Verarbeitung von Bildern und Dokumenten in ElevenAgents
- Verfasst von
- Francesca Peñaranda Roy
- Veröffentlicht
- Zuletzt aktualisiert
AnhörenArtikel anhören
Ein Bauleiter bemerkt einen Materialmangel auf der Baustelle. Er fotografiert die Situation, sendet das Bild per WhatsApp an den Einkaufsagenten und bestätigt die Lieferadresse per Spracheingabe. Der Agent verarbeitet das Foto, erkennt das fehlende Material und löst eine Expressbestellung aus – alles in einem Gespräch. Unternehmensprozesse enthalten oft Kontext, der sich nicht allein mit Worten vermitteln lässt. Die Informationen zur Bearbeitung einer Anfrage können als Foto eines beschädigten Teils oder als PDF einer Richtlinie vorliegen. Werden diese direkt an den Agenten übergeben, verkürzt das das Gespräch und beschleunigt die Lösung. Kann ein Kunde etwas zeigen statt beschreiben, kann der Agent schneller reagieren, ohne einen Kanalwechsel zu verlangen.Rohlik, eine der größten Online-Supermarkt-Plattformen Europas, betreibt seinen Agenten über Telefon, Web, App und WhatsApp in sechs Sprachen und löst 90 % der Kundenanfragen automatisch. Multimodale Eingaben ermöglichen diese Auflösungsrate auch in Situationen, in denen Kunden etwas zeigen müssen. ElevenAgents behandelt Dateien als gleichwertige Eingaben im selben Agenten, der bereits Sprache, WhatsApp, Web und Mobile verarbeitet. Dateien erreichen das zugrundeliegende Modell als native Nachrichten, sodass ein einziger Agent alle Eingabetypen in einem Gesprächsverlauf abwickelt.
Dieser Beitrag erklärt, was Multimodalität auf der Plattform bedeutet, wie Dateien vom Gerät des Kunden in den Modellkontext gelangen, welche Kanäle was unterstützen und wie Kontext über Sitzungen hinweg erhalten bleibt.
Kanäle und Eingaben
ElevenAgents ist auf die Kanäle ausgerichtet, die Unternehmen bereits nutzen, um Kunden zu erreichen: Web- und Mobile-Anwendungen, Support-Plattformen, Telefon, SMS, E-Mail, WhatsApp und weitere. Die Agenten-Konfiguration (Prompt, Modell, Tools, Wissensdatenbank und Stimme) wird einmal definiert und für alle Kanäle verwendet. Zwei Dinge unterscheiden sich je Kanal: die Transportschicht und die unterstützten Eingabetypen. Web- und Mobile-Anwendungen verbinden sich über das einbettbare Widget, eines der SDKs oder den Agents WebSocket. Telefongespräche werden über native Twilio-, SIP-Trunking- oder native websocket-basierte
Dateieingaben (Bilder und PDFs) werden derzeit auf Web, Mobile und WhatsApp unterstützt. Die Verarbeitung erfolgt typbasiert, nicht kanalbasiert: Ein Foto und eine Sprachnachricht, die in derselben WhatsApp-Sitzung eingehen, laufen durch unterschiedliche Pipelines, bevor sie das Modell erreichen. Unabhängig von Kanal oder Eingabetyp laufen alle Eingaben auf derselben Vorverarbeitungsschicht zusammen, bevor sie dem Modell als nativer Kontext übergeben werden. Dort folgen sie einem von zwei Pfaden.
Eingabedarstellung: dateibasiert vs. inline
Unabhängig von Eingabetyp oder Kanal normalisiert die Plattform jede Eingabe in eine von zwei internen Darstellungen, bevor sie an das Modell übergeben wird. Diese Klassifizierung bestimmt, wie die Eingabe im Kontextfenster des Modells kodiert wird und was Ihre Integration im Vorfeld leisten muss.
