Framework de avaliação de agentes de voz: 6 pilares explicados
- Escrito por
- Jack Limebear
- Publicado
- Última atualização
OuvirOuça este artigo
Agentes de voz precisam coordenar várias ferramentas quase ao mesmo tempo. É um processo delicado: gravar os comentários do cliente com
Com tantas etapas envolvidas, como avaliar com precisão o desempenho de um agente de voz?
Neste artigo, vamos apresentar um framework de avaliação de agentes de voz baseado em seis pilares, mostrando exatamente o que medir para avaliar o sucesso do agente. Também vamos comentar por que diferentes setores devem dar pesos distintos a cada pilar e erros comuns ao avaliar.
Resumo
- Os seis principais pilares para avaliar agentes de voz são: qualidade da voz TTS, qualidade da conversa, uso de ferramentas e conclusão de tarefas, inteligência, conformidade e segurança, e confiabilidade.
- As principais metas de produção são um MOS de 4,3, TSR acima de 85% e tempo para o primeiro áudio abaixo de 500ms.
- Cada setor vai dar pesos diferentes para cada pilar, com algumas aplicações priorizando um mais que os outros.
- Erros comuns nos testes incluem avaliar apenas áudios limpos e ignorar picos de latência no P99.
- A ElevenLabs lidera nas métricas mais importantes: o Scribe v2 tem o menor WER do mercado, com 2,2% (Artificial Analysis, junho de 2026), Flash v2.5 e Turbo v2.5 são os modelos mais rápidos (Artificial Analysis, junho de 2026) e o ElevenAgents entrega latência de inferência de modelo de ~75ms.
O que é um framework de avaliação de agentes de voz?
Um framework de avaliação de agentes de voz IA é um sistema estruturado que permite testar o desempenho em várias dimensões. Um framework completo inclui métricas para avaliar desde a fidelidade do áudio até o fluxo da conversa e até mesmo conformidade regulatória.
Diferente de um chatbot de texto, um agente de voz passa cada interação por pelo menos três tecnologias: reconhecimento automático de fala (ASR), que converte as palavras do usuário em texto; um LLM que monta a resposta; e um sistema TTS que transforma essa resposta em áudio. Se qualquer um desses sistemas falhar, toda a experiência é prejudicada.
Essa complexidade é justamente o motivo pelo qual empresas precisam avaliar agentes de voz antes de escolher um fornecedor e implantar a solução. Qualquer latência extra ou resposta imprecisa pode gerar consequências reais, como perda de clientes ou, no pior caso, multas regulatórias e danos à reputação.
Um framework de avaliação de agentes de voz usa benchmarks e dados mensuráveis para definir se um agente é adequado para determinados casos de uso. Do ponto de vista do negócio, poder comparar diferentes modelos de voz permite escolher o melhor para seus clientes.
Os seis pilares para avaliar agentes de voz
Embora criar e implantar um agente IA nunca tenha sido tão simples, os processos ativos por trás disso são bastante complexos. Vários componentes atuam juntos para ouvir o usuário, entender o que ele quer, enviar essa informação para um LLM e depois gerar uma resposta em áudio, tudo quase ao mesmo tempo.
Para escolher o melhor agente de voz, as empresas precisam de um framework rigoroso para comparar.
Se você quer ver os resultados dos testes, então Análise Artificial oferece várias comparações de agentes com base em diferentes componentes. Abaixo, você pode ver os resultados do comparativo de velocidade entre modelos, com ElevenLabs Turbo v2.5 e Flash v2.5 liderando com folga em caracteres processados por segundo.
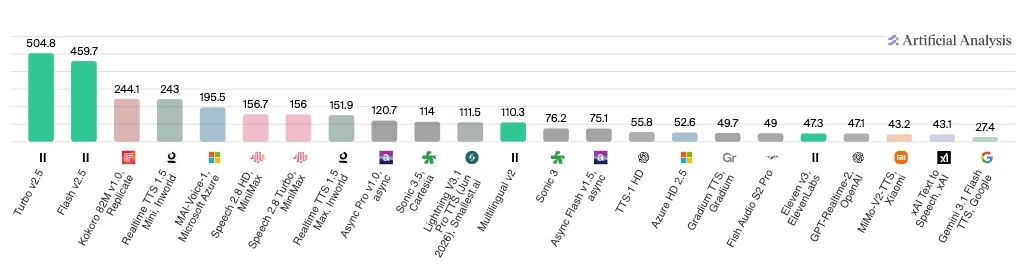
Para desenvolvedores ou empresas que querem fazer seus próprios testes, aqui estão os seis pilares de um framework de avaliação de agentes IA que você deve usar:
- Qualidade da voz TTS: Quão natural, clara e expressiva a fala sintetizada soa para o usuário final. Os melhores modelos do mercado, como Eleven v3, oferecem entrega emotiva e próxima da humana em mais de 70 idiomas.
