वॉइस एजेंट मूल्यांकन फ्रेमवर्क: 6 मुख्य स्तंभों की पूरी जानकारी
- लेखक
- Jack Limebear
- प्रकाशित
- आखिरी बार अपडेट किया गया
वॉइस एजेंट्स को लगभग एक साथ कई टूल्स का इस्तेमाल करना पड़ता है। इसमें ग्राहक की बातों को रियल-टाइम में रिकॉर्ड करना एक नाजुक काम है,
इतने सारे हिस्सों के साथ, आप वॉइस एजेंट की परफॉर्मेंस को सही तरीके से कैसे आंक सकते हैं?
इस आर्टिकल में हम 6 स्तंभों वाला वॉइस एजेंट मूल्यांकन फ्रेमवर्क बताएंगे, जिससे आप एजेंट की सफलता को सही मायनों में माप सकते हैं। हम यह भी बताएंगे कि अलग-अलग इंडस्ट्रीज़ में इन स्तंभों का महत्व अलग हो सकता है और मूल्यांकन करते समय आम गलतियों से कैसे बचें।
सारांश
- वॉइस एजेंट मूल्यांकन के 6 मुख्य स्तंभ हैं: TTS वॉइस क्वालिटी, कन्वर्सेशन क्वालिटी, टूल यूसेज और टास्क कंप्लीशन, इंटेलिजेंस, कंप्लायंस और सुरक्षा, और रिलायबिलिटी।
- सबसे ज़रूरी प्रोडक्शन टार्गेट्स हैं: MOS 4.3, TSR 85% से ऊपर, और टाइम-टू-फर्स्ट ऑडियो 500ms से कम।
- अलग-अलग इंडस्ट्रीज़ में इन स्तंभों का महत्व अलग-अलग हो सकता है, कुछ डिप्लॉयमेंट्स में एक स्तंभ दूसरे से ज़्यादा अहम हो सकता है।
- आम टेस्टिंग गलतियों में सिर्फ साफ़ ऑडियो का मूल्यांकन करना और P99 लेटेंसी स्पाइक्स को नज़रअंदाज़ करना शामिल है।
- ElevenLabs उन्हीं मेट्रिक्स में सबसे आगे है जो सबसे ज़्यादा मायने रखते हैं: Scribe v2 का WER फील्ड में सबसे कम है 2.2% (Artificial Analysis, जून 2026), Flash v2.5 और Turbo v2.5 स्पीड के लिए टॉप मॉडल्स हैं (Artificial Analysis, जून 2026), और ElevenAgents ~75ms मॉडल इनफेरेंस लेटेंसी देते हैं।
वॉइस एजेंट मूल्यांकन फ्रेमवर्क क्या है?
AI वॉइस एजेंट मूल्यांकन फ्रेमवर्क एक स्ट्रक्चर्ड सिस्टम है, जिससे आप परफॉर्मेंस को कई डाइमेंशन्स में टेस्ट कर सकते हैं। एक अच्छा फ्रेमवर्क ऑडियो क्वालिटी से लेकर कन्वर्सेशन फ्लो और रेगुलेटरी कंप्लायंस तक सब कुछ मापने के लिए मेट्रिक्स शामिल करता है।
टेक्स्ट चैटबॉट के मुकाबले, वॉइस एजेंट हर इंटरैक्शन को कम से कम तीन टेक्नोलॉजीज़ से गुज़ारता है: ऑटोमैटिक स्पीच रिकग्निशन (ASR), जो यूज़र के शब्दों को टेक्स्ट में बदलता है; एक LLM जो जवाब तैयार करता है; और एक TTS सिस्टम जो उस जवाब को फिर से ऑडियो में बदलता है। अगर इनमें से कोई भी सिस्टम फेल हो जाए, तो पूरी एक्सपीरियंस खराब हो जाती है।
यही जटिलता है जिसकी वजह से बिज़नेस को वॉइस एजेंट चुनने और डिप्लॉय करने से पहले उनका मूल्यांकन करना ज़रूरी है। कोई भी अतिरिक्त लेटेंसी या गलत जवाब असल दुनिया में असर डाल सकते हैं, जैसे ग्राहक खोना या रेगुलेटरी फाइन और छवि को नुकसान।
वॉइस एजेंट्स का मूल्यांकन करने के लिए फ्रेमवर्क बेंचमार्किंग और मापने योग्य डेटा का इस्तेमाल करता है, जिससे तय किया जा सके कि कोई एजेंट किसी खास यूज़ केस के लिए सही है या नहीं। बिज़नेस के नज़रिए से, अलग-अलग वॉइस मॉडल्स का मूल्यांकन करने से आप अपने ग्राहकों के लिए सबसे अच्छा मॉडल चुन सकते हैं।