Dateibasierte Eingaben
Bilder und PDFs werden dem Modell als native Dateireferenzen übergeben, nicht als Textzusammenfassungen. Die Plattform speichert die Datei, vergibt einefile_idund verknüpft diese Kennung mit dem Nutzerbeitrag. Ein visuelles oder dokumentenfähiges Modell erhält die Rohdatei im Kontextfenster, nicht eine abgeleitete Darstellung. Die Integrationsanforderung ist einfach: Erfassen Sie diefile_id, die vom Upload-Endpunkt zurückgegeben wird, und fügen Sie sie der Nachrichten-Payload hinzu. Wird die Nachricht ohnefile_idgesendet, hat das Modell keinen Bezug zur Datei, auch wenn der Upload erfolgreich war. Die Dateispeicherung ist auf die jeweilige Konversation begrenzt. Alles, was über die Sitzung hinaus bestehen soll (Datei selbst, extrahierte Felder oder strukturierte Ausgaben), muss von Ihrer Integration explizit gehandhabt werden. Das Vorgehen variiert je nach Kanal und Anwendungsfall.
Inline
Die zweite Darstellung ist inline und umfasst alle anderen Eingaben. Sprache und Sprachnachrichten werden transkribiert. Getippter Text, transkribierte Sprache, WhatsApp-Standortpins und Kontaktkarten werden vor der Modellverarbeitung als Klartext im Transkript normalisiert. Ein Standortpin wird zu Koordinaten und optionaler Adresse, ein Kontakt zu Name und Telefonnummer. Keine dieser Eingaben wird als Datei gespeichert oder erzeugt eine Dateireferenz. Sie sind direkt im Transkript enthalten.
Warum die Unterscheidung wichtig ist
Die Aufteilung bestimmt, wo Integrationsaufwand entsteht. Der Inline-Pfad erfordert während des Gesprächs keine Maßnahmen: Die Plattform normalisiert diese Eingaben zu Text, der direkt im Transkript steht. Der dateibasierte Pfad hat eine eigene Integrationsschnittstelle. Anstatt Dateiinhalte vorab in Text umzuwandeln, übergibt der Orchestrator die Rohdatei direkt ins Kontextfenster des Modells. Das Modell arbeitet auf der Struktur der Datei, nicht auf einer abgeleiteten Textdarstellung, und erhält so räumliche Beziehungen, visuelles Layout und Dokumentenformatierung, die sonst verloren gingen. Mit dieser Unterscheidung im Blick behandelt der Rest des Beitrags die Umsetzung: wie Sie den Agenten konfigurieren, wie Dateien durch die Kanäle laufen und wie Kontext über Sitzungen hinweg erhalten bleibt.
Multimodale Eingabe einrichten
Die Aktivierung multimodaler Eingaben beginnt mit derselben Agenten-Konfiguration für Web, Mobile und WhatsApp. Wie eine Datei hochgeladen und anschließend abgerufen wird, hängt dann vom Kanal ab.
Dateiupload aktivieren
Zwei Einstellungen müssen in der Agenten-Konfiguration gesetzt sein, damit Dateiupload funktioniert. Erstens setzen Sieconversation_config.conversation.file_input.enabledaufTrue, entweder per API bei der Agentenerstellung oder unterEinstellungen > Erweiterte Einstellungen > Dateiuploadim Dashboard. Zweitens muss der Agent mit einem visuell- und dokumentenfähigen Modell konfiguriert sein. Das Flag allein bewirkt nichts, wenn das zugrundeliegende Modell keine Bild- oder Dokumentenblöcke verarbeiten kann; beides muss vor dem Testen gesetzt sein.
