Lernen Sie Eleven v3 kennen.
Unser ausdrucksstärkstes KI-Sprachmodell.


Angetrieben von Eleven v3
Steuern Sie Emotion, Vortrag und Richtung mit Audiotags
Erstellen Sie kontrollierbare, ausdrucksstarke Sprache, die mit Emotionen, Audioereignissen und immersiven Klanglandschaften angereichert ist.

Erzeugen Sie dynamische Gespräche zwischen mehreren Sprechern
Erstellen Sie Audiogespräche, bei denen Sprecher Kontext und Emotionen teilen, sodass generierte Dialoge natürlich und menschlich klingen.

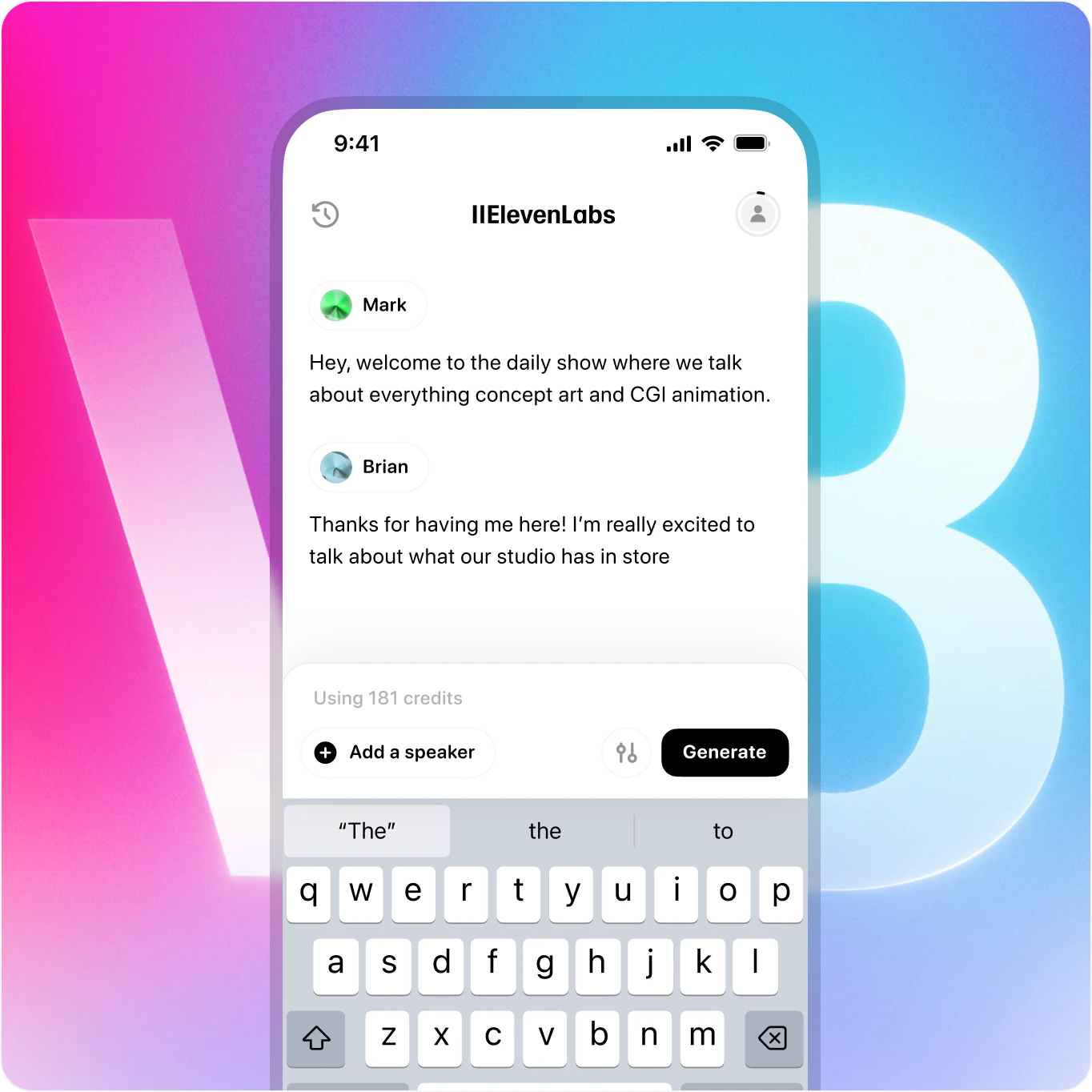
Nehmen Sie v3 überall mit hin - jetzt auf Mobilgeräten verfügbar
Erstellen Sie lebensechte Sprache mit reichhaltigen Emotionen - alles von Ihrem Telefon aus. Unsere Sprach-KI liefert Studioqualität von überall.
Menschliche Sprache in über 70 Sprachen
Erreichen Sie ein globales Publikum mit ausdrucksstarker und nuancierter Sprache in jeder wichtigen Sprache.









Erleben Sie unser ausdrucksstärkstes Modell mit emotionaler Tiefe und reicher Darbietung.
Eleven v3 unterscheidet sich von anderen ElevenLabs-Modellen und bietet einen breiten Dynamikbereich, der durch Inline-Audiotags gesteuert wird.
Entwickeln Sie mit der Eleven v3 API
Erzeugen Sie lebensechte Sprache in über 70 Sprachen mit Emotionen, Richtung und Multi-Sprecher-Steuerung unter Verwendung von Inline-Audiotags.

import { ElevenLabsClient, play } from '@elevenlabs/elevenlabs-js';
import 'dotenv/config';
const elevenlabs = new ElevenLabsClient();
const voiceId = 'JBFqnCBsd6RMkjVDRZzb';
const audio = await elevenlabs.textToSpeech.convert(voiceId, {
text: '[langsam] Damals... [lacht] hatten wir keine Telefone.
[flüstert] Nur unbefestigte Straßen und [hustet] große Träume. [traurig] Dann passierte es',
modelId: 'eleven_v3',
outputFormat: 'mp3_44100_128',
});
await play(audio);