

























Wir haben die Preise für API & Agents gesenkt und Pay-as-you-go eingeführt
- Kategorie
- Unternehmen
- Datum
Vertrauen von über 1 Mio. Nutzern • Kostenlos starten



Erzählung
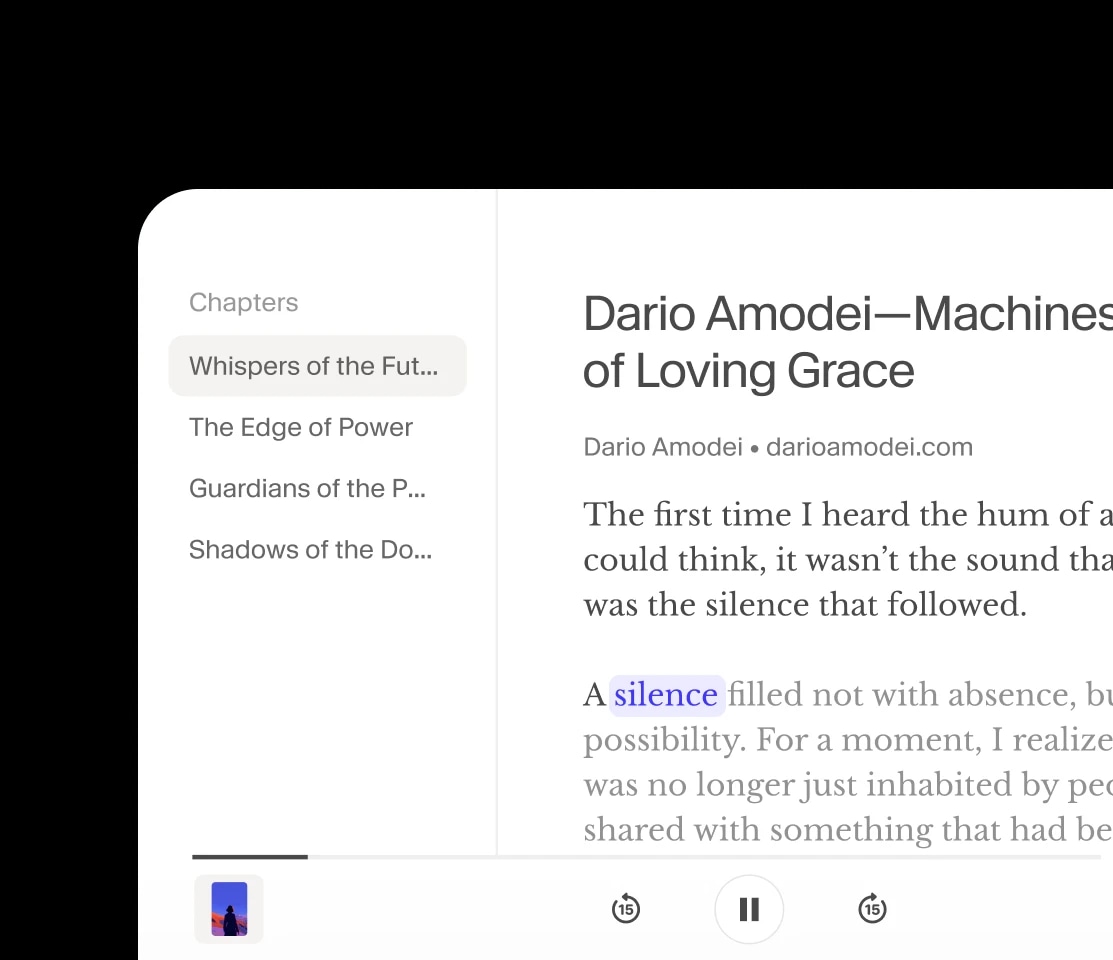
Ausdrucksstarke Stimmen, die Hörbücher und Podcasts zum Leben erwecken
Werbung
Überzeugende Stimmen, die zum Handeln anregen und Marken im Gedächtnis halten.
Charaktere
Lebendige, unterhaltsame Stimmen für Cartoons und Videospiele.
Erzählung
Ausdrucksstarke Stimmen, die Hörbücher und Podcasts zum Leben erwecken
Konversation
Natürliche Stimmen, ideal für informelle Szenarien.
Soziale Medien
Trendige, aufmerksamkeitsstarke Stimmen für Kurzform-Inhalte