SDK und WebSocket
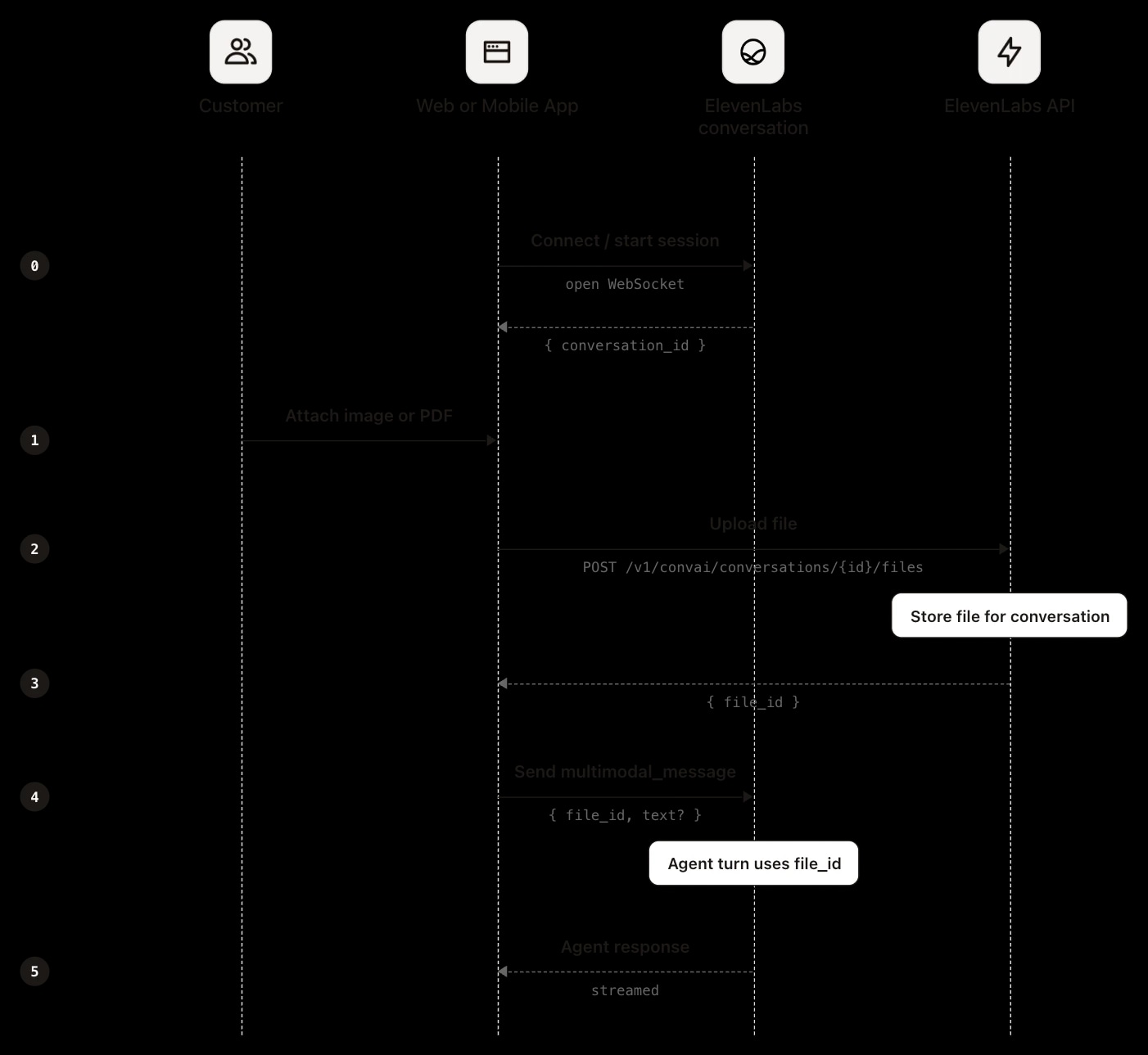
Dateiupload auf Web oder Mobile erfordert einen eigenen Chat-Client auf Basis des SDK oder eine direkte Agents-WebSocket-Verbindung. Der Ablauf ist in allen drei Fällen identisch und die Reihenfolge ist zwingend: Die Datei muss hochgeladen werden, bevor die Nachricht gesendet wird, da die Nachrichten-Payload auf die beim Upload erhaltene Kennung verweist.
Laden Sie zuerst die Datei hoch:
Siehe dieDatei-Uploadfür vollständige Anfrage und Antwort:
Senden Sie dann eine Nachricht über die Verbindung, die auf die zurückgegebenefile_idverweist:
Die SDKs fassen Upload und Referenzierung in einem Aufruf zusammen und verwalten die Dateikennung intern. Siehe diemultimodal_messageSpezifikation für das vollständige Nachrichtenformat. Da Ihre Anwendung den Upload durchführt, liegt die Datei zu diesem Zeitpunkt bereits vor. Wird sie nur für die aktuelle Konversation benötigt, reicht das Hochladen und Referenzieren der Kennung aus. Soll sie über die Sitzung hinaus bestehen, empfiehlt es sich, sie beim Upload in Ihrer Anwendung zu speichern. Alternativ kann sie nachträglich über den Post-Call-Webhook abgerufen werden, wie im Abschnitt Kontext über Sitzungen beschrieben.
