
Eleven v3 オーディオタグ: 感情的な文脈を音声で表現
- カテゴリ
- リソース
- 日付
リアルタイムでコミュニケーションするAIシステムの構築方法についてご紹介します。ターンテイキング、遅延、表現力豊かな話し方などの技術的な選択や、実際に提供しているモデルについて解説します。

私たちは何年もかけてこの分野に取り組んできました。本記事では、これまでに提供してきた内容や、その背後にある研究・プロダクトの意思決定についてご紹介します。
当社の主力プロダクト - ElevenAgents(v3 Conversational搭載)
エクスプレッシブモード - Mark - パーソナルローン受電(パニック)- launch asset.mp4
インタラクションモデルを機能させるために必要なこと
インタラクションシステムが自然で魅力的なやり取りを実現するには、次の3つが重要です。
これまでに提供した主な機能
Eleven v3 Conversational。 v3の会話型バージョンで、2026年2月にElevenAgents内でリリース。ターンテイキング機能を標準搭載。TTSモデルとしてv3 Conversationalを選択すると、ターンテイキングモデルが自動的に有効になります。
スペキュレーティブターンテイキング。 v3 Conversationalの独立した機能で、ユーザーが無言の間にLLMの応答生成を事前に開始し、体感的な遅延を減らします。
Flash v2.5。 最速のテキスト読み上げモデルで、リアルタイム低遅延利用向けに設計。推論時間は約75msです。*
Scribe v2。 業界トップクラスの精度を誇るスピーチtoテキストモデルです。
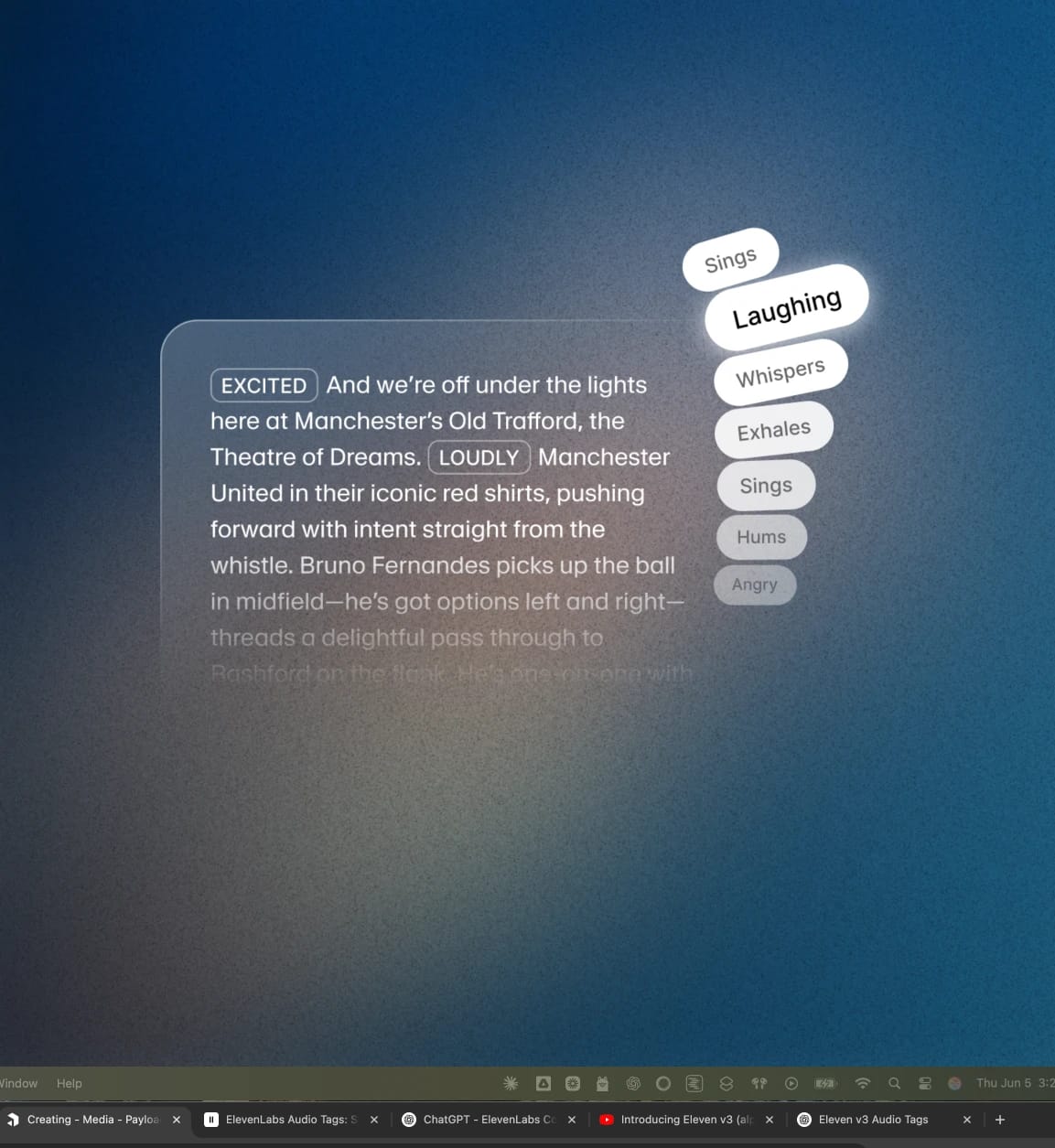
ElevenAgents エクスプレッシブモード。 エージェントが[laughs](笑う)、[whispers](ささやく)、[sighs](ため息)、[slow](ゆっくり)などの表現タグを使い、状況に応じて話し方をコントロールできます。
ElevenAgents エクスプレッシブモード。 エージェントが[laughs](笑う)、[whispers](ささやく)、[sighs](ため息)、[slow](ゆっくり)などの表現タグを使い、状況に応じて話し方をコントロールできます。
今後の展望
多くのAIとの会話は、まだ「問い合わせ」のように感じられます。本当の会話はそうではありません。そのギャップを埋めることが私たちの目標です。