Erstellen Sie steuerbare, ausdrucksstarke Sprache mit Emotionen, Audio-Events und immersiven Klanglandschaften.
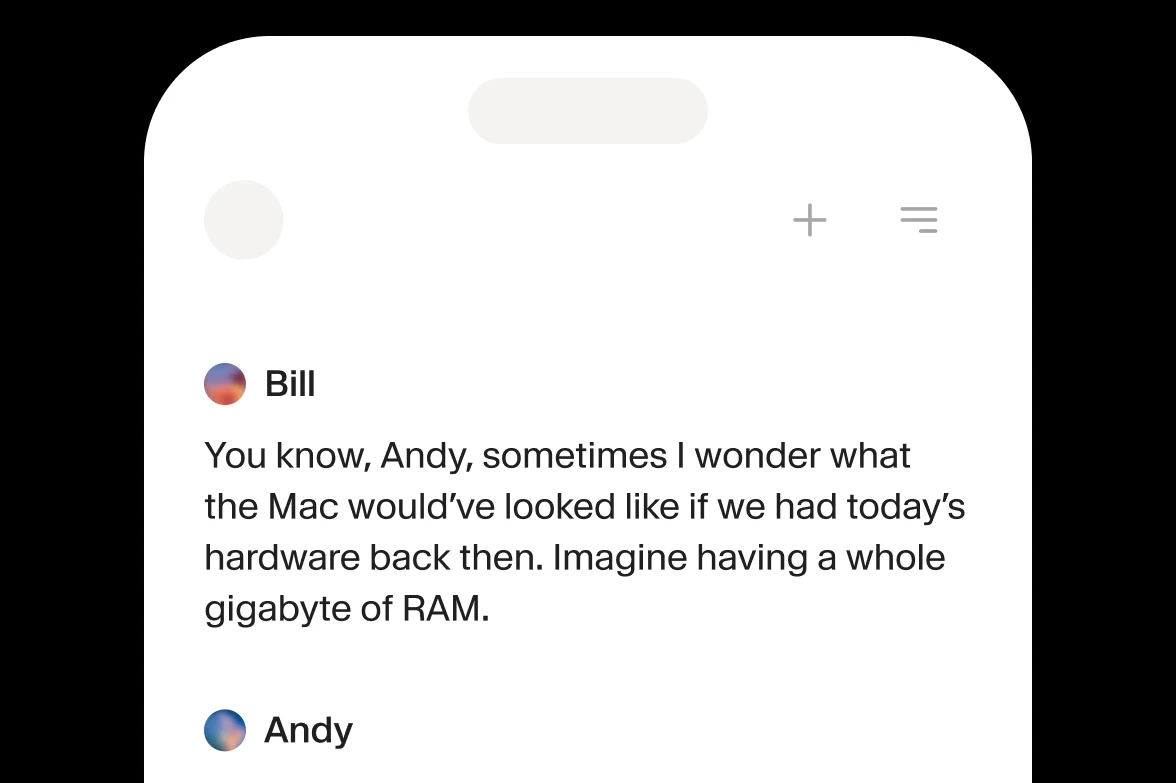
Die Stimme hielt einen Moment inne, [leise] als ob sie ihre Gedanken sammelte, bevor sie fortfuhr. Jeder Atemzug wirkte absichtlich, jede Zögerung perfekt getimt.
