Bewertungsrahmen für Sprachagenten: 6 Säulen erklärt
- Verfasst von
- Jack Limebear
- Veröffentlicht
- Zuletzt aktualisiert
AnhörenArtikel anhören
Voice Agents müssen eine Vielzahl nahezu gleichzeitig arbeitender Tools koordinieren. Es ist ein präzises Zusammenspiel aus dem Aufzeichnen von Kundenkommentaren mit Echtzeit-
Wie bewertet man bei so vielen Komponenten die Leistung eines Sprachagenten präzise?
In diesem Artikel stellen wir einen Bewertungsrahmen mit sechs Säulen für Sprachagenten vor, der genau beschreibt, was bei der Erfolgsmessung zu beachten ist. Außerdem gehen wir darauf ein, warum verschiedene Branchen die Säulen unterschiedlich gewichten sollten und welche typischen Fehler bei der Bewertung auftreten.
Übersicht
- Die sechs wichtigsten Säulen zur Bewertung von Sprachagenten sind TTS-Stimmqualität, Gesprächsqualität, Tool-Nutzung und Aufgabenabschluss, Intelligenz, Compliance und Sicherheit sowie Zuverlässigkeit.
- Die wichtigsten Produktionsziele sind ein MOS von 4,3, eine TSR über 85 % und eine Time-to-First-Audio unter 500 ms.
- Je nach Branche werden die einzelnen Säulen unterschiedlich gewichtet, bestimmte Einsätze bevorzugen einzelne Aspekte.
- Häufige Testfehler sind die ausschließliche Bewertung von sauberem Audio und das Ignorieren von P99-Latenzspitzen.
- ElevenLabs setzt Maßstäbe bei den wichtigsten Kennzahlen: Scribe v2 erreicht mit 2,2 % den niedrigsten WER im Feld (Artificial Analysis, Juni 2026), Flash v2.5 und Turbo v2.5 sind führend bei der Geschwindigkeit (Artificial Analysis, Juni 2026) und ElevenAgents liefern eine Modell-Inferenzlatenz von ~75 ms.
Was ist ein Bewertungsrahmen für Sprachagenten?
Ein Bewertungsrahmen für KI-Sprachagenten ist ein strukturiertes System, mit dem Sie die Leistung in mehreren Dimensionen testen können. Ein umfassender Rahmen enthält Kennzahlen zur Bewertung von Audioqualität, Gesprächsfluss bis hin zu regulatorischer Compliance.
Im Gegensatz zu einem Text-Chatbot durchläuft jede Interaktion bei einem Sprachagenten mindestens drei Technologien: automatische Spracherkennung (ASR), die gesprochene Worte in Text umwandelt; ein LLM, das eine Antwort generiert; und ein TTS-System, das die Antwort wieder in Audio umwandelt. Fällt eine dieser Komponenten aus, leidet das gesamte Nutzererlebnis.
Diese Komplexität ist der Grund, warum Unternehmen Sprachagenten vor der Auswahl und dem Einsatz bewerten müssen. Zusätzliche Latenz oder ungenaue Antworten können reale Folgen haben, wie Kundenabwanderung oder im schlimmsten Fall Bußgelder und Reputationsschäden.
Ein Bewertungsrahmen für Sprachagenten nutzt Benchmarks und messbare Daten, um zu definieren, ob ein Agent für bestimmte Anwendungsfälle geeignet ist. Aus Unternehmenssicht ermöglicht die Bewertung verschiedener Sprachmodelle die Auswahl des besten Modells für Ihre Kunden.
Die sechs Säulen zur Bewertung von Sprachagenten
Auch wenn die Erstellung und der Einsatz eines KI-Agenten heute einfacher denn je sind, laufen im Hintergrund komplexe Prozesse ab. Mehrere Komponenten arbeiten zusammen, um Nutzer zu verstehen, Informationen an ein LLM weiterzugeben und eine Audioantwort zu erzeugen – viele Aktionen laufen nahezu gleichzeitig ab.
Um mit dem besten Sprachagenten zusammenzuarbeiten, benötigen Unternehmen einen strengen Bewertungsrahmen.
Wenn Sie sich mehr für die Testergebnisse interessieren, dann bietet Künstliche Analyse verschiedene Agentenvergleiche auf Basis unterschiedlicher Komponenten. Unten sehen Sie die Ergebnisse des Modell-zu-Modell-Geschwindigkeitsvergleichs, bei dem ElevenLabs Turbo v2.5 und Flash v2.5 mit deutlichem Vorsprung bei den verarbeiteten Zeichen pro Sekunde führen.
