语音智能体评估框架:6 大核心维度解析
- 发布时间
- 最近更新
语音智能体需要协调多项几乎同时进行的工具。这包括实时录音客户反馈、
环节如此繁多,如何准确评估语音智能体的表现?
本文将提出一套六大核心维度的语音智能体评估框架,明确评估时应关注哪些指标。同时也会说明不同行业应如何权衡这些维度,以及评估时常见的误区。
摘要
- 六大语音智能体评估核心维度包括:TTS 音色质量、对话质量、工具使用与任务完成度、智能水平、合规与安全、可靠性。
- 主要生产目标建议:MOS 达到 4.3,TSR 超过 85%,首段音频响应时间低于 500ms。
- 不同行业会根据实际需求对各维度权重有所不同,部分场景会更侧重某一项。
- 常见测试误区包括只评估干净音频、忽略 P99 延迟峰值等。
- ElevenLabs 在关键指标上表现领先:Scribe v2 语音转文本模型 WER 仅 2.2%(Artificial Analysis,2026 年 6 月),Flash v2.5 和 Turbo v2.5 速度表现优异,ElevenAgents 推理延迟约 75ms。
什么是语音智能体评估框架?
AI 语音智能体评估框架是一套结构化体系,支持从多个维度测试性能。完善的框架会涵盖从音频质量、对话流程到合规性等各项指标。
与文本机器人不同,语音智能体每次交互至少涉及三层技术:自动语音识别(ASR)将语音转为文本,LLM 生成回复,TTS 再将回复转为音频。任一环节出错,都会影响整体体验。
正因流程复杂,企业在选择供应商和部署前必须评估语音智能体。任何额外延迟或不准确回复都可能带来实际影响,比如客户流失,甚至合规罚款和声誉损失。
评估框架通过基准测试和可量化数据,判断智能体是否适用于特定场景。对企业来说,评估不同语音模型有助于为客户选择最佳方案。
语音智能体评估的六大核心维度
虽然创建和部署 AI 智能体 变得越来越简单,但其底层流程依然复杂。多个组件协同工作,聆听用户、理解需求、传递信息给 LLM,再生成音频回复,整个过程涉及大量近乎同步的操作。
企业若想选择最优语音智能体,需要一套严谨的基准评估框架。
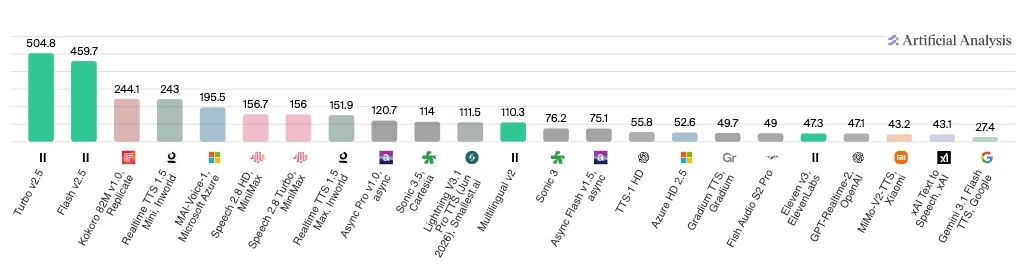
如果你更关注测试结果,人工分析 提供了基于不同组件的智能体对比。下方展示了其模型速度对比结果,ElevenLabs 的 Turbo v2.5 和 Flash v2.5 在每秒处理字符数上遥遥领先。
对于希望自行测试的开发者或企业,以下是 AI 智能体评估框架的六大核心维度:
- TTS 音色质量: 合成语音对终端用户来说是否自然、清晰、有表现力。行业领先模型如 Eleven v3,可在 70 多种语言中实现接近真人、富有情感的表达。
- 对话质量: 模型能否理解人类语音、准确把握语义,并在多轮对话中及时做出上下文相关回复?