- Qualidade da conversa: O modelo entende a fala humana, interpreta o significado e responde no contexto de forma rápida em várias interações?
- Uso de ferramentas: Até que ponto um agente IA consegue concluir tarefas usando os recursos disponíveis sem precisar de intervenção humana.
- Inteligência: Quão bem o modelo raciocina, lida com entradas novas e evita respostas imprecisas ou inventadas.
- Conformidade e segurança: Além de todas as funcionalidades,
- Confiabilidade: Componentes como tempo total de funcionamento e desempenho consistente sob carga para determinar se um agente de IA conversacional consegue escalar conforme a demanda.
Embora cada pilar seja independente, eles se conectam para entregar uma experiência final de alta qualidade para o usuário. Por exemplo, se um modelo melhora a qualidade da voz mas ainda tem alta latência, o cliente vai sentir um tempo de espera desconfortável antes de ouvir a resposta.
Vamos explorar cada um desses pilares de avaliação de voz IA em mais detalhes.
Qualidade da voz TTS
Começamos pela qualidade da voz, pois é provavelmente o primeiro aspecto que uma pessoa percebe ao interagir com um agente conversacional IA. Se soar robótico ou estranho, a experiência subjetiva será bem pior.
Uma das métricas originais de avaliação, definida pela União Internacional de Telecomunicações (ITU-T), é o Mean Opinion Score (MOS). O MOS vai de 1 a 5, sendo 1 inutilizável e 5 excelente. Como é uma medida subjetiva, usa ouvintes humanos e coleta feedback após uma chamada.
Qualquer valor abaixo de MOS 3,5 nessa escala é pouco impressionante, especialmente pelos padrões atuais, e provavelmente vai impactar a satisfação do cliente.
Embora o MOS seja uma métrica centrada no humano, vários requisitos técnicos influenciam esse resultado:
- Consistência de tom e jitter: Tom e jitter são dois elementos linguísticos que os humanos percebem naturalmente ao ouvir. “Tom” se refere à variação de entonação ao longo da fala, como quando você eleva a voz ao fazer uma pergunta. Jitter é quando o modelo de voz não mantém o tom de forma consistente, dificultando a prosódia ao longo da frase. O padrão do setor para jitter é 30ms.
- Expressividade emocional: Uma voz clara e precisa ainda soa estranha se o tom não combina com a emoção da frase. Sem sinais tonais corretos, ouvintes humanos sentem menos empatia pelos agentes IA e os avaliam pior. O ElevenAgents oferece expressividade quase humana para combinar cada resposta com a intenção emocional adequada.
- Ruído de fundo: O ruído de fundo em agentes de voz tem dois aspectos importantes. Na saída, ruídos ambientes podem ser adicionados para deixar a resposta mais natural. Na entrada, o filtro de ruído na camada STT é uma opção que melhora a precisão. Ao avaliar um agente, teste ambos: veja se o ruído ambiente soa natural e avalie a precisão do STT com e sem o filtro de ruído.
Ao calcular o MOS, o ideal é buscar entre 4,3 e 4,5, o que mostra notas altas em todas essas categorias perceptivas. Para prever MOS em escala sem painéis humanos, você pode usar ferramentas como UTMOS e NISQA.
Qualidade da conversa
A qualidade da conversa é um pilar que fica entre a qualidade da voz e a conclusão de tarefas. Mede o quanto o agente de voz entende as necessidades do usuário, pode interrompê-lo no contexto certo e manter o diálogo até o fim.
A principal métrica aqui é a precisão na classificação de intenção, normalmente entre 85% e 92%, com os melhores chegando a 96% ou mais. Embora 85% pareça alto, ainda significa que 15% das interações são classificadas errado e encaminhadas para recursos inadequados.