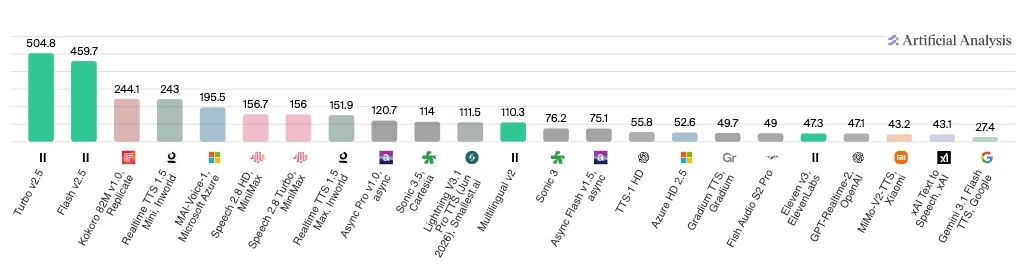
Für Entwickler oder Unternehmen, die eigene Tests durchführen möchten, sind dies die sechs Säulen eines KI-Agenten-Bewertungsrahmens:
- TTS-Stimmqualität: Wie natürlich, klar und ausdrucksstark die synthetische Sprache für Endnutzer klingt. Führende Modelle wie Eleven v3 bieten menschenähnliche, emotionale Wiedergabe in über 70 Sprachen.
- Gesprächsqualität: Versteht ein Modell menschliche Sprache, erkennt Bedeutung und antwortet kontextbezogen und zügig über mehrere Gesprächsrunden hinweg?
- Tool-Nutzung:Inwieweit ein KI-Agent Aufgaben mit verfügbaren Ressourcen ohne menschliches Eingreifen abschließt.
- Intelligenz:Wie gut ein Modell schlussfolgert, neue Eingaben verarbeitet und fehlerhafte oder halluzinierte Antworten vermeidet.
- Compliance und Sicherheit: Neben allen Fähigkeiten müssen KI-Sprachagenten sämtliche regulatorischen und Compliance-Anforderungen einhalten, inklusive aktiver Schutzmechanismen.
- Zuverlässigkeit:Faktoren wie Gesamtverfügbarkeit und konstante Leistung unter Last bestimmen, ob ein konversationaler KI-Agent mit der Nachfrage skalieren kann.
Jede dieser Säulen ist eigenständig, sie greifen jedoch ineinander, um ein hochwertiges Nutzererlebnis zu ermöglichen. Beispielsweise bringt eine verbesserte Stimmqualität wenig, wenn die Latenz hoch bleibt – der Kunde erlebt dann Wartezeiten, bevor die Antwort kommt.
Sehen wir uns jede dieser Bewertungsdimensionen für Voice-KI genauer an.
TTS-Stimmqualität
Wir beginnen mit der Stimmqualität, da dies meist das Erste ist, was Menschen bei der Interaktion mit einem KI-Sprachagenten wahrnehmen. Klingt die Stimme künstlich oder unnatürlich, leidet das subjektive Nutzererlebnis deutlich.
Eine der ursprünglichen Bewertungsmetriken, definiert von der International Telecommunication Union Telecommunication Standard Sector (ITU-T), ist der Mean Opinion Score (MOS). MOS wird auf einer Skala von 1 bis 5 gemessen, wobei 1 unbrauchbar und 5 ausgezeichnet bedeutet. Als subjektive Messgröße basiert sie auf menschlichen Zuhörern, deren Feedback nach einem Gespräch gesammelt wird.
Alles unter MOS 3,5 ist nach heutigen Maßstäben wenig überzeugend und beeinträchtigt wahrscheinlich die Kundenzufriedenheit.
Neben MOS als menschlicher Kennzahl fließen mehrere technische Anforderungen in diesen Wert ein:
- Tonhöhenkonsistenz und Jitter:Tonhöhe und Jitter sind zwei sprachliche Elemente, die Menschen beim Zuhören unbewusst wahrnehmen. „Tonhöhe“ bezeichnet die Intonationsänderung, etwa beim Stellen einer Frage. Jitter beschreibt Schwankungen in der Tonhöhenwiedergabe eines Modells, wodurch die Prosodie innerhalb eines Satzes inkohärent wird. Der Branchenstandard für Jitter liegt bei 30 ms.