वो 6 वॉइस एजेंट मूल्यांकन स्तंभ जिन्हें आपको देखना चाहिए
हालांकि AI एजेंट बनाना और डिप्लॉय करना पहले से कहीं आसान है, लेकिन इसके अंदर चल रही प्रक्रियाएं काफी जटिल हैं। कई हिस्से मिलकर यूज़र को सुनते हैं, उनकी ज़रूरत समझते हैं, वो जानकारी LLM को देते हैं, और फिर ऑडियो जवाब तैयार करते हैं—इन सब में कई काम लगभग एक साथ होते हैं।
अगर आप सबसे अच्छे वॉइस एजेंट के साथ पार्टनर करना चाहते हैं, तो बिज़नेस को एक मजबूत फ्रेमवर्क चाहिए जिससे तुलना की जा सके।
अगर आप टेस्टिंग के नतीजे देखना चाहते हैं, तो आर्टिफिशियल एनालिसिस अलग-अलग कंपोनेंट्स के आधार पर कई एजेंट तुलना पेश करता है। नीचे आप उनके मॉडल-टू-मॉडल स्पीड फैक्टर के नतीजे देख सकते हैं, जिसमें ElevenLabs के टर्बो v2.5 और Flash v2.5 कैरेक्टर्स-पर-सेकंड में सबसे आगे हैं।
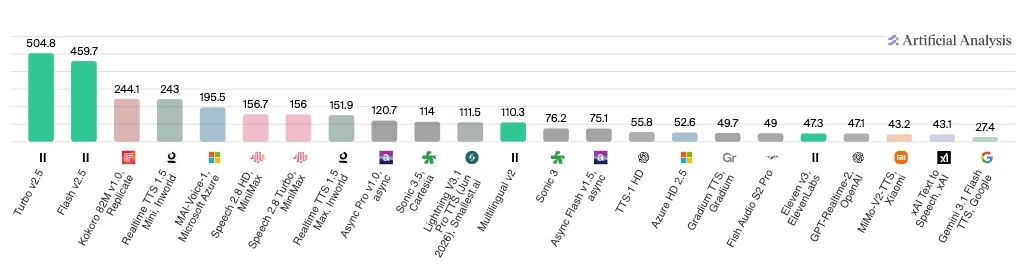
डेवलपर्स या बिज़नेस जो खुद एक्सपेरिमेंट करना चाहते हैं, उनके लिए AI एजेंट मूल्यांकन फ्रेमवर्क के ये 6 स्तंभ हैं:
- TTS वॉइस क्वालिटी: synthesized स्पीच यूज़र्स को कितनी नैचुरल, क्लियर और एक्सप्रेसिव लगती है। फील्ड के टॉप मॉडल्स, जैसे Eleven v3, 70 से ज़्यादा भाषाओं में इंसानों जैसी, भावनात्मक डिलीवरी देते हैं।
- कन्वर्सेशन क्वालिटी: क्या मॉडल इंसानी स्पीच को समझता है, उसका मतलब निकालता है, और संदर्भ के हिसाब से जल्दी जवाब देता है?
- टूल यूसेज: AI एजेंट उपलब्ध संसाधनों से बिना इंसानी दखल के कितने अच्छे से टास्क पूरे करता है।
- इंटेलिजेंस: मॉडल कितनी अच्छी तरह से तर्क करता है, नए इनपुट्स को संभालता है, और गलत या काल्पनिक जवाब देने से बचता है।
- कंप्लायंस और सुरक्षा: सभी फीचर्स के साथ,
- रिलायबिलिटी: कुल अपटाइम और लोड में लगातार परफॉर्मेंस जैसे कंपोनेंट्स से पता चलता है कि कोई कन्वर्सेशनल AI एजेंट डिमांड के साथ स्केल कर सकता है या नहीं।
हालांकि ये सभी स्तंभ अलग-अलग हैं, लेकिन ये आपस में जुड़े हुए हैं और यूज़र को हाई-क्वालिटी फाइनल एक्सपीरियंस देते हैं। जैसे, अगर किसी मॉडल की वॉइस क्वालिटी बेहतर हो गई लेकिन लेटेंसी ज़्यादा रही, तो ग्राहक को जवाब मिलने में अजीब देरी महसूस होगी।
आइए इन वॉइस AI मूल्यांकन स्तंभों को और गहराई से समझते हैं।
TTS वॉइस क्वालिटी
हम वॉइस क्वालिटी से शुरू कर रहे हैं, क्योंकि यही वो चीज़ है जो इंसान सबसे पहले नोटिस करता है जब वो AI कन्वर्सेशनल एजेंट से बात करता है। अगर आवाज़ रोबोटिक या अजीब लगे, तो एजेंट के साथ अनुभव काफी खराब हो सकता है।
मूल्यांकन के शुरुआती मेट्रिक्स में से एक है Mean Opinion Score (MOS), जिसे International Telecommunication Union Telecommunication Standard Sector (ITU-T) ने परिभाषित किया है। MOS 1-5 के स्केल पर काम करता है, जिसमें 1 बेकार और 5 बेहतरीन है। यह एक सब्जेक्टिव माप है, जिसमें इंसानी श्रोता कॉल के बाद फीडबैक देते हैं।