Os elementos técnicos que contribuem para alta precisão na classificação de intenção são:
- Troca de turnos: Turn-taking avalia como o agente de voz gerencia o fluxo natural da conversa. Mede se ele sabe quando ouvir, responder ou esperar mais informações. Também inclui lidar com interrupções, quando o modelo cancela uma resposta em andamento e gera uma nova com base na entrada recente. A ElevenLabs usa um websocket multi-contexto para lidar com essas interrupções de forma fluida.
- Latência: Latência é o tempo entre o usuário terminar de falar e o agente começar a responder em áudio. Agentes de voz prontos para produção devem buscar tempo para o primeiro áudio abaixo de 500ms, sendo menos de 300ms o ideal. Os modelos Flash da ElevenLabs oferecem tempo de inferência líder do setor, com ~75ms, garantindo ótimos resultados nessa categoria.
- Taxa de fallback: A taxa de fallback mede quantas vezes o agente IA não entende o usuário e pede esclarecimento ou repetição. Isso está ligado à precisão do STT: se a camada de reconhecimento de fala entende errado, o LLM recebe uma entrada corrompida. A taxa de fallback é calculada assim: Taxa de fallback (%) = (Número de fallbacks / Total de interações) * 100.
O Scribe V2 da ElevenLabs tem o menor WER, com 2,2%, na avaliação de modelos de speech to text da Artificial Analysis
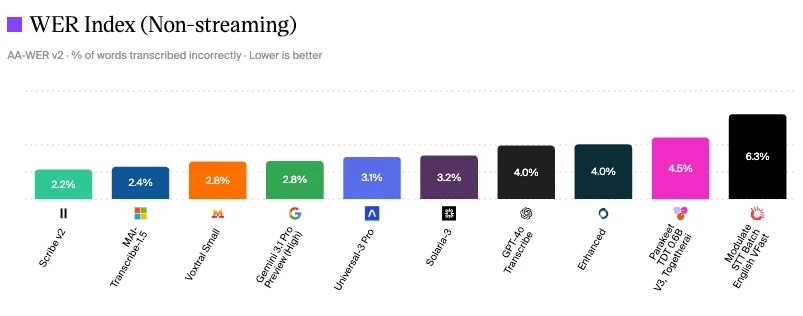
Avaliação de modelos de speech to text da Artificial Analysis
Uma forma de medir a qualidade da conversa é olhando para benchmarks do setor para diferentes componentes. Como você pode ver, o Scribe v2 da ElevenLabs tem o menor índice de erro de palavras, com 2,2% em junho de 2026, o que significa menos erros de compreensão, menos fallbacks e classificação de intenção mais precisa.
Empresas podem perceber que a qualidade da conversa também depende do workflow em que o agente de voz atua. Por exemplo, no atendimento ao cliente, outro ponto importante seria a qualidade do repasse para humanos ou a resolução de FAQs.
Uso de ferramentas e conclusão de tarefas
Enquanto a qualidade mede como foi a conversa, a conclusão de tarefas mostra se ela levou a um resultado de sucesso. Empresas devem prestar atenção especial a essa parte do framework, pois está diretamente ligada aos resultados do negócio.
Uma forma de medir o uso de ferramentas é a precisão no preenchimento de campos (slot-fill), que mostra o quanto o agente IA consegue executar tarefas rotineiras, como preencher um formulário com dados do cliente. Alta precisão nesse ponto indica que o agente consegue passar da conversa para a ação sem perder informações.
A Taxa de Sucesso de Tarefas (TSR) é uma métrica percentual de quantas tarefas de ponta a ponta foram concluídas com sucesso pelo agente. A conclusão depende da capacidade do agente de entender o pedido e usar as ferramentas certas (APIs, bancos de dados, RAG e bases de conhecimento internas) para ajudar.
A fórmula do TSR é:
TSR = (Tarefas totalmente concluídas / Total de tarefas tentadas) x 100
Agentes de voz prontos para produção devem buscar TSR acima de 85%, monitorando a precisão e confiabilidade das chamadas de ferramentas. Para evitar queda no TSR, faça testes de regressão sempre que alterar prompts ou modelos conectados. Mesmo pequenas mudanças podem ter grande impacto no TSR.
