Que sont les Audio Tags Eleven v3 — et pourquoi ils comptent
- Rédigé par
- Ryan Morrison
- Publié
- Dernière mise à jour
ÉcouterÉcouter cet article
Avec la sortie de Eleven v3, le prompt audio devient une compétence essentielle. Au lieu de simplement écrire ou coller le texte à faire lire par la voix IA, vous pouvez maintenant utiliser une nouvelle fonctionnalité — Tags audio — pour tout contrôler, de l’émotion à l’interprétation.
Eleven v3 est une version alpha aperçu de recherche du nouveau modèle. Il demande plus de prompt engineering que les versions précédentes — mais les résultats sont bluffants.
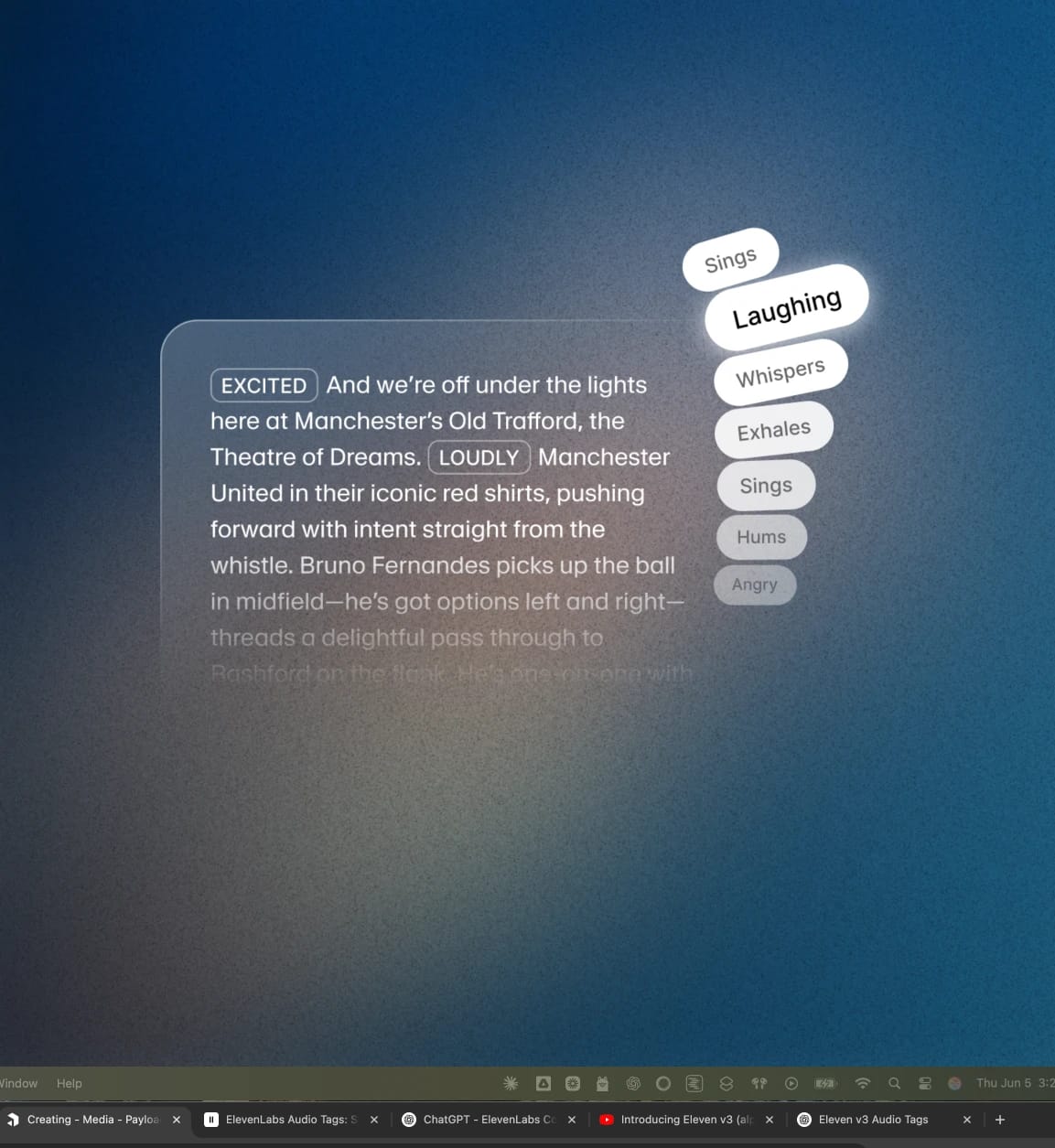
Les Audio Tags ElevenLabs sont des mots entre crochets que le nouveau modèle Eleven v3 peut interpréter pour guider l’action sonore. Cela peut aller de [excité], [chuchote], [soupire] à [coup de feu], [applaudissements] ou [explosion].
Les balises audio vous permettent de façonner le rendu des voix IA, y compris les indices non verbaux comme le ton, les pauses et le rythme. Que vous créiez des
Diriger l’interprétation avec les Audio Tags
Vous pouvez placer des Audio Tags n’importe où dans votre script pour ajuster l’interprétation en temps réel. Il est aussi possible de combiner plusieurs tags dans un même script ou même une phrase. Les tags se répartissent en grandes catégories :
Émotions
Ces tags vous aident à définir le ton émotionnel de la voix — qu’il soit sombre, intense ou enjoué. Par exemple, vous pouvez utiliser un ou plusieurs de [triste], [en colère], [joyeusement] ou [affligé].