इस स्केल पर MOS 3.5 से कम होना आज के स्टैंडर्ड्स के हिसाब से काफी कमजोर है और ग्राहक संतुष्टि पर असर डाल सकता है।
MOS इंसानी माप है, लेकिन कई तकनीकी ज़रूरतें भी इसमें शामिल होती हैं:
- पिच कंसिस्टेंसी और जिटर: पिच और जिटर दो भाषाई तत्व हैं जिन्हें इंसान सुनते समय खुद-ब-खुद नोटिस करते हैं। “पिच” का मतलब है बोलते समय आवाज़ का ऊपर-नीचे होना, जैसे सवाल पूछते समय आवाज़ ऊपर जाना। जिटर तब होता है जब वॉइस मॉडल पिच को सही से नहीं समझ पाता, जिससे पूरे वाक्य में आवाज़ की लय बिगड़ जाती है। इंडस्ट्री में जिटर का बेसलाइन 30ms है।
- इमोशनल एक्सप्रेसिवनेस: अगर आवाज़ साफ़ और सटीक है लेकिन टोन वाक्य की भावना से मेल नहीं खाती, तो वो भी गलत लगेगी। सही टोनल संकेत न होने पर इंसान AI कन्वर्सेशनल एजेंट्स से कम जुड़ाव महसूस करेंगे और उन्हें कम रेटिंग देंगे। ElevenAgents लगभग इंसानों जैसी एक्सप्रेसिवनेस देता है, जिससे हर जवाब में भावना साफ़ झलकती है।
- बैकग्राउंड नॉइज़: वॉइस एजेंट्स में बैकग्राउंड नॉइज़ के दो अलग-अलग पहलू होते हैं। आउटपुट में, हल्का बैकग्राउंड नॉइज़ जोड़ने से एजेंट्स ज़्यादा नैचुरल लगते हैं। इनपुट में, STT लेयर पर बैकग्राउंड नॉइज़ फिल्टरिंग एक ऑप्शनल टॉगल है, जिससे सटीकता बढ़ती है। एजेंट का मूल्यांकन करते समय दोनों को टेस्ट करें: सुनें कि बैकग्राउंड नॉइज़ नैचुरल लग रही है या नहीं, और नॉइज़ फिल्टर ऑन/ऑफ करके STT की सटीकता जांचें।
MOS निकालते समय आपको 4.3-4.5 का टार्गेट रखना चाहिए, जिससे सभी पहलुओं में हाई स्कोर दिखता है। स्केल पर MOS प्रेडिक्शन के लिए, बिना इंसानी पैनल के, आप UTMOS और NISQA जैसे टूल्स का इस्तेमाल कर सकते हैं।
कन्वर्सेशन क्वालिटी
कन्वर्सेशन क्वालिटी एक मिश्रित स्तंभ है, जो वॉइस क्वालिटी और टास्क कंप्लीशन के बीच आता है। इसका मकसद है यह मापना कि वॉइस एजेंट यूज़र की ज़रूरत कितनी अच्छी तरह समझता है, संदर्भ में कब रोकता है, और मल्टी-टर्न डायलॉग को पूरा करता है।
यहां मुख्य मेट्रिक है इंटेंट क्लासिफिकेशन एक्युरेसी, जो आमतौर पर 85% से 92% के बीच होती है और टॉप परफॉर्मर्स 96% तक पहुंचते हैं। 85% सुनने में ज़्यादा लग सकता है, लेकिन इसका मतलब है कि 15% ट्रैफिक गलत कैटेगरी में चला जाता है।
इंटेंट क्लासिफिकेशन एक्युरेसी बढ़ाने वाले तकनीकी तत्व हैं:
- टर्न-टेकिंग: टर्न-टेकिंग से पता चलता है कि वॉइस एजेंट बातचीत के नैचुरल फ्लो को कितनी अच्छी तरह संभालता है। यह मापता है कि एजेंट कब सुनना, जवाब देना या और इनपुट का इंतजार करना जानता है। इसमें बार्ज-इन भी शामिल है, जिसमें मॉडल बीच में जवाब रोककर नए इनपुट के आधार पर नया जवाब देता है। ElevenLabs मल्टी-कॉन्टेक्स्ट वेब्सॉकेट का इस्तेमाल करता है, जिससे ये इंटरप्शन आसानी से संभाले जाते हैं।
