Otras métricas a seguir serían el AHT, con agentes IA que buscan resolver problemas rutinarios rápidamente. Por eso, en atención al cliente se prioriza la calidad de la conversación, sobre todo la gestión de turnos y la tasa de fallback.
Sanidad
Sanidad es un sector muy regulado, con requisitos estrictos que hacen que operar agentes de voz sea especialmente delicado. El cumplimiento es central, por lo que el peso del pilar de seguridad se desplaza claramente hacia este aspecto y la inteligencia.
Los chatbots de sanidad deben gestionar citas, acceso a telemedicina, triaje de síntomas y consultas sobre seguros. Todo esto requiere mucha inteligencia y uso de herramientas, lo que demuestra que las demandas del sector o rol influyen en qué pilar es más importante.
Sea cual sea tu sector, entender los pilares clave de la evaluación de agentes de voz y aplicarlos de forma equilibrada te ayudará a encontrar los mejores agentes para ti.
Crea con ElevenAgents para alto rendimiento y baja latencia
La plataforma que elijas influye directamente en cómo rinden tus agentes de voz en workflows reales. Especialmente al interactuar con tus clientes, necesitas la seguridad de que tu agente destacará en todas las categorías.
ElevenAgents está diseñado para despliegues de voz en producción, combinando TTS líder del sector con Eleven v3, STT en tiempo real con Scribe v2, y una capa de orquestación de agentes pensada para escala empresarial. Cada componente está diseñado para cumplir los benchmarks de este marco, permitiéndote ofrecer experiencias de calidad a tus clientes.
Tanto si estás valorando opciones como si quieres empezar ya, ElevenLabs tiene un camino para ti. Descubre la plataforma ElevenAgents para ver cómo se adapta a tu caso de uso, o regístrate y empieza a crear hoy mismo.


.webp&w=3840&q=80)
.webp&w=3840&q=80)