- Emotionale Ausdrucksfähigkeit: Eine Stimme kann klar und präzise sein, klingt aber falsch, wenn der Ton nicht zur beabsichtigten Emotion passt. Ohne korrekte Tonalität bauen Menschen weniger Bindung zu KI-Sprachagenten auf und bewerten sie schlechter. ElevenAgents bietet nahezu menschenähnliche Ausdrucksfähigkeit und stimmt jede Antwort klar auf die emotionale Absicht ab.
- Hintergrundgeräusche: Hintergrundgeräusche bei Sprachagenten haben zwei relevante Dimensionen. Ausgangsseitig werden Umgebungsgeräusche subtil hinzugefügt, um die Agenten natürlicher wirken zu lassen. Eingangsseitig verbessert eine optionale Geräuschfilterung auf der STT-Ebene die Genauigkeit. Testen Sie beides: Klingt das Hintergrundrauschen natürlich und wie wirkt sich der Filter auf die STT-Genauigkeit aus?
Beim MOS sollten Sie einen Wert von 4,3–4,5 anstreben, was hohe Werte in allen Wahrnehmungskategorien zeigt. Für MOS-Vorhersagen im großen Maßstab ohne menschliche Panels können Sie Tools wie UTMOS und NISQA nutzen.
Gesprächsqualität
Gesprächsqualität ist eine zusammengesetzte Säule zwischen Stimmqualität und Aufgabenabschluss. Sie misst, wie effektiv ein Sprachagent die Bedürfnisse eines Nutzers versteht, ihn kontextbezogen unterbricht und einen mehrstufigen Dialog bis zum Abschluss führt.
Die Hauptkennzahl ist hier die Intent-Klassifizierungsgenauigkeit, die typischerweise zwischen 85 % und 92 % liegt, Spitzenwerte erreichen über 96 %. Auch 85 % bedeuten, dass 15 % aller Anfragen falsch zugeordnet und an die falschen Ressourcen weitergeleitet werden.
Die technischen Faktoren für eine hohe Intent-Klassifizierungsgenauigkeit sind:
- Gesprächssteuerung: Die Gesprächssteuerung bewertet, wie gut ein Sprachagent den natürlichen Gesprächsfluss steuert. Sie prüft, wann der Agent zuhört, antwortet oder auf weitere Eingaben wartet. Dazu gehört auch das Handling von Unterbrechungen, bei denen eine laufende Antwort abgebrochen und eine neue generiert wird. ElevenLabs nutzt ein Multi-Kontext-Websocket für nahtlose Unterbrechungen.
- Latenz:Latenz beschreibt die Verzögerung zwischen dem Ende einer Nutzereingabe und dem Beginn der Audioantwort. Produktionsreife Sprachagenten sollten eine Time-to-First-Audio unter 500 ms anstreben, unter 300 ms ist optimal. ElevenLabs Flash-Modelle bieten mit ~75 ms branchenführende Inferenzzeiten.
- Fallback-Rate: Die Fallback-Rate misst, wie oft ein KI-Agent einen Nutzer nicht versteht und um Klarstellung oder Wiederholung bittet. Sie ist meist eine Folge der STT-Genauigkeit: Wird die Sprache falsch erkannt, erhält das LLM fehlerhafte Eingaben. Die Fallback-Rate berechnet sich so: Fallback-Rate (%) = (Anzahl Fallbacks / Gesamtzahl Interaktionen) * 100.
ElevenLabs Scribe V2 erreicht mit 2,2 % den niedrigsten WER bei der Artificial Analysis Speech to Text Modellbewertung
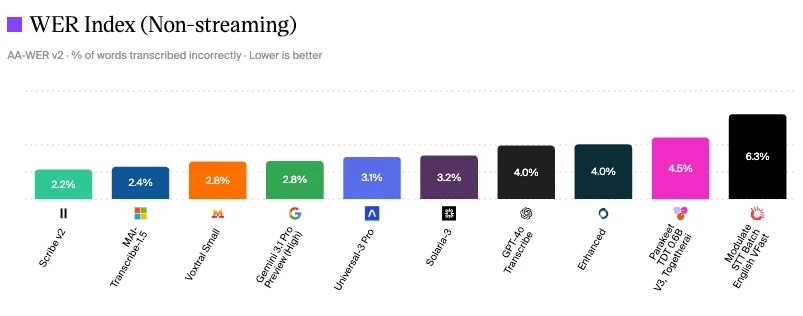
Artificial Analysis Speech to Text Modellbewertung
Eine Möglichkeit, die Gesprächsqualität zu messen, ist der Blick auf Branchen-Benchmarks für verschiedene Komponenten. Wie Sie sehen, hat ElevenLabs Scribe v2 mit 2,2 % den niedrigsten Word Error Rate (Stand Juni 2026), was weniger Missverständnisse, weniger Fallbacks und genauere Intent-Klassifizierung bedeutet.