Inteligência
A inteligência reflete o raciocínio e as capacidades avançadas do agente de voz. É esse pilar que diferencia um IVR tradicional de um agente de voz com IA.
Dimensões principais para avaliar aqui incluem:
- Risco de alucinação: Alucinações, quando o agente gera informações imprecisas ou inconsistentes com documentos da empresa, são especialmente problemáticas em voz IA, pois podem ser transmitidas com confiança.Estudos recentes sugerem que alucinações comuns prejudicam bastante a satisfação do cliente com agentes de voz.
- Tratamento de perguntas fora do escopo: Agentes inteligentes entendem quando uma pergunta está fora do seu domínio e sabem responder de forma adequada. Em vez de inventar uma resposta, eles recusam ou redirecionam a conversa para um tema mapeado.
- Retenção de contexto: Em várias interações, o agente consegue acompanhar entidades e compromissos feitos antes? Sem essa habilidade, o cliente pode ter que repetir informações ou receber respostas contraditórias.
- Raciocínio e lógica em múltiplas etapas: O agente consegue lidar com lógica condicional ou encadear inferências em várias interações? Especialmente em casos mais técnicos, como serviços financeiros, a capacidade de raciocinar dentro de um contexto definido é essencial para o sucesso.
Existem vários benchmarks de terceiros para essas dimensões. Por exemplo, o HELM da Stanford avalia o desempenho de LLMs em diferentes categorias. Para alucinações, o TruthfulQA analisa com que frequência respostas falsas aparecem.
Uma vantagem do ElevenAgents é que, diferente de algumas plataformas de voz que te prendem a um único modelo, você pode trocar totalmente a camada LLM. Na prática, isso significa que você pode usar o modelo que lidera nos benchmarks de raciocínio para o seu caso de uso.
Conformidade e segurança
Empresas precisam implementar barreiras ativas para evitar respostas prejudiciais ou que violem políticas. Diferente de instruções de prompt no sistema, que podem ser contornadas, verificações independentes de segurança rodam em uma camada separada do modelo. Elas avaliam as respostas antes de chegar ao usuário e interrompem a conversa se sair do permitido.
Auditabilidade é outro requisito importante: agentes em produção precisam manter registros detalhados de decisões e respostas em formato que permita revisão posterior. Em setores altamente regulados, comprovar conformidade depois é tão importante quanto alcançá-la desde o início.
As regras que sua empresa precisa seguir vão variar conforme o setor. Alguns dos frameworks mais comuns são:
- HIPAA: Para dados de saúde protegidos nos EUA.
- PCI-DSS: Para qualquer agente que lide com dados de cartão de pagamento.
- LGPD: Obrigações de privacidade de dados para o Brasil, UE e empresas com clientes na UE.
Para empresas avaliando sua postura de conformidade, a ElevenLabs possui certificação SOC Tipo II da AICPA e conformidade com a LGPD, além de ter conquistado a certificação AIUC-1. O AIUC-1 é um padrão de segurança criado especialmente para agentes de IA.
Confiabilidade
Confiabilidade é o último pilar do nosso framework, cobrindo se o agente consegue entregar resultados consistentes em tempo real.
Ao avaliar um agente de voz, procure pelas seguintes características:
- Disponibilidade: Qualquer implantação voltada para o cliente espera 99,9% de disponibilidade para evitar quedas. Especialmente em casos de uso 24/7, como suporte receptivo, alta disponibilidade é fundamental.
- Degradação controlada: Devido à complexidade dos agentes de voz, se algum componente falhar, o agente deve lidar com isso de forma controlada. Na prática, isso significa encaminhar para um humano, em vez de continuar funcionando com erros ou sobrecarga.
- Desempenho sob carga: Testes de carga devem simular pelo menos o dobro do pico esperado de uso antes de entrar em produção. Testar sob pressão ajuda a identificar aumentos de latência ou queda de desempenho que só aparecem em escala.
Mesmo um modelo de alta qualidade pode ser inviável se não escalar conforme a demanda dos clientes. O ElevenAgents é usado por mais de 1.000.000 de criadores e empresas líderes, mostrando que a plataforma suporta implantação em escala empresarial sem comprometer os benchmarks de desempenho.
Como medir MOS para agentes de voz (passo a passo)
Se sua empresa quiser medir o MOS manualmente, será preciso um grupo grande de ouvintes humanos e uma seleção de áudios de conversas reais. É um processo estruturado que envolve coletar feedback, calcular médias e interpretar os dados.