- लेटेंसी: लेटेंसी का मतलब है यूज़र के वाक्य खत्म करने और एजेंट के ऑडियो जवाब शुरू करने के बीच का समय। प्रोडक्शन-ग्रेड वॉइस एजेंट्स को 500ms से कम टाइम-टू-फर्स्ट ऑडियो का टार्गेट रखना चाहिए, 300ms से कम होना और भी बेहतर है। ElevenLabs Flash मॉडल्स ~75ms का इंडस्ट्री-लीडिंग मॉडल इनफेरेंस टाइम देते हैं, जिससे आप इस कैटेगरी में आगे रहते हैं।
- फॉलबैक रेट: फॉलबैक रेट बताता है कि AI एजेंट कितनी बार यूज़र को समझ नहीं पाता और सफाई या दोहराव मांगता है। यह मुख्य रूप से STT एक्युरेसी पर निर्भर करता है, क्योंकि अगर स्पीच रिकग्निशन लेयर ग्राहक की बात गलत सुनती है, तो LLM को गलत इनपुट मिलता है। फॉलबैक रेट का फॉर्मूला है: फॉलबैक रेट (%) = (फॉलबैक की संख्या / कुल इंटरैक्शन) * 100।
ElevenLabs Scribe V2 का WER Artificial Analysis स्पीच टू टेक्स्ट मॉडल मूल्यांकन में सबसे कम 2.2% है
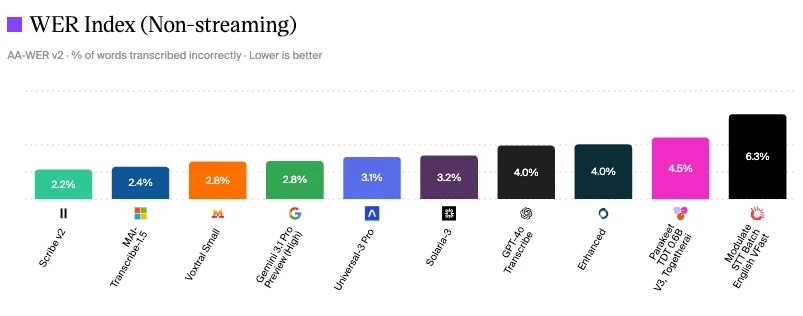
Artificial Analysis स्पीच टू टेक्स्ट मॉडल्स मूल्यांकन
कन्वर्सेशन क्वालिटी मापने का एक तरीका है अलग-अलग कंपोनेंट्स के लिए इंडस्ट्री बेंचमार्किंग स्टैंडर्ड्स देखना। जैसा कि आप देख सकते हैं, ElevenLabs का Scribe v2 जून 2026 तक 2.2% के सबसे कम Word Error Rate के साथ सबसे आगे है, यानी कम गलत सुनना, कम फॉलबैक, और ज़्यादा सटीक इंटेंट क्लासिफिकेशन।
बिज़नेस को यह भी पता चल सकता है कि कन्वर्सेशन क्वालिटी उस वर्कफ़्लो पर भी निर्भर करती है जिसमें वॉइस एजेंट काम करता है। उदाहरण के लिए, कस्टमर सर्विस में एस्केलेशन हैंडऑफ क्वालिटी या FAQ रिज़ॉल्यूशन भी मायने रखता है।
टूल यूसेज और टास्क कंप्लीशन
जहां क्वालिटी बताती है कि बातचीत कैसी रही, वहीं टास्क कंप्लीशन बताता है कि क्या बातचीत से सही नतीजा निकला। एंटरप्राइज़ेस को वॉइस एजेंट मूल्यांकन फ्रेमवर्क के इस हिस्से पर खास ध्यान देना चाहिए, क्योंकि यह सीधे बिज़नेस रिज़ल्ट्स से जुड़ा है।
टूल यूसेज मापने का एक तरीका है स्लॉट-फिल एक्युरेसी, जिससे पता चलता है कि AI एजेंट्स कितनी अच्छी तरह रूटीन टास्क पूरे कर सकते हैं, जैसे ग्राहक की जानकारी से फॉर्म भरना। हाई स्लॉट-फिल एक्युरेसी दिखाती है कि एजेंट बातचीत से एक्शन तक बिना जानकारी खोए आगे बढ़ सकता है।
Task Success Rate (TSR) एक प्रतिशत आधारित माप है, जिसमें देखा जाता है कि एजेंट ने कितने एंड-टू-एंड टास्क सफलतापूर्वक पूरे किए। कंप्लीशन का मतलब है एजेंट का रिक्वेस्ट को समझना और फिर सही टूल्स (APIs, डेटाबेस, Retrieval-Augmented Generation (RAG), और इंटरनल नॉलेज बेस) का इस्तेमाल करना।
TSR का फॉर्मूला है:
TSR = (पूरे हुए टास्क / कुल टास्क) x 100
प्रोडक्शन-रेडी वॉइस एजेंट्स को 85% से ऊपर TSR का टार्गेट रखना चाहिए, साथ ही टूल कॉल एक्युरेसी और टूल कॉल रिलायबिलिटी की मॉनिटरिंग करनी चाहिए। TSR में गिरावट से बचने के लिए, हर प्रॉम्प्ट या कनेक्टेड मॉडल बदलाव पर रिग्रेशन टेस्ट ज़रूर करें। छोटी सी गलती भी TSR पर बड़ा असर डाल सकती है।