Unternehmen stellen oft fest, dass die Gesprächsqualität auch vom Workflow des Sprachagenten abhängt. Im Kundenservice wäre z. B. die Qualität der Eskalationsübergabe oder der FAQ-Lösung relevant.
Tool-Nutzung und Aufgabenabschluss
Während die Qualität das Gesprächserlebnis misst, bewertet der Aufgabenabschluss, ob ein erfolgreiches Ergebnis erzielt wurde. Unternehmen sollten diesem Teil des Bewertungsrahmens besondere Aufmerksamkeit schenken, da er direkt mit Geschäftsergebnissen verknüpft ist.
Ein Maß für die Tool-Nutzung ist die Slot-Fill-Genauigkeit, die zeigt, wie gut KI-Agenten Routineaufgaben wie das Ausfüllen von Formularen mit Kundendaten erledigen. Hohe Slot-Fill-Genauigkeit belegt, dass der Agent nahtlos vom Gespräch zur Aktion übergeht, ohne Informationen zu verlieren.
Die Task Success Rate (TSR) misst prozentual, wie viele End-to-End-Aufgaben ein Agent erfolgreich abgeschlossen hat. Der Abschluss basiert darauf, dass der Agent sowohl die Anfrage versteht als auch die richtigen Tools (APIs, Datenbanken, RAG, interne Wissensdatenbanken) nutzt.
Die Formel für TSR lautet:
TSR = (Vollständig erledigte Aufgaben / Gesamtzahl der Versuche) x 100
Produktionsreife Sprachagenten sollten eine TSR von über 85 % anstreben und Tool-Call-Genauigkeit sowie Tool-Call-Zuverlässigkeit überwachen. Um Einbußen zu vermeiden, testen Sie regelmäßig auf Änderungen bei Prompts oder Modellen. Schon kleine Abweichungen können große Auswirkungen auf die TSR haben.
Intelligenz
Intelligenz beschreibt die Schlussfolgerungs- und höheren Fähigkeiten eines Sprachagenten. Diese Säule unterscheidet klar zwischen sprachgesteuertem IVR (Interactive Voice Response) und einem Voice-KI-Agenten.
Wichtige Bewertungsdimensionen sind:
- Halluzinationsrisiko: Halluzinationen, bei denen ein Agent falsche oder nicht mit Unternehmensdokumenten übereinstimmende Informationen liefert, sind bei Voice-KI besonders kritisch, da sie überzeugend klingen.Aktuelle Studien zeigen , dass häufige Halluzinationen die Kundenzufriedenheit mit Sprachagenten deutlich beeinträchtigen.
- Out-of-Scope-Handling: Intelligente Agenten erkennen, wenn eine Frage außerhalb ihres Kontexts liegt, und reagieren angemessen. Statt zu halluzinieren, lehnen sie ab oder lenken das Gespräch zurück in bekannte Bereiche.
- Kontextbeibehaltung: Kann ein Agent über mehrere Gesprächsrunden hinweg Entitäten und Zusagen verfolgen? Ohne diese Fähigkeit müssen Kunden sich wiederholen oder erhalten widersprüchliche Antworten.
- Schlussfolgerungen und mehrstufige Logik: Kann der Agent bedingte Logik oder Ketten von Schlussfolgerungen über mehrere Gesprächsrunden hinweg korrekt verarbeiten? Besonders in technischen Anwendungsfällen wie Finanzdienstleistungen ist die Fähigkeit, im vorgegebenen Kontext zu schlussfolgern, entscheidend.
Für diese Dimensionen gibt es verschiedene externe Benchmarks. Beispielsweise bewertet Stanford’s Holistic Evaluation of Language Models (HELM) LLMs in unterschiedlichen Kategorien. Für Halluzinationen bietet TruthfulQA eine robuste Analyse, wie oft falsche Antworten auftreten.