Bei WhatsApp übernimmt Ihre Anwendung keinen Teil des Uploads. Sendet ein Kunde ein Bild, Dokument oder Sticker, geht die Datei zuerst an die Meta-Infrastruktur. Meta benachrichtigt ElevenLabs über das WhatsApp Business API Webhook, und ElevenLabs lädt die Datei mit Ihren WhatsApp Business Account-Zugangsdaten serverseitig herunter, speichert eine eigene Kopie und hängt sie wie beim Web- oder SDK-Upload an die Konversation an. Der Agent erhält sie als multimodale Eingabe und das Transkript vermerkt einfile_inputEreignis.
Da Ihre Anwendung den Upload nie verarbeitet, hält sie die Datei auch nie direkt. Es gibt keinen Upload-Zeitpunkt, an dem sie wie bei Web und Mobile abgegriffen werden kann. Die Datei erreicht Ihr System über diefile_urlim Post-Call-Webhook, die auf die bei ElevenLabs gespeicherte Kopie verweist. Die Media-URL von Meta dient nur zur Aufnahme und wird nie extern bereitgestellt. Details zum Abruf, einschließlich zeitlicher Einschränkungen, finden Sie im Abschnitt Kontext über Sitzungen.
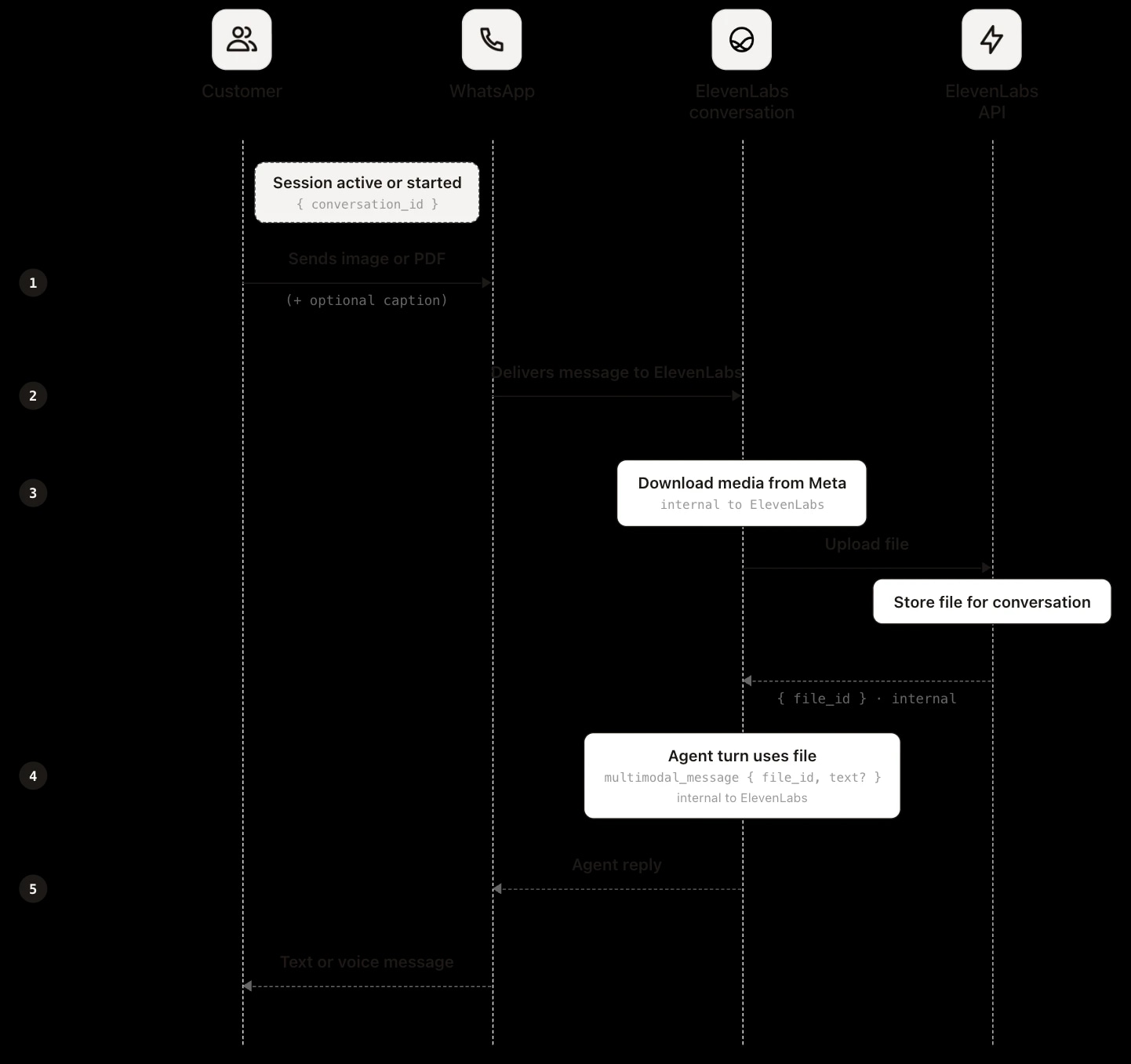
Auf WhatsApp sendet der Kunde die Datei im Chat. ElevenLabs ruft sie von Meta ab, speichert sie und vergibt diefile_idplattformseitig. Es gibt also keinen clientseitigen Upload-Schritt. Anders als bei Web und Mobile ruft Ihre Anwendung nicht POST/v1/convai/conversations/{id}/filesauf oder sendetmultimodale_nachrichtüber WebSocket. ElevenLabs übernimmt Übertragung, Speicherung und Agenten-Turn.
Kontext über Sitzungen hinweg erhalten
ElevenAgents verarbeitet jede Konversation unabhängig. Nichts, was ein Kunde sendet oder was der Agent während einer Konversation löst, wird automatisch in die nächste übernommen. Der Agent übergibt Ihrem System alle Daten einer abgeschlossenen Konversation über den Post-Call-Webhook, aber die konversationsübergreifende Erinnerung liegt außerhalb von ElevenLabs. Die Kontinuität liegt in Ihrer Verantwortung.