Das war keine synthetische Sprache mehr [lacht herzlich] - es war eine Stimme, die Timing, Emotion und den Raum zwischen den Worten verstand.
Text verwandelte sich in Präsenz. [seufzt zufrieden] Worte erhielten Leben, Persönlichkeit, Seele.
Entdecken Sie eine stetig wachsende Sammlung ausdrucksstarker, lebensechter Stimmen für jeden Anwendungsfall – von Erzählungen bis zur Charaktergestaltung.
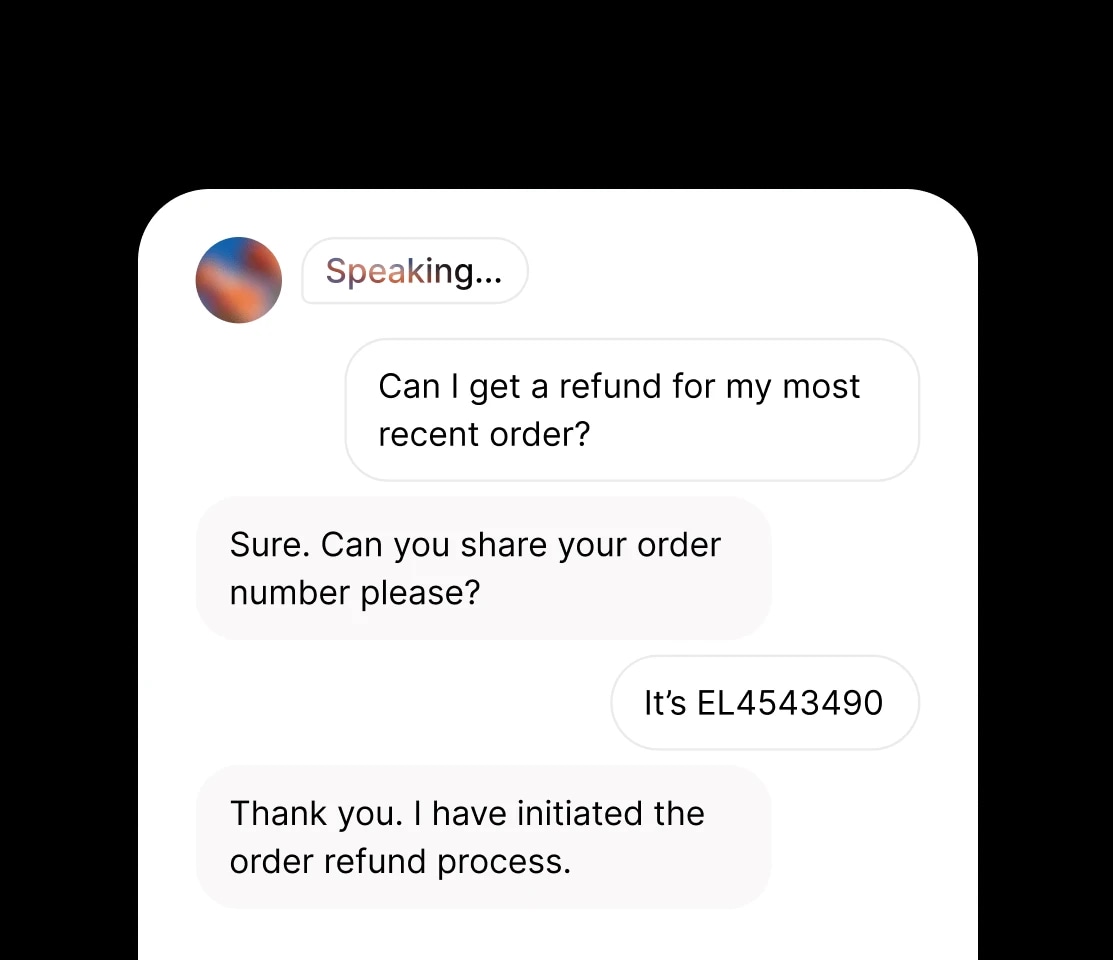
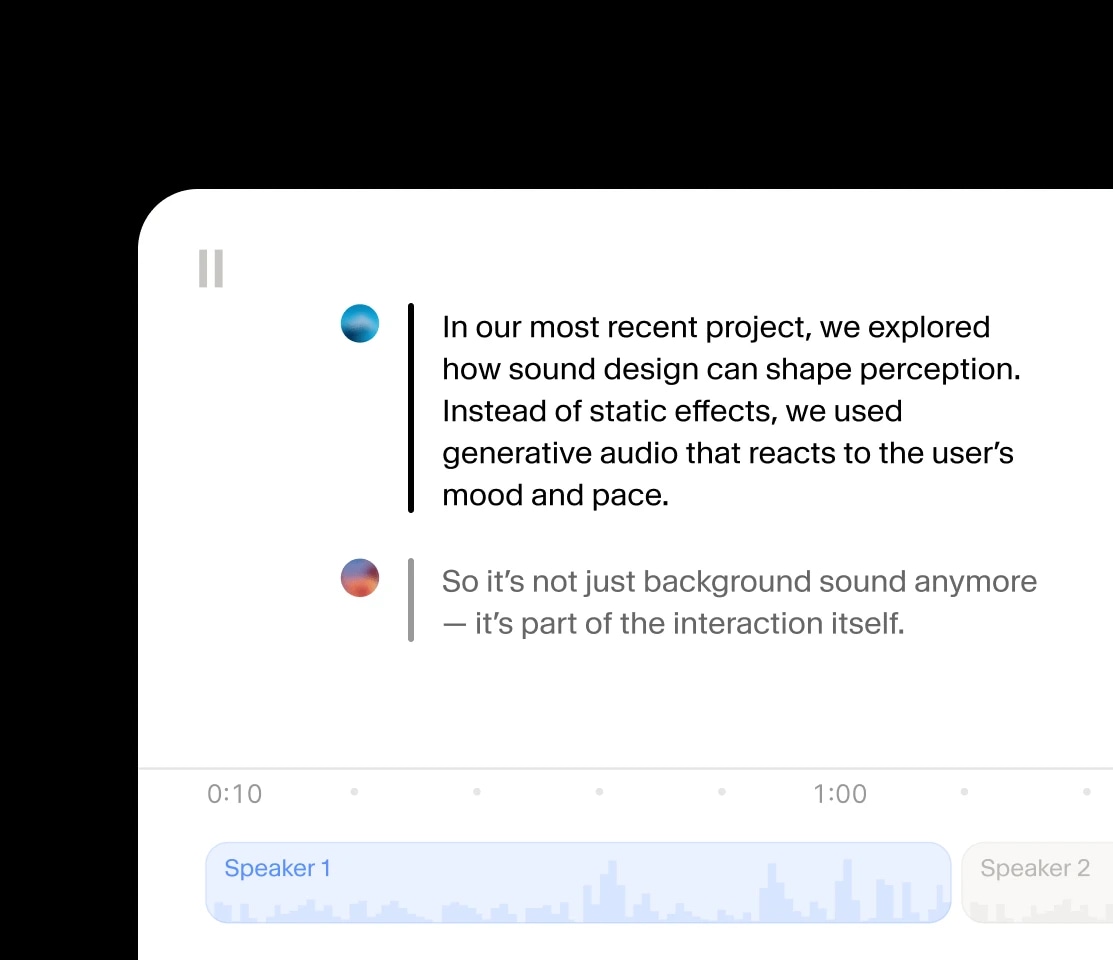
Erstellen Sie Audiogespräche, in denen Sprecher Kontext und Emotionen teilen.
Replizieren Sie Ihre eigene Stimme sofort oder gestalten Sie einzigartige KI-Stimmen mit voller Kontrolle.
Erwecken Sie Geschichten in über 70 Sprachen zum Leben – mit natürlicher Emotion und Klarheit.