Ein Vorteil von ElevenAgents ist, dass Sie – anders als bei manchen Voice-Plattformen – das LLM komplett austauschen können. So können Sie das jeweils führende Modell für Ihre Anforderungen einsetzen.
Compliance und Sicherheit
Unternehmen müssen aktive Schutzmechanismen implementieren, um schädliche oder regelwidrige Ausgaben zu verhindern. Anders als systeminterne Prompts, die umgangen werden können, laufen unabhängige Schutzprüfungen als separate Schicht außerhalb des Modells. Sie prüfen Ausgaben, bevor sie den Nutzer erreichen, und stoppen das Gespräch bei Gefahr.
Auditierbarkeit ist ebenfalls erforderlich: Produktionsagenten müssen detaillierte Protokolle über Entscheidungen und Ausgaben führen, die eine nachträgliche Überprüfung ermöglichen. Besonders in stark regulierten Branchen ist der Nachweis der Compliance im Nachhinein genauso wichtig wie die Einhaltung im Betrieb.
Die genauen Vorschriften, die Ihr Unternehmen einhalten muss, hängen von der Branche ab. Zu den häufigsten Rahmenwerken zählen:
- HIPAA: Für geschützte Gesundheitsdaten im US-Gesundheitswesen.
- PCI-DSS: Für Agenten, die Zahlungsdaten verarbeiten.
- DSGVO: Datenschutzvorgaben für die EU und Unternehmen mit EU-Kunden.
Für Unternehmen, die ihre Compliance bewerten, hält ElevenLabs AICPA SOC Type II und GDPR-Compliance und hat zudem die AIUC-1-Zertifizierung erreicht. Die AIUC-1 ist ein speziell für KI-Agenten entwickelter Sicherheitsstandard.
Zuverlässigkeit
Zuverlässigkeit ist die letzte Säule im Bewertungsrahmen und umfasst, ob ein Agent konstant in Echtzeit liefern kann.
Achten Sie bei der Bewertung eines Sprachagenten auf folgende Merkmale:
- Verfügbarkeit:Jede kundenorientierte Anwendung erwartet 99,9 % Verfügbarkeit, um Ausfälle zu vermeiden. Besonders bei permanenten Einsätzen wie Support ist dies entscheidend.
- Störungsfreier Abbau: Aufgrund der Komplexität von Sprachagenten sollte der Agent bei Ausfall einer Komponente kontrolliert reagieren – etwa durch Übergabe an einen Menschen statt mit Fehlern oder Überlastung weiterzulaufen.
- Leistung unter Last: Lasttests sollten mindestens die doppelte erwartete Spitzenlast simulieren, bevor Sie live gehen. So lassen sich Latenzsteigerungen oder Leistungseinbußen unter hoher Belastung erkennen.
Selbst ein hochwertiges Modell ist unbrauchbar, wenn es nicht mit Ihrer Nachfrage skaliert. ElevenAgents wird von 1.000.000 führenden Unternehmen und Kreativen genutzt und zeigt so, dass die Plattform auch im großen Maßstab zuverlässig liefert.
So messen Sie MOS für Sprachagenten (Schritt für Schritt)
Wenn Sie MOS manuell messen möchten, benötigen Sie viele menschliche Zuhörer und eine Auswahl von Audio-Clips aus echten Gesprächen. Der strukturierte Prozess umfasst Feedbacksammlung, Mittelwertbildung und Auswertung.
So messen Sie MOS für Sprachagenten in der Praxis:
- Testset vorbereiten: Wählen Sie eine repräsentative Stichprobe von Audioausgaben Ihres Agenten, mindestens 100 Clips aus verschiedenen Gesprächen.
- Bewertungssitzung durchführen: Lassen Sie menschliche Zuhörer jede Aufnahme auf einer Skala von 1 bis 5 hinsichtlich der Kommunikationsqualität bewerten.
- Bewertungen aggregieren und Score berechnen: Mitteln Sie die Bewertungen pro Clip und dann über alle Clips, um den Gesamt-MOS zu erhalten. Ein MOS von 4,3 oder höher zeigt Produktionsreife.
