
Eleven v3 音频标签:表达语音中的情感语境
- 分类
- 资源
- 日期

我们多年来一直在为这个方向努力。本文介绍已发布的内容,以及背后的研究和产品决策。
我们的旗舰产品 —— ElevenAgents 搭载 v3 Conversational
Expressive Mode - Mark - Personal Loan Inbound(紧急)- launch asset.mp4
要让交互系统顺畅运行并实现自然互动,需要同时满足以下三点:
*仅指模型推理时延。实际端到端延迟会因地理位置和终端类型等因素有所不同。
已发布的部分功能
预测性轮流对话。 v3 Conversational 的独立功能,在用户静默时提前触发 LLM 响应生成,降低感知延迟。
Flash v2.5。 我们最快的文本转语音模型,专为低延迟实时场景设计,推理时延约为 75 ms。*
Scribe v2。 我们的语音转文本模型,具备行业领先的准确率。
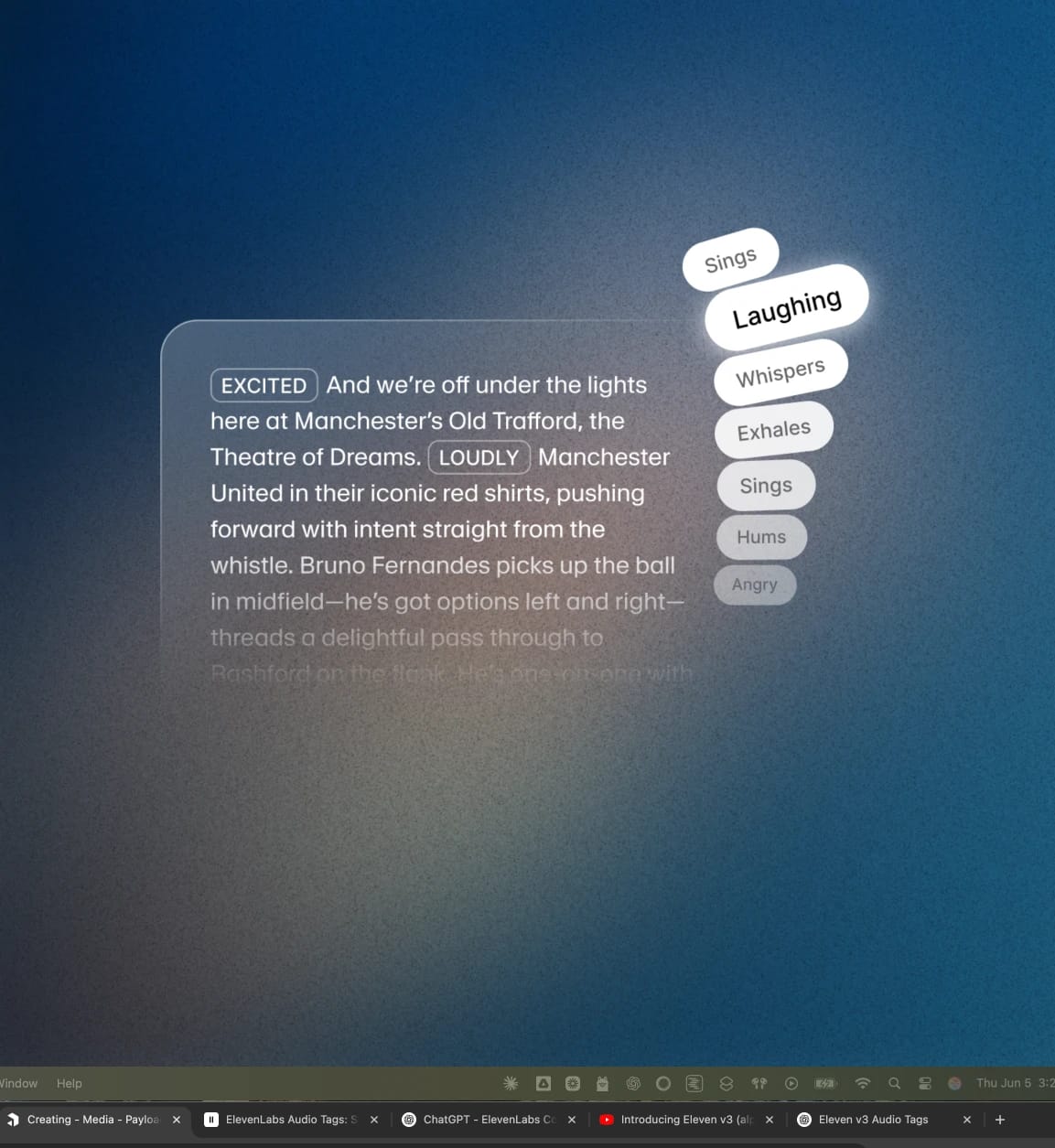
ElevenAgents 表现力模式。 支持智能体通过 [laughs]、[whispers]、[sighs]、[slow] 等标签,灵活控制语音表现。
ElevenAgents 表现力模式。 支持智能体使用 [laughs]、[whispers]、[sighs]、[slow] 等表现力标签,灵活控制语音表达。
ElevenAgents Expressive Mode。 支持智能体通过 [laughs]、[whispers]、[sighs]、[slow] 等表达标签,灵活控制语音表现。
未来方向
许多 AI 对话仍像在提问。真正的交流并非如此。我们正在努力缩小这个差距。