Veja como medir o MOS para agentes de voz na prática:
- Prepare seu conjunto de testes: Selecione uma amostra representativa de áudios do seu agente, com pelo menos 100 clipes de diferentes conversas.
- Realize a sessão de avaliação: Peça para os ouvintes humanos avaliarem cada clipe numa escala de 1 a 5, considerando a qualidade da experiência de comunicação.
- Agregue as notas e calcule os resultados: Tire a média das notas de cada clipe e depois a média geral para obter o MOS. Um MOS de 4,3 ou mais indica que seu agente de voz está pronto para produção.
Apesar de trabalhoso, esse processo oferece um MOS sólido para o agente escolhido. Se quiser testar em escala, você pode substituir ouvintes humanos por ferramentas automáticas como o NISQA, que prevê o MOS de forma programática. Dá para integrar esses sistemas ao seu fluxo para monitorar o MOS continuamente.
Benchmarks de IA vs. humanos: FCR, AHT e CSAT
Calcular o MOS ao longo do tempo mostra evolução ou regressão do modelo, mas você pode trazer mais contexto comparando com o desempenho humano. Ver o que humanos realmente alcançam em funções similares mostra se seu agente de voz está perto do ideal.
Aqui estão algumas métricas para considerar ao comparar IA e humanos.
Agentes IA devem igualar FCR e CSAT humanos, melhorando bastante o AHT. Essa melhoria ocorre porque agentes IA normalmente lidam com conversas mais gerais que agentes humanos. Muitas empresas usam um fluxo onde agentes IA atendem primeiro, repassando para humanos apenas casos mais complexos.
Dados de 2025 do Poe, agregador de comparação de IA, mostram que a ElevenLabs manteve a maior capacidade de atender pedidos, completando 74,4% de todas as solicitações recebidas. Esse sucesso levou a um rápido crescimento de uso, com Eleven v3 e v2.5-Turbo respondendo por mais de 60% das mensagens enviadas para modelos de IA ao longo do tempo.
Mensagens enviadas para modelos de IA ao longo do tempo, ElevenLabs liderando o framework de avaliação de agentes de voz do Poe
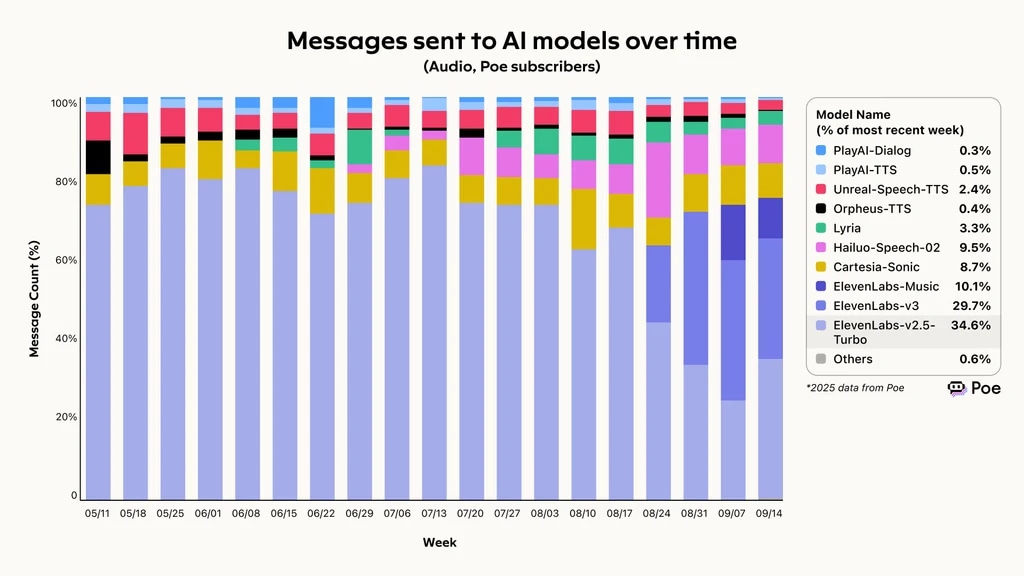
Mensagens enviadas para modelos de IA ao longo do tempo, segundo o benchmark do Poe
Erros comuns ao testar agentes de voz
Ao seguir um framework de avaliação de agentes de voz, é tentador testar apenas cenários ideais. Mas, na prática, a experiência diária dos clientes com seus sistemas de voz IA não acontece em condições perfeitas.