Dieser Prozess ist zwar aufwendig, liefert aber einen soliden MOS für Ihren Sprachagenten. Für Skalierung können Sie automatisierte Tools wie NISQA einsetzen, die MOS-Werte programmatisch vorhersagen. Diese Systeme lassen sich in Ihre aktiven Pipelines integrieren, um MOS kontinuierlich zu überwachen.
KI- vs. Human-Benchmarks: FCR, AHT und CSAT
Die wiederholte MOS-Messung zeigt Modellverbesserungen oder -verschlechterungen. Zusätzlichen Kontext erhalten Sie durch den Vergleich mit menschlicher Leistung. So sehen Sie, ob Ihr Sprachagent auf dem Niveau menschlicher Agenten arbeitet.
Hier einige Kennzahlen für KI- vs. Human-Benchmarks.
KI-Agenten sollten menschliche FCR- und CSAT-Werte erreichen und dabei die AHT deutlich verbessern. Letzteres gelingt, da KI-Agenten meist allgemeinere Gespräche führen. Viele Unternehmen setzen KI-Agenten als Erstkontakt ein und leiten nur komplexe Fälle an Menschen weiter.
Daten von Poe, einem KI-Vergleichsaggregator, zeigen 2025, dass ElevenLabs die höchste Gesamt-Erfüllungsquote bei Anfragen erreicht hat und 74,4 % aller eingehenden Anfragen abschließen konnte. Der Erfolg spiegelt sich in der wachsenden Nutzung wider: Eleven v3 und v2.5-Turbo machen über 60 % der an KI-Modelle gesendeten Nachrichten aus.
Nachrichten an KI-Modelle im Zeitverlauf, ElevenLabs führt den Poe Voice Agent Bewertungsrahmen an
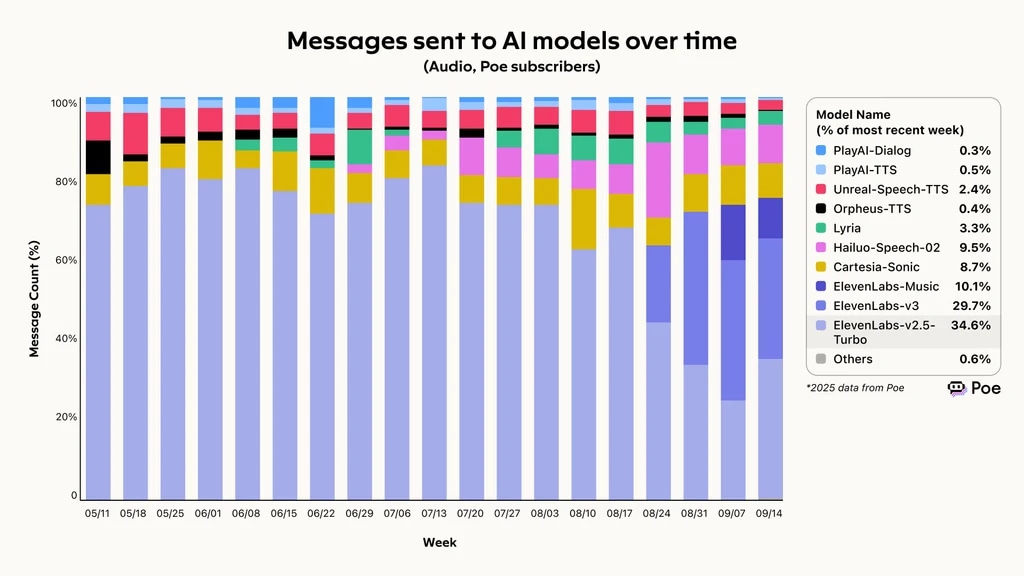
Nachrichten an KI-Modelle im Zeitverlauf, gemessen von Poe
Häufige Fehler bei der Bewertung von Sprachagenten
Bei der Anwendung eines Bewertungsrahmens ist es verlockend, nur Best-Case-Szenarien zu testen. Die Realität ist, dass die Alltagserfahrung Ihrer Kunden mit Voice-KI selten idealen Bedingungen entspricht.
Hier sind drei häufige Fehler bei der Bewertung von Sprachagenten und wie Sie sie vermeiden:
- Nur den einfachsten Weg testen: Besonders bei der Auswahl von Audio-Clips für MOS sollten Sie Randfälle einbeziehen. Clips mit Hintergrundgeräuschen oder Akzenten sind im Alltag häufig – Tests nur mit „sauberen“ Audiodateien führen zu einer falschen MOS-Kalibrierung.