Unser fortschrittlichstes, ausdrucksstärkstes Modell mit Audio-Tags für präzise Emotionssteuerung. Ideal für Storytelling, Gaming und Medienproduktion in über 70 Sprachen.

Unser lebensechtestes, emotional reiches Text zu Sprache-Modell mit Unterstützung für 29 Sprachen. Optimal für Voiceovers, Hörbücher, Postproduktion und Content-Erstellung.

Unser hochwertiges, latenzarmes TTS-Modell in 32 Sprachen. Ideal für Entwickler, wenn Geschwindigkeit zählt und Sie nicht-englische Sprachen benötigen.

Hochwertiges, latenzarmes Modell mit ausgewogenem Verhältnis von Qualität und Geschwindigkeit

Die besten KI-Audiomodelle in einem leistungsstarken Editor.

Erzeugen Sie ausdrucksstarkes Audio in Sekunden mit unseren iOS- und Android-Apps.
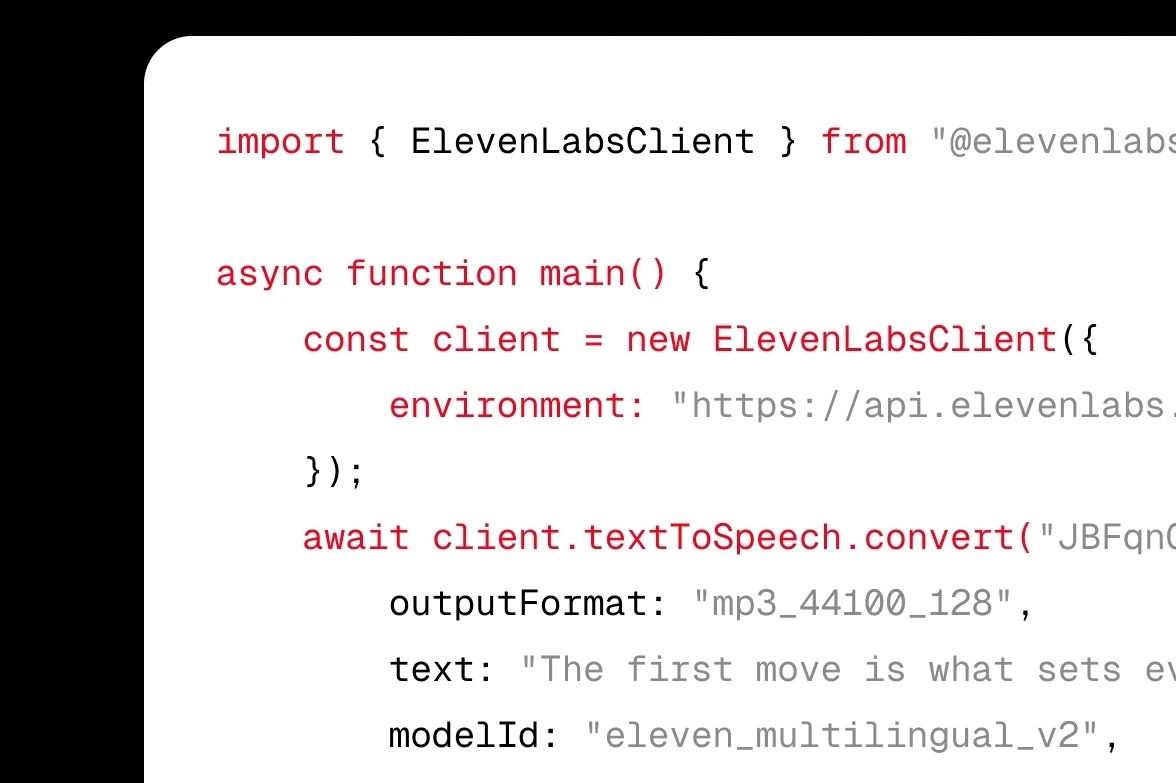
Integrieren Sie ElevenLabs Text zu Sprache (TTS) per API oder SDK in Ihr Produkt.





%20(1).webp&w=3840&q=80)