- 工具使用:AI 智能体能否独立利用现有资源完成任务,无需人工介入。
- 智能水平:模型推理、处理新输入、避免错误或幻觉回复的能力。
- 合规与安全:除了所有功能外,
- 可靠性:如总可用时长、负载下性能等,判断对话式 AI 智能体能否随需求扩展。
每个维度虽独立,但相互影响,共同决定用户最终体验。例如,模型音色质量提升但延迟高,用户仍会因等待而感到不适。
下面将详细解析每个语音 AI 评估维度。
TTS 音色质量
我们首先关注音色质量,因为这是用户与 AI 对话时最直观的感受。如果听起来机械或不自然,整体体验会大打折扣。
国际电信联盟(ITU-T)定义的原始评估指标之一是主观意见评分(MOS),满分 5 分,1 分不可用,5 分极佳。MOS 由真人听众主观打分,通话后收集反馈。
MOS 低于 3.5 基本不达标,尤其在当前标准下,容易影响客户满意度。
MOS 虽为主观指标,但多项技术要求共同影响该分数:
- 音高一致性与抖动:音高和抖动是人类听觉自然感知的语言要素。“音高”指语音语调变化,如提问时语调上扬。抖动则是模型对音高的把控不稳定,导致句子韵律不连贯。行业抖动基线为 30ms。
- 情感表达力: 语音即使清晰准确,若语气与句子情感不符,依然会让人觉得不自然。缺乏情感线索,用户与 AI 对话的亲切感会下降,评分也会降低。ElevenAgents 提供 接近真人的情感表达,让每句回复都能准确传递情感。
- 背景噪音: 语音智能体的背景噪音有两方面值得评估。输出端,适当加入环境噪音可让语音更自然。输入端,STT 层的背景噪音过滤可提升识别准确率。评估时应同时测试:一方面听环境噪音是否自然,另一方面对比开启/关闭噪音过滤时 STT 的准确率。
MOS 计算时建议目标为 4.3-4.5,代表各项感知指标表现优异。若需大规模预测 MOS,可用 UTMOS 和 NISQA 等工具。
对话质量
对话质量是介于音色质量和任务完成度之间的综合维度,衡量语音智能体能否理解用户需求、适时打断并顺利完成多轮对话。
主要指标为意图识别准确率,通常在 85%-92% 之间,顶级模型可达 96% 以上。85% 看似很高,但仍有 15% 的请求被误判,流向错误资源。
影响意图识别准确率的技术要素包括:
- 轮流发言: 轮流发言决定语音智能体能否把握自然对话节奏,何时倾听、何时回复、何时等待输入。还包括打断处理,即模型能否在用户插话时及时中断当前回复,基于新输入生成新内容。ElevenLabs 采用 多上下文 websocket,实现流畅的打断处理。
- 延迟:延迟 指用户说完一句话到智能体开始音频回复的端到端延时。生产级语音智能体建议首段音频响应低于 500ms,300ms 以下更佳。ElevenLabs Flash 模型推理时间约 75ms,行业领先,助你在此项表现出色。
- 兜底率: 兜底率衡量 AI 智能体未能理解用户时请求澄清或重复的频率。主要受 STT 准确率影响,若语音识别层误听或误转,LLM 得到的输入就会出错。兜底率计算公式:兜底率(%)=(兜底次数 / 总交互次数)* 100。
ElevenLabs Scribe V2 在 Artificial Analysis 语音转文本模型评测中 WER 仅 2.2%
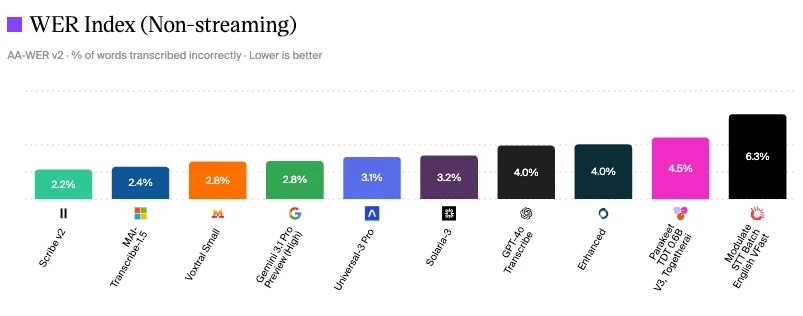
衡量对话质量的一种方式是参考行业基准标准。可以看到,ElevenLabs Scribe v2 截至 2026 年 6 月 WER 仅 2.2%,意味着误听更少、兜底率更低、意图识别更准确。
企业还需结合语音智能体所在 workflow,评估对话质量。例如客服场景,还需关注升级转接质量或 FAQ 解决率。
工具使用与任务完成度
对话质量关注交流体验,任务完成度则衡量是否达成目标。企业应重点关注这一环节,因为它直接影响业务结果。