Veja três erros comuns ao testar agentes de voz e como corrigi-los:
- Testar apenas o caminho mais fácil: Especialmente ao escolher áudios para o MOS, inclua casos extremos. Clipes com ruído de fundo ou sotaques são muito comuns na vida real, então testar só com áudios 'limpos' vai distorcer o MOS.
- Priorizar contenção em vez de resolução: Otimizar modelos para manter usuários no sistema aumenta a taxa de contenção sem melhorar resultados. Se seu FCR é baixo mesmo com alta contenção, o agente está prendendo usuários em um ciclo frustrante. Tenha práticas para permitir que o usuário fale com um humano se quiser.
- Ignorar percentis de latência: SLAs normalmente usam latência no P95. Embora isso seja importante para a maioria dos clientes, não esqueça que os 5% finais também são clientes reais. Em escala, 5% de um sistema com 10.000 chamadas diárias ainda são 500 pessoas tendo uma experiência lenta. Foque no P99 como meta principal de SLA, não só na mediana ou P95.
Seguindo essas dicas, você consegue estabelecer referências justas e representativas, em vez de trabalhar com médias idealizadas.
A importância de avaliações específicas por caso de uso
Embora os seis pilares deste framework sirvam de guia, o peso de cada um depende do seu setor. Por exemplo, uma empresa de serviços financeiros pode priorizar conformidade e uso de ferramentas, enquanto uma marca de consumo vai focar na qualidade da voz TTS.
Veja dois exemplos de avaliações específicas por caso de uso e como elas mudam o peso de cada pilar.
Suporte ao cliente
Em setores como call centers, outras métricas de conclusão de tarefas, como First Call Resolution (FCR), são muito importantes. Conseguir resolver uma chamada sem intervenção humana reduz bastante a demanda sobre os atendentes.A McKinsey estima que call centers com agentes de voz podem reduzir o volume de interações em até 50%.
Embora não seja tão importante quanto a taxa de sucesso de tarefas, outra métrica relevante é a taxa de contenção. Ela mede a duração total da chamada. Se a taxa de contenção é alta mas o FCR é baixo, os agentes estão segurando o cliente na linha sem resolver o problema, o que pode ser frustrante.
Outras métricas para acompanhar são o AHT, com agentes IA buscando resolver problemas rotineiros rapidamente. Por isso, o suporte ao cliente tende a priorizar qualidade da conversa, especialmente turn-taking e taxa de fallback, acima de outros pontos.
Saúde
Saúde é um setor altamente regulado, com exigências rigorosas de conformidade que tornam a operação de agentes de voz muito delicada. Conformidade é a principal preocupação, dando muito mais peso ao pilar de segurança e inteligência.
Chatbots de saúde precisam lidar com agendamento de consultas, acesso à telemedicina, triagem de sintomas e dúvidas sobre seguros. Tudo isso exige alto grau de inteligência e uso de ferramentas, mostrando novamente que demandas específicas do setor influenciam qual pilar é mais importante.
Independentemente do setor, entender os pilares centrais da avaliação de agentes de voz e aplicá-los de forma equilibrada vai ajudar você a encontrar os melhores agentes para o seu negócio.
Construa com ElevenAgents para alta performance e baixa latência
A plataforma que você escolhe para construir influencia diretamente o desempenho dos seus agentes de voz em fluxos reais. Principalmente ao interagir com seus clientes, é importante ter confiança de que seu agente vai se destacar em todas as categorias.
O ElevenAgents foi criado para implantações de voz em produção, combinando TTS líder do setor com o Eleven v3, STT em tempo real com o Scribe v2, e uma camada de orquestração de agentes pensada para escala empresarial. Cada componente é projetado para atender aos benchmarks deste framework, permitindo que você entregue experiências de alta qualidade aos seus clientes.
Seja para comparar opções ou começar a construir, a ElevenLabs tem um caminho para você. Explore a plataforma ElevenAgents para ver como ela se encaixa no seu caso de uso, ou crie sua conta e comece a construir hoje mesmo.




