
Eleven v3 Audio Tags : Exprimer le contexte émotionnel dans la parole
- Catégorie
- Ressources
- Date
Comment nous concevons des systèmes IA capables de communiquer en temps réel : nos choix techniques sur la gestion des tours de parole, la latence, l’expressivité, et les modèles que nous avons lancés.

Nous travaillons dans cette direction depuis des années. Cet article présente ce que nous avons lancé, ainsi que les choix de recherche et de produit qui ont guidé notre démarche.
Notre produit phare : ElevenAgents avec v3 Conversational
Mode expressif - Mark - Prêt personnel entrant (Panique) - launch asset.mp4
Ce qu’il faut pour qu’un modèle d’interaction fonctionne
Trois éléments doivent être réunis pour qu’un système d’interaction fonctionne bien et crée des échanges naturels et engageants :
Aperçu de ce que nous avons lancé
Eleven v3 Conversationnel.Notre version conversationnelle de v3, lancée dans ElevenAgents en février 2026 avec la gestion intégrée de la prise de parole. Le modèle de prise de parole est activé par défaut quand v3 Conversational est choisi comme modèle TTS.
Prise de parole spéculative.Une fonctionnalité distincte de v3 Conversational qui déclenche la génération de réponse LLM pendant les silences de l’utilisateur, pour réduire la latence perçue.
Flash v2.5.Notre modèle Text to Speech le plus rapide, conçu pour un usage en temps réel avec une latence minimale, à environ 75 ms d’inférence.*
Scribe v2.Notre modèle Speech to Text avec une précision de pointe.
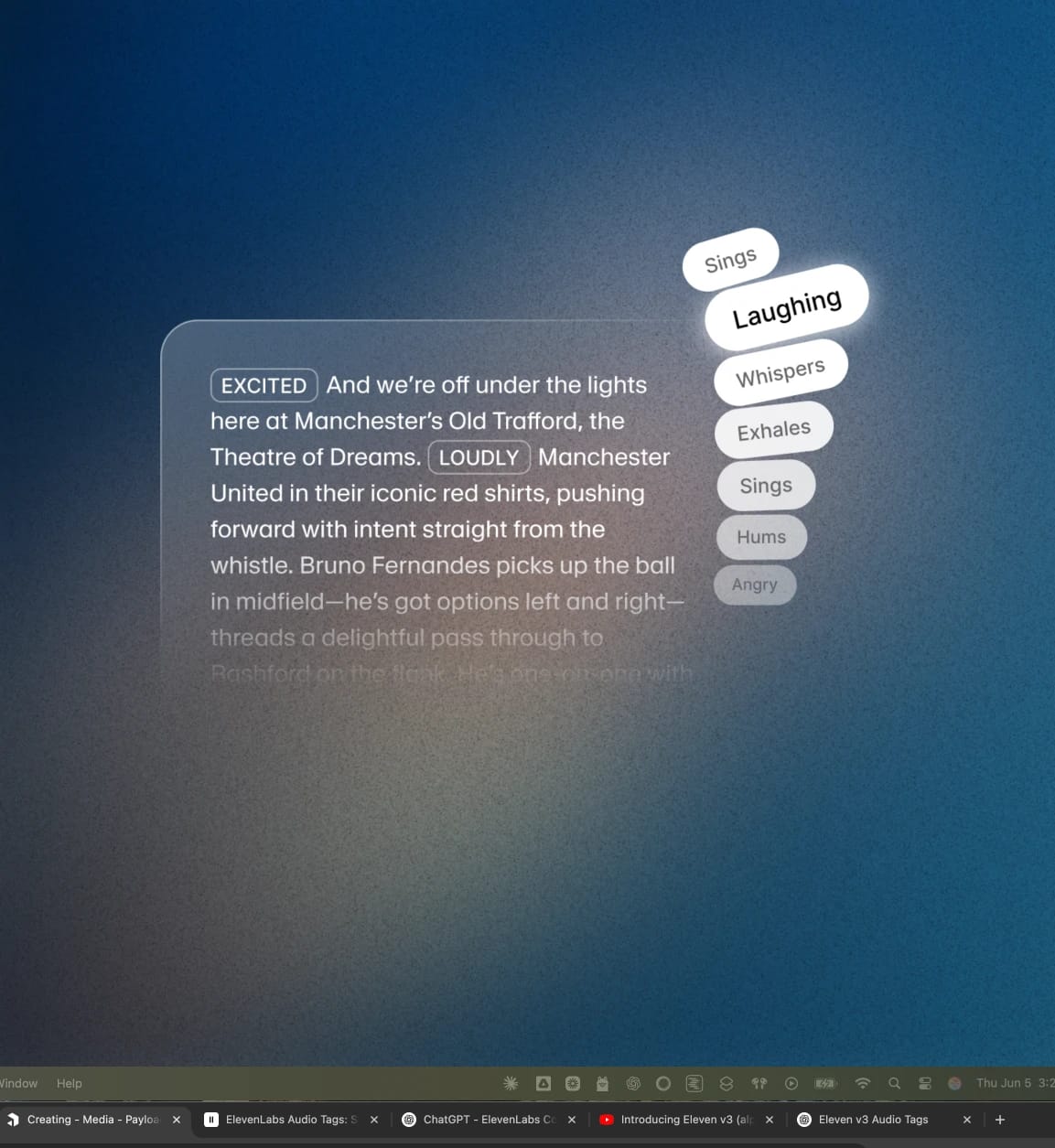
Mode Expressif ElevenAgents.Permet aux agents d’utiliser des balises expressives comme [rit], [chuchote], [soupire] ou [lentement] pour adapter la restitution au contexte.
ElevenAgents Mode Expressif.Permet aux agents d’utiliser des balises expressives comme [rit], [chuchote], [soupire] et [lentement] pour adapter la restitution au contexte.
Notre vision pour la suite
Beaucoup de conversations avec l’IA ressemblent encore à des requêtes. Les vraies conversations ne sont pas comme ça. Réduire cet écart, c’est notre mission.