工具使用的一个指标是槽位填充准确率,反映 AI 智能体能否顺利完成如填写客户信息等常规任务。高准确率说明智能体能无缝衔接对话与操作,信息不丢失。
任务成功率(TSR)以百分比衡量智能体成功完成的端到端任务。完成度取决于智能体既能理解请求,又能调用正确的工具(API、数据库、RAG、内部知识库等)协助处理。
TSR 计算公式:
TSR =(成功完成任务数 / 总尝试任务数)x 100
生产级语音智能体建议 TSR 超过 85%,并监控工具调用准确率和可靠性。为避免 TSR 下滑,需对提示词或模型变更做回归测试,哪怕微小偏差也可能带来显著影响。
智能水平
智能水平体现语音智能体的推理和高级能力,是区分传统 IVR 与语音 AI 智能体的关键。
评估要点包括:
- 幻觉风险: 幻觉指智能体生成与公司资料不符或错误的信息,语音 AI 若自信地输出错误内容,影响尤为严重。最新研究显示,常见幻觉会严重影响客户对语音智能体的满意度。
- 超出范围处理: 智能体能否识别问题超出自身知识范围,并做出恰当回应。与其胡乱回答,不如拒绝或引导回相关话题。
- 上下文保持: 多轮对话中,智能体能否追踪前文提及的实体和承诺?否则用户可能需要重复信息,或收到自相矛盾的回复。
- 推理与多步逻辑: 智能体能否正确处理条件逻辑或多轮推理?尤其在金融服务等技术场景,限定上下文内的推理能力至关重要。
这些维度和组件均有第三方基准可参考。例如 Stanford 的 HELM 基准评测 LLM 在不同类别的表现。TruthfulQA 可分析幻觉出现频率。
ElevenAgents 的一大优势是,支持灵活更换 LLM 层,不像部分平台只能用单一底层模型。实际应用中,可根据推理基准选择最适合的模型。
合规与安全
企业需设置主动防护机制,防止输出有害或违规内容。与系统级提示词不同,独立防护检查作为模型外的单独层运行,在内容到达用户前进行评估,若偏离安全范围则中止对话。
可审计性同样重要,生产环境下需详细记录决策和输出,便于事后复查。尤其在强监管行业,事后证明合规性与过程合规同等重要。
具体合规要求因行业而异,常见框架包括:
- HIPAA: 适用于美国医疗健康数据保护。
- PCI-DSS: 适用于处理支付卡数据的智能体。
- GDPR: 针对欧盟及其客户的数据隐私要求。
企业评估合规性时,ElevenLabs 已通过 AICPA SOC 2 和 GDPR 合规,并获得 AIUC-1 认证。AIUC-1 是专为 AI 智能体设计的安全标准。
可靠性
可靠性是语音智能体评估框架的最后一环,关注智能体能否持续稳定地实时交付。
评估语音智能体时,需关注以下特性:
- 可用性:面向客户的部署需保证 99.9% 可用性,避免宕机。尤其是 7x24 小时场景,如呼入支持,可靠性尤为关键。
- 平滑降级: 由于语音智能体底层复杂,若某组件出现故障,智能体应能平滑降级。实际操作中应转接人工,而不是带故障继续运行或频繁报错。
- 负载下性能: 压力测试建议模拟至少 2 倍预期峰值并发,提前发现大规模下的延迟或性能下降。
即使模型质量再高,若无法随客户需求扩展,依然不可用。ElevenAgents 已获 1,000,000 名创作者和企业信赖,平台可支持企业级部署且不影响性能基准。
语音智能体 MOS 测量方法(分步说明)
如需手动测量 MOS,需要大量真人听众和真实对话音频片段。流程包括收集反馈、取平均值并解读数据。
实际操作步骤如下:
- 准备测试集: 从智能体输出中选取有代表性的音频样本,覆盖至少 100 段不同对话。
- 进行评分环节: 让真人听众根据沟通体验质量,按 1-5 分为每段音频打分。
- 汇总评分并计算分数: 先对每段音频取平均分,再对所有样本取总平均,得出整体 MOS。MOS 达到 4.3 或更高,说明语音智能体已可投入生产使用。