इंटेलिजेंस
इंटेलिजेंस वॉइस एजेंट की तर्कशक्ति और उच्च-स्तरीय क्षमताओं को दर्शाता है। यही स्तंभ वॉइस-आधारित IVR (Interactive Voice Response) और वॉइस AI एजेंट में फर्क साफ करता है।
यहां मूल्यांकन के मुख्य डाइमेंशन्स हैं:
- हैलुसिनेशन रिस्क: हैलुसिनेशन यानी जब एजेंट गलत या कंपनी दस्तावेज़ों से मेल न खाने वाली जानकारी देता है, वॉइस AI में ये और भी नुकसानदेह है क्योंकि ये आत्मविश्वास के साथ बोला जाता है।हालिया स्टडीज़ बताती हैं कि आम हैलुसिनेशन वॉइस एजेंट्स के साथ ग्राहक संतुष्टि को काफी नुकसान पहुंचाती है।
- आउट-ऑफ-स्कोप हैंडलिंग: इंटेलिजेंट एजेंट्स समझते हैं कि कब कोई सवाल उनके दायरे से बाहर है और सही जवाब देते हैं। जवाब गढ़ने के बजाय, वे मना कर देते हैं या बातचीत को फिर से सही संदर्भ में ले आते हैं।
- कॉन्टेक्स्ट रिटेंशन: कई टर्न्स में, क्या एजेंट पहले की गई बातों और कमिटमेंट्स को ट्रैक कर सकता है? अगर नहीं, तो ग्राहक को बार-बार खुद को दोहराना पड़ सकता है या विरोधाभासी जवाब मिल सकते हैं।
- रीजनिंग और मल्टी-स्टेप लॉजिक: क्या एजेंट कंडीशनल लॉजिक या कई टर्न्स में इनफेरेंस को सही से संभाल सकता है? खासकर टेक्निकल यूज़ केस में, जैसे फाइनेंशियल सर्विसेज़, तय संदर्भ में तर्क करना सफलता के लिए ज़रूरी है।
इन डाइमेंशन्स के लिए कई थर्ड-पार्टी बेंचमार्क्स मौजूद हैं। उदाहरण के लिए, Stanford का Holistic Evaluation of Language Models (HELM) अलग-अलग कैटेगरी में LLM परफॉर्मेंस मापता है। हैलुसिनेशन के लिए, TruthfulQA बताता है कि गलत जवाब कितनी बार आते हैं।
ElevenAgents का एक फायदा यह है कि, कुछ वॉइस प्लेटफॉर्म्स की तरह आपको एक ही मॉडल में नहीं बांधता, आप LLM लेयर को पूरी तरह बदल सकते हैं। यानी आप अपने यूज़ केस के लिए बेस्ट रीजनिंग मॉडल चुन सकते हैं।
कंप्लायंस और सुरक्षा
बिज़नेस को नुकसानदेह या पॉलिसी-वायलेटिंग आउटपुट रोकने के लिए एक्टिव गार्डरेल्स लगाने चाहिए। सिस्टम-लेवल प्रॉम्प्ट इंस्ट्रक्शंस के उलट, जिन्हें बायपास किया जा सकता है, स्वतंत्र गार्डरेल चेक मॉडल के बाहर एक अलग लेयर के रूप में चलते हैं। ये आउटपुट्स को यूज़र तक पहुंचने से पहले जांचते हैं और अगर बातचीत खतरनाक दिशा में जाती है तो उसे रोक देते हैं।
ऑडिटेबिलिटी भी ज़रूरी है, जिसमें प्रोडक्शन एजेंट्स को फैसलों और आउटपुट्स का डिटेल्ड लॉग रखना चाहिए, ताकि बाद में रिव्यू किया जा सके। खासकर रेगुलेटेड इंडस्ट्रीज़ में, बाद में कंप्लायंस दिखाना भी उतना ही ज़रूरी है जितना उसे हासिल करना।
आपके बिज़नेस को किन नियमों का पालन करना है, यह इंडस्ट्री पर निर्भर करेगा। सबसे आम फ्रेमवर्क्स हैं:
- HIPAA: US हेल्थकेयर में प्रोटेक्टेड हेल्थ डेटा के लिए।
- PCI-DSS: किसी भी एजेंट के लिए जो पेमेंट कार्ड डेटा संभालता है।