- Containment über Lösung stellen:Modelle darauf zu optimieren, Nutzer im Agentensystem zu halten, erhöht die Containment-Rate, verbessert aber nicht die Ergebnisse. Ist Ihr FCR trotz hoher Containment-Rate niedrig, geraten Nutzer in eine Endlosschleife. Ermöglichen Sie Nutzern, bei Bedarf mit menschlichen Agenten zu sprechen.
- Latenz-Prozentile ignorieren:SLAs definieren Latenz oft auf P95-Niveau. Dieser Wert ist wichtig für die Mehrheit der Nutzer, aber die letzten 5 % sind ebenfalls echte Kunden. Bei 10.000 täglichen Anrufen sind das immer noch 500 Personen mit langsamer Erfahrung. Setzen Sie P99 als SLA-Ziel, nicht nur Median oder P95.
Mit diesen Punkten schaffen Sie faire und repräsentative Ausgangswerte statt idealisierter Durchschnittswerte.
Warum eine anwendungsfallspezifische Bewertung sinnvoll ist
Die sechs Säulen dieses Rahmens geben Orientierung, die Gewichtung hängt jedoch von Ihrer Branche ab. Im Finanzdienstleistungsbereich stehen Compliance und Tool-Nutzung im Vordergrund, bei Konsumermarken ist die TTS-Stimmqualität entscheidend.
Hier zwei Beispiele für anwendungsfallspezifische Bewertungen und wie sie die Gewichtung der Säulen verschieben.
Kundensupport
In bestimmten Branchen wie Callcentern sind weitere Kennzahlen wie First Call Resolution (FCR) wichtig. Wenn ein Anruf ohne menschliches Eingreifen gelöst wird, entlastet das die menschlichen Servicekräfte deutlich.McKinsey schätzt , dass Callcenter mit Sprachagenten das Interaktionsvolumen um bis zu 50 % senken können.
Weniger wichtig als die Task Success Rate ist hier die Containment-Rate. Sie misst die Gesamtdauer eines Anrufs. Ist die Containment-Rate hoch, aber der FCR niedrig, werden Kunden gehalten, ohne eine Lösung zu erhalten – das führt zu Frustration.
Weitere relevante Kennzahlen sind AHT, wobei KI-Agenten Routineprobleme schnell lösen sollen. Im Kundensupport stehen daher Gesprächsqualität, insbesondere Gesprächssteuerung und Fallback-Rate, im Vordergrund.
Gesundheitswesen
Gesundheitswesen ist ein stark regulierter Bereich mit strengen Compliance-Anforderungen, die den Betrieb von Sprachagenten besonders anspruchsvoll machen. Compliance steht im Mittelpunkt und verschiebt die Gewichtung der Sicherheits- und Intelligenzsäule deutlich.
Gesundheits-Chatbots müssen Terminvereinbarungen, Telemedizin-Zugänge, Symptom-Triage und Versicherungsfragen abdecken. All dies erfordert hohe Intelligenz und Tool-Nutzung – erneut zeigt sich, dass branchenspezifische Anforderungen die Gewichtung der Säulen bestimmen.
Unabhängig von Ihrer Branche hilft das Verständnis und die ausgewogene Anwendung der Kernsäulen bei der Auswahl der besten Sprachagenten.
Mit ElevenAgents leistungsstarke und latenzarme Lösungen bauen
Die gewählte Plattform beeinflusst direkt, wie Ihre Sprachagenten in realen Workflows abschneiden. Gerade im Kundenkontakt müssen Sie sicher sein, dass Ihr Agent in jeder Kategorie überzeugt.
ElevenAgents ist für produktive Sprach-Anwendungen konzipiert und kombiniert führendes TTS mit Eleven v3, Echtzeit-STT durch Scribe v2 und eine Agenten-Orchestrierungsschicht für den Unternehmenseinsatz. Jede Komponente ist auf die Benchmarks dieses Rahmens ausgelegt, damit Sie hochwertige Nutzererlebnisse liefern können.
Ob Sie noch abwägen oder schon starten möchten – ElevenLabs bietet Ihnen den passenden Weg. Entdecken Sie die ElevenAgents-Plattform und prüfen Sie, wie sie zu Ihrem Anwendungsfall passt, oder registrieren Sie sich und starten Sie direkt mit dem Aufbau.
.webp&w=3840&q=80)


