
























.webp&w=3840&q=80)
ElevenLabs faz parceria com o Governo do Reino Unido para levar voz IA aos serviços públicos e amplia sede em Londres
- Categoria
- Empresa
- Data
Confiado por mais de 1 milhão de usuários • Comece grátis



Narração
Vozes expressivas que dão vida a audiolivros e podcasts
Anúncio
Vozes persuasivas que incentivam ações e ajudam a fixar sua marca.
Personagens
Vozes divertidas e envolventes para desenhos animados ou jogos.
Narração
Vozes expressivas que dão vida a audiolivros e podcasts
Conversacional
Vozes naturais perfeitas para cenários informais.
Mídias Sociais
Vozes modernas e cativantes para conteúdo de curta duração

Crie falas controláveis e expressivas, com emoção, eventos de áudio e paisagens sonoras imersivas.
A voz fez uma pausa por um momento, [suavemente] como se estivesse reunindo seus pensamentos antes de continuar. Cada respiração parecia intencional, cada hesitação perfeitamente cronometrada.
Isso não era mais uma fala sintética [ri calorosamente] - era uma voz que entendia o tempo, a emoção e o espaço entre as palavras.
Texto transformado em presença. [suspira contente] Palavras ganhando vida, personalidade, alma.
Explore uma coleção sempre crescente de vozes expressivas e realistas para qualquer uso – de narração à criação de personagens.
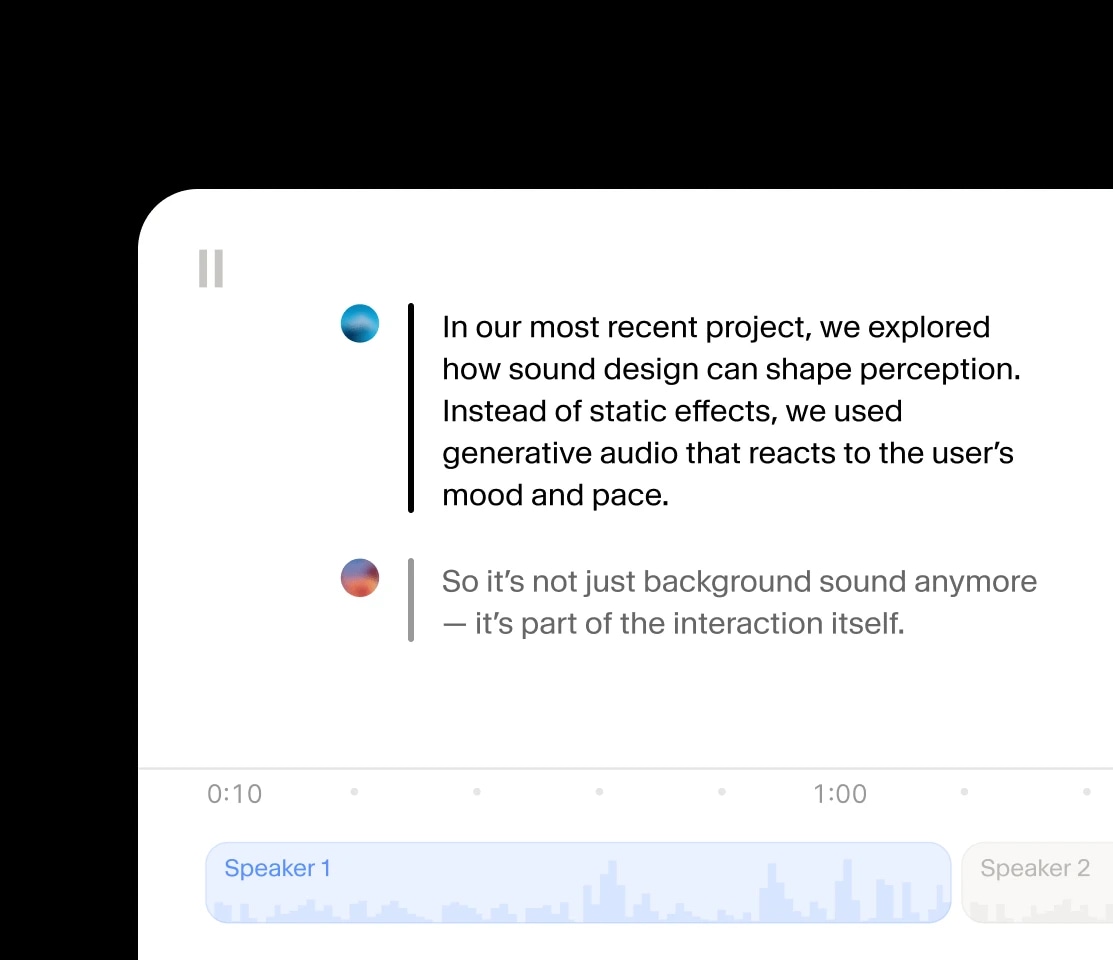
Crie conversas em áudio onde os falantes compartilham contexto e emoção.
Replique sua própria voz instantaneamente ou crie vozes IA únicas com controle total.
Dê vida a histórias em mais de 70 idiomas, todos com emoção e clareza de nível nativo.
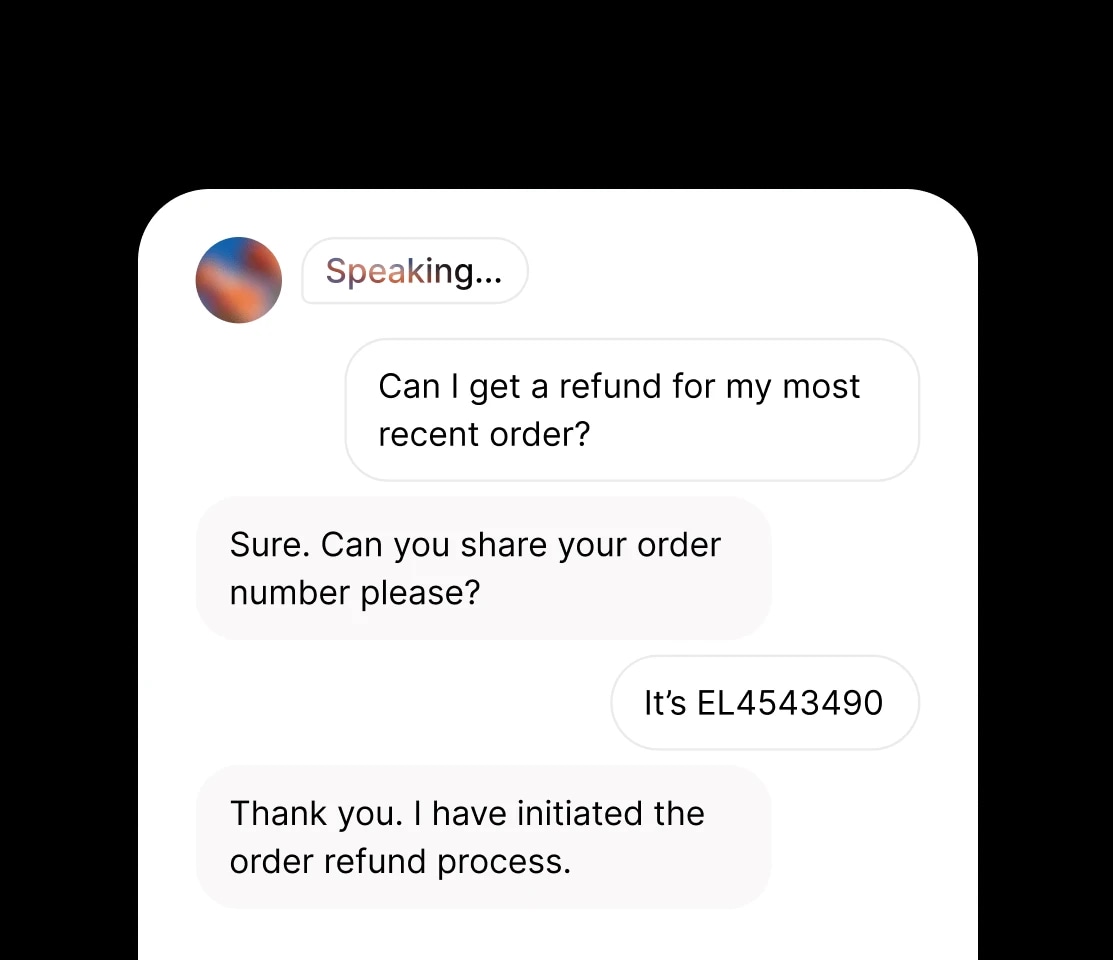