Diese architektonische Grenze sollte bewusst berücksichtigt werden. Gerade die Konversationen, in denen multimodale Eingaben entscheidend sind (z. B. ein Kunde fotografiert einen Schaden, lädt ein Dokument hoch, teilt einen Standort), werden oft nicht in einer Sitzung gelöst. Ein Kunde, der ein Foto eines defekten Teils sendet und einen Rückruf vereinbart, erwartet, dass der Agent das Foto beim Rückruf wieder erkennt. Ohne explizites Kontextmanagement beginnt der Agent jedes Mal bei null und der Kunde muss sich wiederholen. Das Muster zur Lösung besteht aus zwei Teilen: Nach Abschluss einer Konversation liefert der Post-Call-Webhook das Transkript, Analyseergebnisse, alle von Ihnen definierten strukturierten Felder und Dateilinks für alle durchgelaufenen Dateien. Ihr Backend speichert die relevanten Daten zum Kunden, etwa anhand von Telefonnummer, Nutzer-ID oder Account-Key. Wenn der Kunde zurückkehrt, injiziert Ihre Anwendung den gespeicherten Kontext beim Sitzungsstart über dynamische Variablen, sodass der Agent mit vorhandenem Wissen startet. Für dateibasierte Eingaben verweist die Datei-URL im Webhook-Payload auf die bei ElevenLabs gespeicherte Kopie und ist nach Sitzungsende der einzige Abrufweg. Die Plattformkopie ist auf die Sitzung begrenzt. Benötigen Sie die Datei für eine spätere Konversation oder in Ihren Systemen, müssen Sie sie aus dem Webhook-Payload herunterladen, bevor das Zeitfenster abläuft. Wie schnell Sie handeln müssen, hängt von der Aufbewahrungsrichtlinie ab (siehe Referenzdokumentation). Der Webhook trägt den Zustand hinaus, dynamische Variablen bringen ihn zurück. Alles dazwischen liegt in Ihrer Systemverantwortung – hier liegt der eigentliche Integrationsaufwand, wenn Kunden zurückkehren, eskalieren oder eine Lösung fortsetzen.