- GDPR: EU और EU में ग्राहकों वाले बिज़नेस के लिए डेटा प्राइवेसी की ज़िम्मेदारी।
कंप्लायंस की स्थिति जांचने वाले बिज़नेस के लिए, ElevenLabs के पास AICPA SOC Type II और GDPR कंप्लायंस है, साथ ही AIUC-1 सर्टिफिकेशन भी हासिल है। AIUC-1 खासतौर पर AI एजेंट्स के लिए डिज़ाइन किया गया सिक्योरिटी स्टैंडर्ड है।
रिलायबिलिटी
रिलायबिलिटी हमारे वॉइस एजेंट मूल्यांकन फ्रेमवर्क का आखिरी स्तंभ है, जिसमें देखा जाता है कि एजेंट लगातार रियल-टाइम में डिलीवर कर सकता है या नहीं।
वॉइस एजेंट का मूल्यांकन करते समय इन बातों पर ध्यान दें:
- अपटाइम: किसी भी कस्टमर-फेसिंग डिप्लॉयमेंट में 99.9% अपटाइम की उम्मीद होती है, ताकि आउटेज न हों। खासकर हमेशा-ऑन यूज़ केस में, जैसे इनबाउंड सपोर्ट, भरोसेमंद अपटाइम बहुत ज़रूरी है।
- ग्रेसफुल डिग्रेडेशन: वॉइस एजेंट्स की जटिलता के कारण, अगर कोई कंपोनेंट फेल होने लगे, तो एजेंट को उसे ग्रेसफुली संभालना चाहिए। यानी, ज़्यादा लोड या एरर आने पर इंसान के पास रूट करना, न कि खराब हालत में काम जारी रखना।
- लोड में परफॉर्मेंस: लोड टेस्टिंग में कम से कम 2x अपेक्षित पीक कंकरेंसी को सिम्युलेट करना चाहिए। भारी लोड में टेस्टिंग से लेटेंसी बढ़ने या परफॉर्मेंस गिरने जैसी समस्याएं पता चलती हैं, जो सिर्फ स्केल पर दिखती हैं।
अगर मॉडल बाकी सभी मापदंडों पर खरा उतरता है लेकिन डिमांड के साथ स्केल नहीं कर पाता, तो वह बेकार है। ElevenAgents पर 10,00,000 से ज़्यादा क्रिएटर्स और एंटरप्राइज़ेस भरोसा करते हैं, जिससे प्लेटफॉर्म की एंटरप्राइज़ स्केल पर डिप्लॉयमेंट क्षमता साबित होती है।
वॉइस एजेंट्स के लिए MOS कैसे मापें (स्टेप-बाय-स्टेप)
अगर आपका बिज़नेस MOS मैन्युअली मापना चाहता है, तो आपको इंसानी श्रोताओं का बड़ा ग्रुप और असली बातचीत के ऑडियो क्लिप्स चाहिए होंगे। इसमें फीडबैक इकट्ठा करना, एवरेज निकालना और डेटा को समझना शामिल है।
वॉइस एजेंट्स के लिए MOS मापने का तरीका:
- टेस्ट सेट तैयार करें: अपने एजेंट के ऑडियो आउटपुट्स का प्रतिनिधि सैंपल चुनें, जिसमें कम से कम 100 क्लिप्स अलग-अलग बातचीत से हों।
- रेटिंग सेशन चलाएं: अपने इंसानी श्रोताओं से कहें कि वे हर क्लिप को 1-5 के स्केल पर कम्युनिकेशन एक्सपीरियंस की क्वालिटी के आधार पर रेट करें।
- रेटिंग्स को जोड़ें और स्कोर निकालें: हर क्लिप की एवरेज रेटिंग निकालें, फिर सभी क्लिप्स की एवरेज लेकर ओवरऑल MOS पाएं। 4.3 या उससे ज़्यादा MOS का मतलब है कि आपका वॉइस एजेंट प्रोडक्शन के लिए तैयार है।
भले ही यह प्रक्रिया मैन्युअल है, लेकिन इससे आपको अपने चुने वॉइस एजेंट के लिए ठोस MOS मिलेगा। अगर आप बड़े स्तर पर टेस्ट करना चाहते हैं, तो इंसानी श्रोताओं की जगह NISQA जैसे ऑटोमेटेड टूल्स इस्तेमाल कर सकते हैं, जो प्रोग्रामेटिकली MOS स्कोर प्रेडिक्ट करते हैं। आप इन्हें अपनी एक्टिव पाइपलाइंस में जोड़ सकते हैं, ताकि समय के साथ MOS लगातार मॉनिटर हो सके।