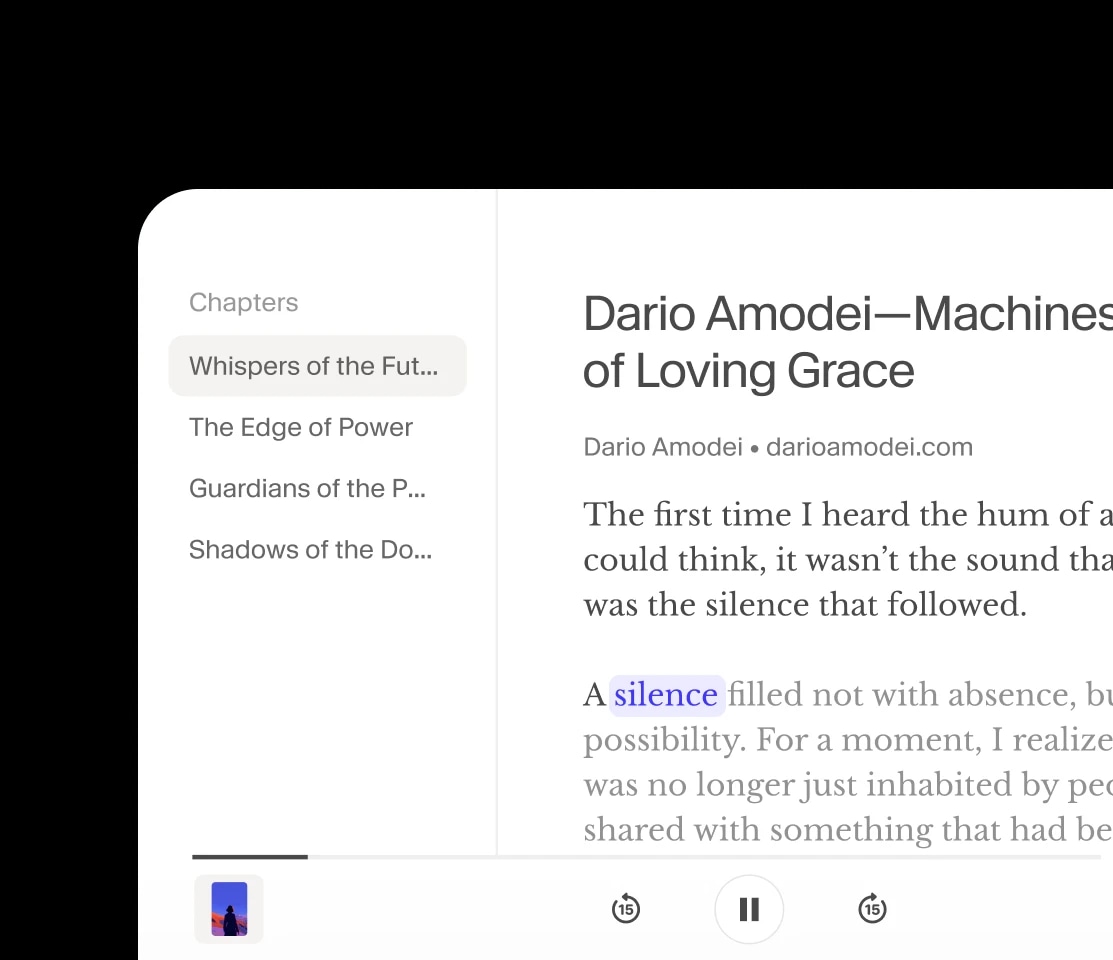


Nosso modelo mais avançado e expressivo, com tags de áudio para controle emocional preciso. Ideal para contar histórias, jogos e produção de mídia em mais de 70 idiomas.

Nosso modelo de text to speech mais realista e rico em emoção, com suporte a 29 idiomas. Perfeito para locuções, audiolivros, pós-produção e criação de conteúdo.

Nosso modelo TTS de alta qualidade e baixa latência em 32 idiomas. Ideal para desenvolvedores que precisam de velocidade e suporte a idiomas além do inglês.

Modelo de alta qualidade e baixa latência, equilibrando qualidade e velocidade

Os melhores modelos de áudio IA em um editor poderoso.