Indications d’interprétation
Ces tags concernent davantage le ton et la performance. Utilisez-les pour ajuster le volume et l’énergie selon la scène, qu’elle soit retenue ou énergique. Exemples : [chuchote], [crie] ou même [accent x].


Réactions humaines
Une parole naturelle inclut des réactions. Vous pouvez ainsi ajouter du réalisme en intégrant des moments spontanés dans la voix. Par exemple : [rit], [se racle la gorge] ou [soupire].


Basé sur un modèle plus expressif
Derrière ces fonctionnalités se trouve la nouvelle architecture de v3. Le modèle comprend le contexte du texte de façon plus approfondie, ce qui lui permet de suivre plus naturellement les émotions, les changements de ton et les transitions entre les intervenants. Combiné aux Audio Tags, cela offre une expressivité bien supérieure à ce qui était possible auparavant dans
Vous pouvez aussi désormais créer des dialogues multi-interlocuteurs qui semblent spontanés — avec interruptions, changements d’humeur et nuances de conversation, le tout avec un minimum de prompt.
Disponible dès maintenant
Les clones de voix professionnels (PVC) ne sont pas encore totalement optimisés pour Eleven v3, ce qui peut entraîner une qualité de clonage inférieure par rapport aux modèles précédents. Pendant cette phase de prévisualisation, il est préférable de choisir un
Eleven v3 est disponible dans l’interface ElevenLabs, et nous proposons 80% de réduction jusqu’à fin juin. L’API publique pour Eleven v3 (alpha) est aussi disponible. Que vous testiez ou que vous déployiez à grande échelle, c’est le moment d’explorer les possibilités.
Créer des Audio Tags

Créer une voix IA qui interprète — et ne fait pas que lire — repose sur la maîtrise des Audio Tags. Nous avons préparé sept guides courts et pratiques pour montrer comment des tags comme [CHUCHOTE], [RIT DOUCEMENT], ou [accent français] vous permettent de gérer le contexte, l’émotion, le rythme et même les dialogues multi-personnages avec un seul modèle.
Découvrir la série
- Contexte situationnel – Des tags comme
[CHUCHOTE],[CRIE], et[SOUPIRE]permettent à Eleven v3 de réagir à la situation — pour accentuer la tension, adoucir un avertissement ou marquer une pause. - Interprétation de personnage – De
[voix de pirate]à[accent français], les tags transforment la narration en jeu de rôle. Changez de personnage en cours de phrase et dirigez des interprétations complètes sans changer de modèle. - Contexte émotionnel – Des indices comme
[soupire],[enthousiaste], ou[fatigué]guident les émotions à chaque instant, ajoutant tension, soulagement ou humour — sans réenregistrement. - Intelligence narrative – Raconter, c’est aussi gérer le rythme. Des tags comme
[pause],[émerveillé], ou[ton dramatique]contrôlez le rythme et l’accentuation pour que - Dialogue multi-personnages – Écrivez des répliques qui se chevauchent ou des échanges rapides avec
[interrompt],[superposé], ou des changements de ton. Un seul modèle, plusieurs voix — une conversation naturelle en une seule prise. - Contrôle de l’interprétation – Ajustez précisément le rythme et l’accent. Des tags comme
[pause],[pressé], ou[étiré]permettent de moduler le tempo et de transformer un texte simple en véritable performance. - Imitation d’accent – Changez de région à la volée —
[accent américain],[accent britannique],[accent du sud des États-Unis]et bien d’autres — pour une parole riche culturellement, sans changer de modèle.
.webp&w=3840&q=80)
.webp&w=3840&q=80)