虽然流程较为繁琐,但能获得可靠的 MOS。如果需大规模测试,可用 NISQA 等自动化工具预测 MOS,并集成到现有流程中,持续监控 MOS 变化。
AI 与人工测试基准:FCR、AHT、CSAT
持续计算 MOS 可观察模型提升或回退,结合人工表现基准能获得更多参考。了解人工在类似岗位的实际表现,有助于判断语音智能体是否接近理想水平。
以下是 AI 与人工测试基准的几个常用指标。
AI 智能体应能达到人工 FCR 和 CSAT 水平,同时大幅提升 AHT。AHT 提升源于 AI 智能体通常处理更通用的对话。许多企业采用 AI 智能体作为首轮响应,遇到复杂问题再转人工。
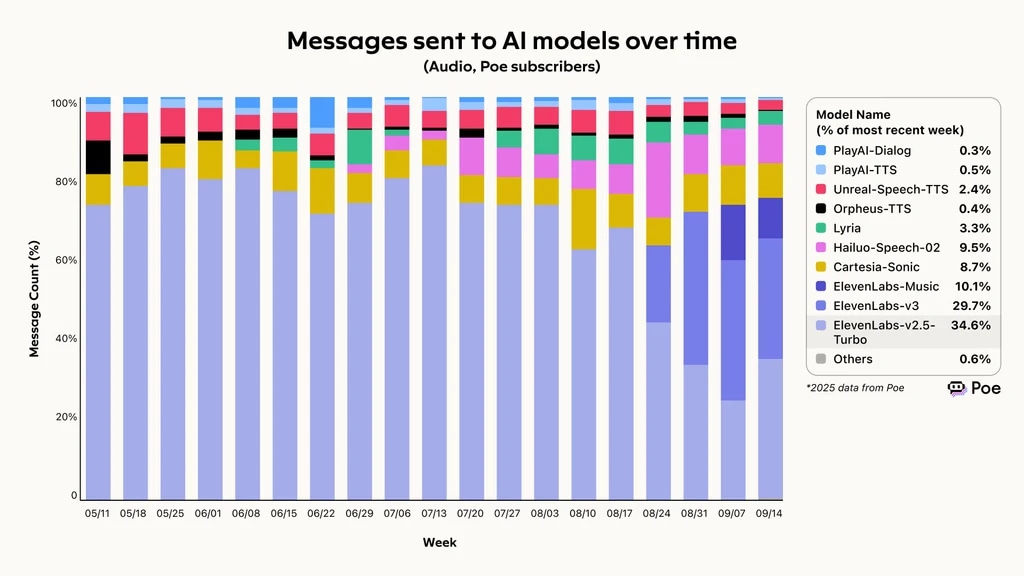
Poe(AI 对比平台)2025 年数据显示,ElevenLabs 保持了最强的整体请求完成能力,完成率达 74.4%。Eleven v3 和 v2.5-Turbo 占据 AI 模型消息发送量的 60% 以上,使用量持续增长。
AI 模型消息发送量趋势,ElevenLabs 领跑 poe 语音智能体评估框架
语音智能体测试常见误区
在执行语音智能体评估框架时,容易只测试理想场景。但现实中,客户日常体验往往并非最佳条件。
以下是三大常见测试误区及改进建议:
- 只测最简单路径: 选取 MOS 音频样本时,务必包含边缘场景。现实中带背景噪音或口音的音频极为常见,只测“干净”音频会导致 MOS 偏高。
- 只关注留存率而忽略解决率:模型若只优化用户留在智能体系统内,留存率虽高但未提升实际效果。若 FCR 低但留存率高,说明用户被困在无解循环。应允许用户随时转接人工。
- 忽略延迟分位数:SLA 通常以 P95 延迟为标准,但最后 5% 也是实际用户。大规模下,5% 意味着每天 10,000 通话中有 500 人体验缓慢。应以 P99 作为 SLA 目标,而非仅关注中位数或 P95。
牢记这些要点,可建立更公平、具代表性的基线,而非理想化平均值。
为何要做场景专属评估
本框架的六大维度为评估提供方向,但各维度权重需结合行业实际。例如金融服务企业更重视合规与工具使用,消费品牌则更关注 TTS 音色质量。
以下是两类场景专属评估案例,展示各维度权重如何变化。
客户支持
在呼叫中心等行业,首呼解决率(FCR)等任务完成指标尤为重要。能否在无需人工介入的情况下解决来电,可大幅减轻人工客服压力。麦肯锡估算,使用语音智能体的呼叫中心可减少高达 50% 的交互量。
虽然任务成功率更重要,但留存率也是一项参考。留存率衡量通话总时长,若留存率高但 FCR 低,说明智能体让用户反复等待却未解决问题,体验会很差。
还可关注 AHT,AI 智能体应快速解决常规问题。因此,客户支持领域更看重对话质量,尤其是轮流发言和兜底率。
医疗健康
医疗健康 行业监管严格,合规要求高,语音智能体操作极为敏感。合规是核心,安全维度权重显著提升,智能水平同样重要。
医疗健康聊天机器人 需处理预约、远程医疗、症状分诊、保险等问题,均需高智能和工具使用能力,体现行业/岗位需求决定各维度重要性。
无论你所在行业如何,理解并合理应用语音智能体评估核心维度,能帮助你找到最合适的智能体。
用 ElevenAgents 构建高性能、低延迟语音智能体
所选平台直接影响语音智能体在真实 workflow 中的表现。尤其面对客户时,必须确保智能体各项指标都能达标。
ElevenAgents 专为生产级语音部署打造,集成行业领先的 TTS(Eleven v3)、实时 STT(Scribe v2),以及智能体编排层,支持企业级扩展。每个组件都针对本框架设定的基准优化,助你为客户提供高质量体验。
无论你还在权衡方案,还是准备动手开发,ElevenLabs 都能满足需求。欢迎探索 ElevenAgents 平台,了解如何适配你的场景,或注册账号,立即开始构建。



.webp&w=3840&q=80)