AI बनाम इंसान टेस्टिंग बेंचमार्क्स: FCR, AHT, और CSAT
समय-समय पर MOS निकालना मॉडल में सुधार या गिरावट देखने का तरीका है, लेकिन आप इंसान की परफॉर्मेंस से तुलना करके और भी संदर्भ जोड़ सकते हैं। देखना कि इंसान असल में ऐसी भूमिकाओं में क्या हासिल करते हैं, यह दिखाता है कि आपका वॉइस एजेंट आदर्श स्तर के कितना करीब है।
AI बनाम इंसान टेस्टिंग बेंचमार्क्स के लिए ये कुछ मेट्रिक्स हैं:
AI एजेंट्स को इंसान जैसे FCR और CSAT हासिल करने चाहिए, साथ ही AHT में काफी सुधार करना चाहिए। AHT में सुधार इसलिए होता है क्योंकि AI एजेंट्स आमतौर पर ज़्यादा सामान्य बातचीत संभालते हैं। कई बिज़नेस वर्कफ़्लो में AI एजेंट्स पहले रिस्पॉन्डर होते हैं, और अगर कॉल बहुत जटिल हो तो ही इंसान के पास भेजते हैं।
2025 में Poe (AI तुलना एग्रीगेटर) के डेटा के मुताबिक, ElevenLabs ने सबसे मजबूत ओवरऑल रिक्वेस्ट फुलफिलमेंट क्षमता दिखाई, और सभी इनकमिंग रिक्वेस्ट्स में से 74.4% पूरे किए। इसकी सफलता से Eleven v3 और v2.5-Turbo का इस्तेमाल तेज़ी से बढ़ा है, जो समय के साथ AI मॉडल्स को भेजे गए 60% से ज़्यादा मैसेजेस के लिए जिम्मेदार हैं।
समय के साथ AI मॉडल्स को भेजे गए मैसेजेस, ElevenLabs poe वॉइस एजेंट मूल्यांकन फ्रेमवर्क में सबसे आगे
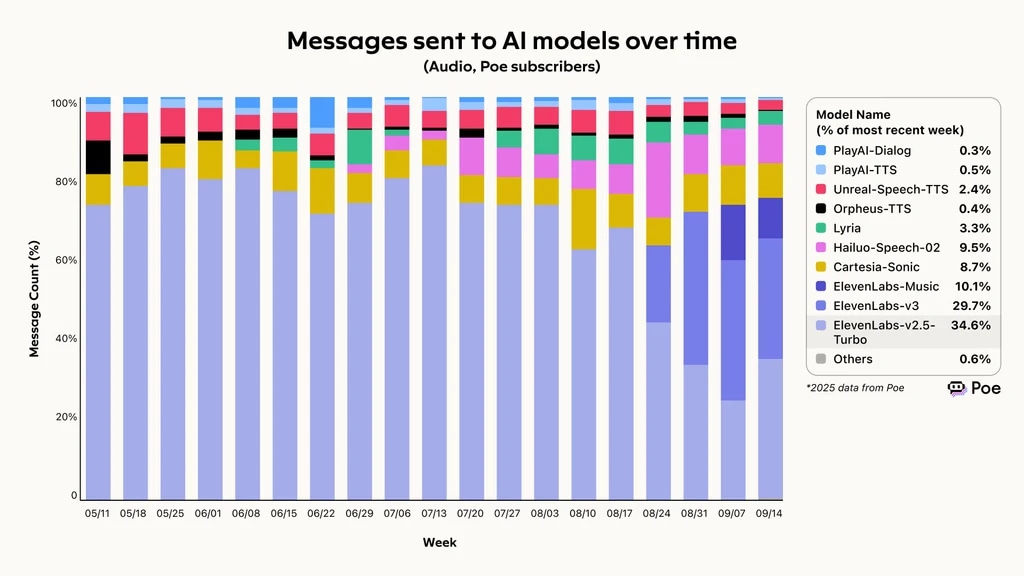
समय के साथ AI मॉडल्स को भेजे गए मैसेजेस, Poe द्वारा बेंचमार्क किए गए
आम वॉइस एजेंट टेस्टिंग गलतियां
वॉइस एजेंट मूल्यांकन फ्रेमवर्क फॉलो करते समय, बेस्ट-केस सीनारियो टेस्ट करना आसान लगता है। असलियत में, आपके ग्राहकों का रोज़मर्रा का अनुभव आदर्श परिस्थितियों से नहीं आता।
ये हैं तीन आम वॉइस एजेंट टेस्टिंग गलतियां और उन्हें कैसे ठीक करें:
- सबसे आसान रास्ता टेस्ट करना: खासकर MOS के लिए ऑडियो क्लिप्स चुनते समय, एज केस भी शामिल करें। बैकग्राउंड नॉइज़ या एक्सेंटेड स्पीच वाली क्लिप्स असल जिंदगी में बहुत आम हैं, इसलिए सिर्फ 'साफ़' ऑडियो पर टेस्ट करने से MOS गलत कैलिब्रेट हो जाएगा।
- रिज़ॉल्यूशन के बजाय कंटेनमेंट को प्राथमिकता देना: अपने मॉडल्स को यूज़र्स को एजेंट सिस्टम में बनाए रखने के लिए ऑप्टिमाइज़ करने से कंटेनमेंट रेट तो बढ़ता है, लेकिन रिज़ॉल्यूशन नहीं। अगर आपका FCR कम है लेकिन कंटेनमेंट रेट हाई है, तो एजेंट यूज़र्स को बार-बार घुमा रहा है। यूज़र्स को इंसानी एजेंट से बात करने का विकल्प ज़रूर दें।
- लेटेंसी पर्सेंटाइल्स को नज़रअंदाज़ करना: SLA में अक्सर लेटेंसी को P95 लेवल पर मापा जाता है। यह ज़्यादातर ग्राहकों के लिए कंसिस्टेंट एक्सपीरियंस देता है, लेकिन आखिरी 5% भी असली ग्राहक हैं। बड़े स्केल पर, 10,000 डेली कॉल्स में 5% यानी 500 लोग स्लो बातचीत का सामना कर रहे हैं। अपने SLA टार्गेट के लिए P99 पर फोकस करें, सिर्फ मीडियन या P95 पर नहीं।
इन बातों का ध्यान रखकर आप आदर्श औसत के बजाय सही और प्रतिनिधि बेसलाइन बना सकते हैं।
