
Przedstawiamy ElevenAgents Spotlight
- Kategoria
- Produkt
- Data
Scribe v2 to najdokładniejszy model Speech to Text. Scribe v2 Realtime wyznacza standardy dla transkrypcji na żywo - wspierając agentów i aplikacje w czasie rzeczywistym. Oba dostępne przez API.


Scribe v2 Realtime przechwytuje mowę na żywo poniżej 150 ms z wyjątkową dokładnością – stworzony dla agentów, spotkań i AI Agentów wymagających natychmiastowego zrozumienia.
Scribe v2 Realtime dostarcza wiodącą w branży dokładność z latencją poniżej 150 ms, ustanawiając nowy standard dla rozpoznawania mowy w czasie rzeczywistym.
Automatycznie wykrywaj, kiedy mowa się zaczyna i kończy, segmentując mowę z precyzją dla płynniejszego przetwarzania na żywo.
Dostarczając wyjątkową dokładność w różnych akcentach, dialektach i warunkach nagrywania.
Wbuduj Scribe Realtime v2 w swoje produkty za pomocą API. Z pełnym wsparciem strumieniowania i kontrolą zatwierdzania.


Prześlij audio lub wideo w dowolnym formacie — MP4, MOV, MP3, WAV i więcej. Scribe v2 automatycznie konwertuje mowę na precyzyjny tekst, gotowy do napisów, podtytułów lub edycji.
Scribe v2 osiąga wiodącą w branży dokładność transkrypcji, dostarczając czysty, edytowalny tekst nawet w trudnych warunkach audio lub przy różnych akcentach.
Wybierz do 1000 konkretnych słów lub zdań, które Scribe ma dokładnie rozpoznać w kontekście.
Od śmiechu po kroki, Scribe v2 taguje każde zdarzenie dźwiękowe, wzbogacając twoje transkrypcje o pełny kontekst.
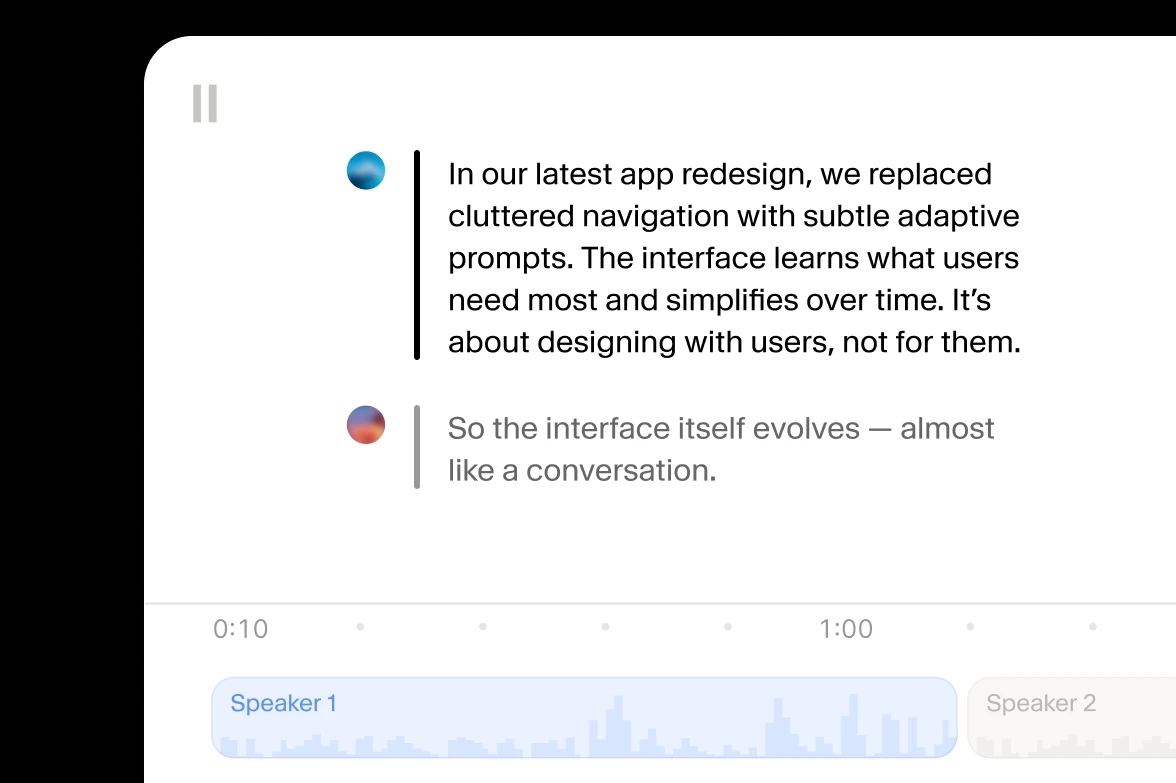
Scribe v2 rozpoznaje i oznacza każdego rozmówcę, podaje czas wypowiedzi i ukrywa wrażliwe dane w transkrypcji.

Zintegruj Scribe v2 i Scribe v2 Realtime z twoim produktem za pomocą API lub SDK.

Umożliwiaj interakcje głosowe w czasie rzeczywistym z natychmiastową, niską latencją transkrypcji.
.webp&w=3840&q=100)
Konwertuj nagrania na edytowalny tekst, napisy i treści do ponownego wykorzystania.
Nasza transkrypcja AI Speech to Text obsługuje ponad 90 języków, wystarczy wybrać język i przesłać plik audio.












































































.png&w=3840&q=80)
.png&w=3840&q=80)