Gere áudio expressivo em segundos usando nossos apps para iOS e Android.
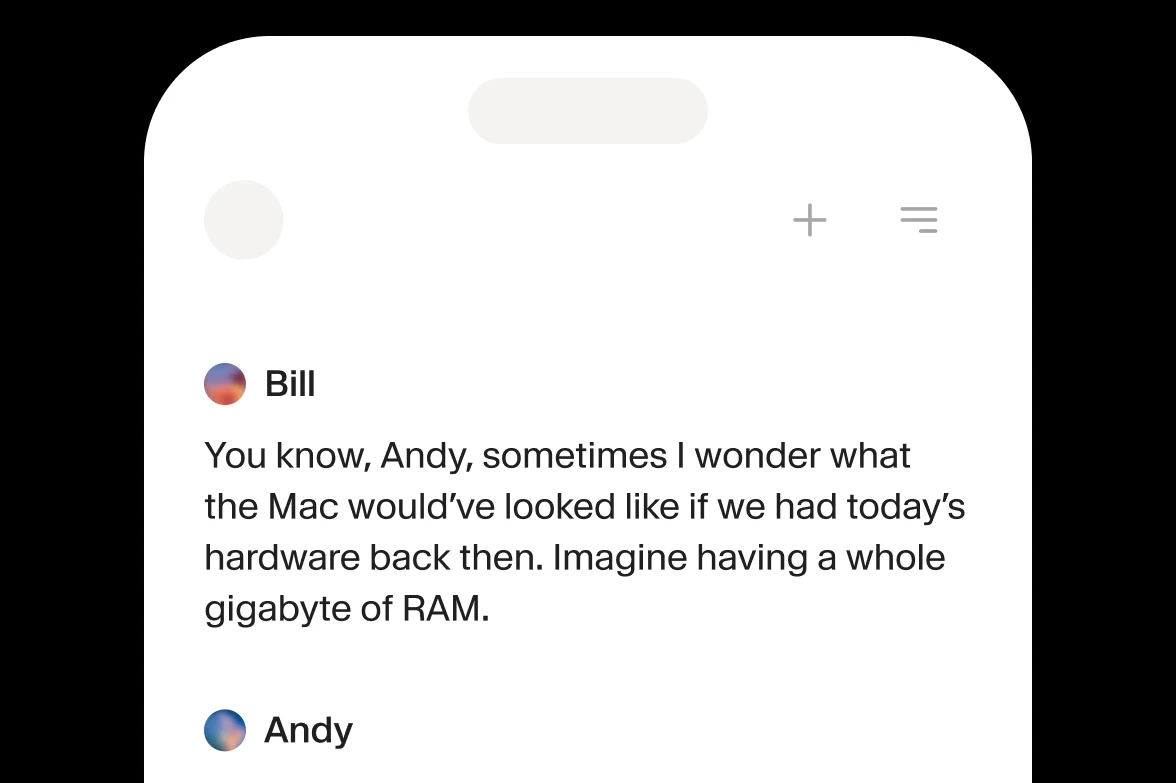
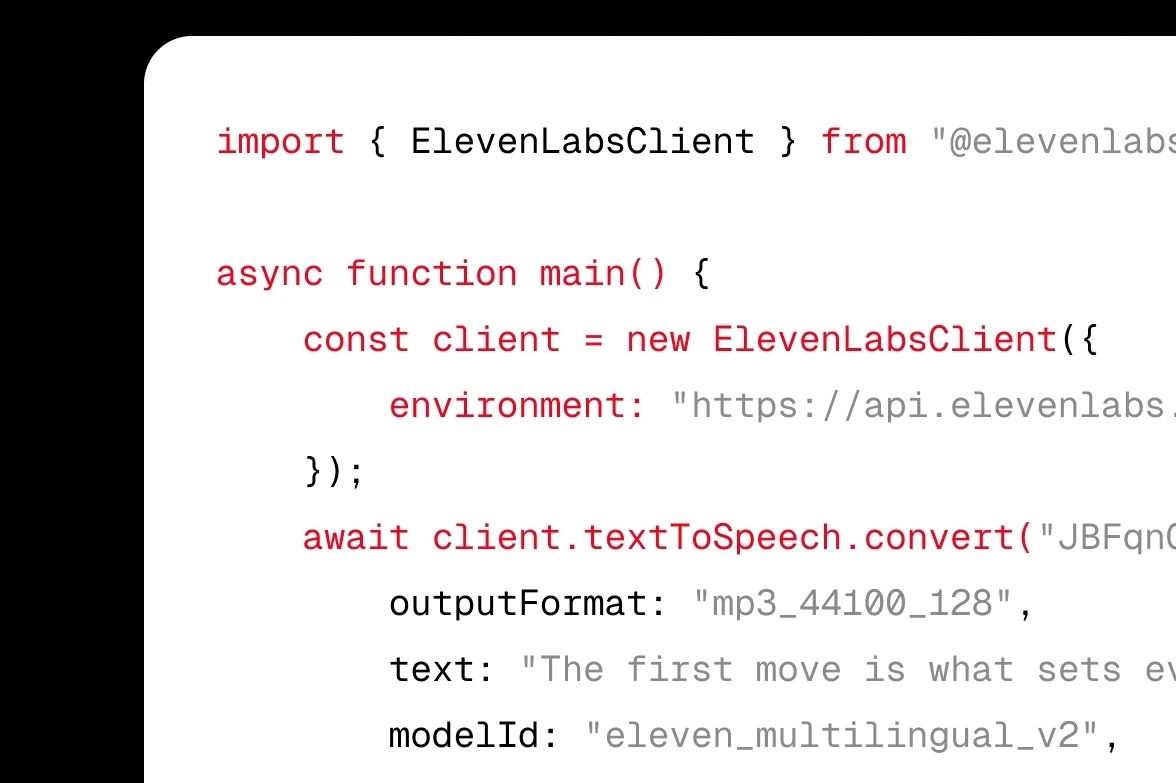
Integre o ElevenLabs Text to Speech (TTS) ao seu produto via APIs ou SDKs.




.webp&w=3840&q=80)
.webp&w=3840&q=80)
.webp&w=3840&q=80)