Kontext-Injektion ist kanalabhängig
Der Injektionsmechanismus variiert je Kanal, das Grundprinzip bleibt gleich. Bei Telefonie ruft ElevenLabs Ihren Server vor Gesprächsbeginn auf, sodass Sie den Anrufer per Nummer identifizieren und dynamische Variablen wie Name, Bestellnummer oder Account-Tier zurückgeben können, bevor der Agent spricht. Bei WhatsApp löst jede eingehende Nachricht ein Pre-Message-Webhook aus, mit dem Sie Identitäts- und Geschäftskontext aus Ihren Systemen anreichern können, bevor der Agent sie verarbeitet. Ansonsten werden die gleichen Felder bei Sitzungsstart inconversation_initiation_client_dataübergeben. ElevenAgents führt keine Sitzungen kanalübergreifend zusammen. Eine WhatsApp- und eine Web-Konversation sind getrennte Sitzungen, auch wenn es derselbe Kunde ist. Da Webhook-Ausgabe und Kontext-Injektion aber auf allen Kanälen identisch funktionieren, reicht eine einzige Persistenzschicht für alle Kanäle. Einmal gebaut, deckt sie jeden Kanal ab, auf dem der Agent läuft. Kontext-Injektion betrifft textbasierte Daten: Namen, Bestellnummern, Zusammenfassungen, strukturierte Felder. Dateien sind ein Sonderfall und erfordern ein anderes Vorgehen.
Dateien über Sitzungen hinweg weitergeben
Dateien sind auf eine Konversation begrenzt und werden nicht automatisch übernommen. Was weitergegeben werden soll, hängt davon ab, ob die nächste Konversation die Information aus einer Datei oder die Datei selbst benötigt. In den meisten Fällen reicht die Information. Der Agent interpretiert eine hochgeladene Datei im jeweiligen Turn, schreibt diese Interpretation aber nicht automatisch dauerhaft weg. Die strukturierte Ausgabe stammt aus den Post-Call-Daten: Transkript, Zusammenfassung und von Ihnen definierte Felder. Sendet ein Kunde ein Foto einer defekten Türdichtung und meldet sich eine Woche später zur Nachverfolgung, braucht der Agent nicht das Foto, sondern die Information, dass es um eine defekte Türdichtung geht. Sie extrahieren das aus den Post-Call-Daten, speichern es zum Kunden und injizieren es als dynamische Variable beim nächsten Kontakt. Eine kurze Zusammenfassung oder wenige strukturierte Felder genügen meist.
Wenn Sie die Originaldatei benötigen – etwa für eigene Unterlagen, Compliance oder nachgelagerte Systeme – ist der Post-Call-Webhook der Abrufweg. Jede hochgeladene Datei erscheint im Transkript alsfile_inputEreignis mit signierter Datei-URL. Diese ist 15 Minuten gültig, laden und speichern Sie die Datei also direkt beim Eintreffen des Webhooks. Verpassen Sie das Zeitfenster, solange die Konversation noch existiert, stellt die GET-Konversation-API neue URLs bereit. Planen Sie ein, dassfile_inputin manchen Fällen fehlt, etwa im Zero-Retention-Modus, statt davon auszugehen, dass jeder dateibasierte Turn eine URL enthält.
Damit ist der gesamte Lebenszyklus abgedeckt: Eine Datei gelangt in die Sitzung, das Modell verarbeitet sie nativ, strukturierte Ausgaben verlassen die Plattform per Webhook und Ihre Persistenzschicht entscheidet, was der Agent beim nächsten Mal weiß.
Fazit
Die gleiche Agenten-Konfiguration akzeptiert Bilder und PDFs über Web, Mobile und WhatsApp – ohne separaten Build je Kanal. Dateien werden normalisiert, dem Turn zugeordnet und als native Blöcke ans Modell übergeben, nicht als Textzusammenfassungen. So bleiben räumliches Layout, visuelle Struktur und Dokumentenformatierung erhalten. Kontext über Sitzungen hinweg folgt auf allen Kanälen demselben Muster: Der Post-Call-Webhook trägt den Zustand hinaus, dynamische Variablen bringen ihn zurück.
Wenn Sie mit ElevenLabs Agents arbeiten und möchten, dass Ihr Agent mit Bildern und Dokumenten ebenso wie mit Sprache und Text umgehen kann, aktivieren Sie multimodale Eingaben und teilen Sie uns Ihr Feedback mit.