यूज़ केस-विशिष्ट मूल्यांकन की ज़रूरत
हालांकि इस फ्रेमवर्क में बताए गए 6 स्तंभ आपको दिशा दिखाते हैं, लेकिन हर स्तंभ का महत्व आपकी इंडस्ट्री पर निर्भर करेगा। उदाहरण के लिए, फाइनेंशियल सर्विसेज़ में बिज़नेस कंप्लायंस और टूल यूसेज को प्राथमिकता देगा, जबकि कंज़्यूमर ब्रांड्स के लिए TTS वॉइस क्वालिटी सबसे अहम होगी।
यहां दो उदाहरण हैं यूज़ केस-विशिष्ट मूल्यांकन के, और कैसे वे हर स्तंभ का संतुलन बदल सकते हैं।
कस्टमर सपोर्ट
कुछ इंडस्ट्रीज़ में, जैसे कॉल सेंटर्स में, First Call Resolution (FCR) जैसे टास्क कंप्लीशन मेट्रिक्स बातचीत का अहम हिस्सा हैं। बिना इंसानी दखल के इनकमिंग कॉल को सफलतापूर्वक संभालना इंसानी एजेंट्स पर बोझ काफी कम कर देता है।McKinsey का अनुमान है कि वॉइस एजेंट्स का इस्तेमाल करने वाले कॉल सेंटर्स इंटरैक्शन वॉल्यूम को 50% तक घटा सकते हैं।
हालांकि टास्क सक्सेस रेट जितना अहम नहीं, लेकिन कंटेनमेंट रेट भी मायने रखता है। कंटेनमेंट रेट कॉल की कुल अवधि को देखता है। अगर कंटेनमेंट रेट बहुत हाई है लेकिन FCR कम है, तो एजेंट्स लोगों को लाइन पर रोके रखते हैं लेकिन समाधान नहीं देते। असल में, इससे ग्राहक को बार-बार एक ही जगह घूमने जैसा अनुभव होता है।
AHT जैसे अन्य मेट्रिक्स भी ट्रैक करें, जिसमें AI एजेंट्स रूटीन समस्याएं जल्दी सुलझाने का लक्ष्य रखते हैं। इसी वजह से, कस्टमर सपोर्ट फील्ड में कन्वर्सेशन क्वालिटी, खासकर टर्न-टेकिंग और फॉलबैक रेट, को अन्य क्षेत्रों से ज़्यादा महत्व मिलेगा।
हेल्थकेयर
हेल्थकेयर एक बहुत रेगुलेटेड फील्ड है, जिसमें सख्त कंप्लायंस ज़रूरतें वॉइस एजेंट ऑपरेशन को बहुत संवेदनशील बना देती हैं। कंप्लायंस यहां मुख्य चिंता है, जिससे फ्रेमवर्क के सुरक्षा स्तंभ का महत्व और इंटेलिजेंस सबसे ऊपर हो जाता है।
हेल्थकेयर चैटबॉट्स को अपॉइंटमेंट शेड्यूलिंग, टेलीहेल्थ एक्सेस, सिम्प्टम ट्रायेज और इंश्योरेंस सवाल संभालने होते हैं। इन सबके लिए हाई इंटेलिजेंस और टूल यूसेज चाहिए, जो फिर दिखाता है कि इंडस्ट्री या रोल-विशिष्ट डिमांड्स तय करते हैं कि कौन सा स्तंभ सबसे अहम है।
आपका बिज़नेस चाहे जिस फील्ड में हो, वॉइस एजेंट मूल्यांकन के मुख्य स्तंभों को समझना और संतुलित तरीके से लागू करना आपको सबसे अच्छे एजेंट्स चुनने में मदद करेगा।
हाई परफॉर्मेंस और कम लेटेंसी के लिए ElevenAgents के साथ बनाएं
जिस प्लेटफॉर्म पर आप बनाते हैं, वही तय करता है कि आपके वॉइस एजेंट्स असली वर्कफ़्लो में कैसे परफॉर्म करेंगे। खासकर जब आप अपने ग्राहकों से इंटरैक्ट करते हैं, तो आपको भरोसा होना चाहिए कि आपका एजेंट हर कैटेगरी में बेहतर करेगा।
ElevenAgents प्रोडक्शन वॉइस डिप्लॉयमेंट्स के लिए बना है, जिसमें इंडस्ट्री-लीडिंग TTS मिलता है Eleven v3, रियल-टाइम STT स्क्राइब v2 के ज़रिए, और एक एजेंट ऑर्केस्ट्रेशन लेयर जो एंटरप्राइज़ स्केल के लिए डिज़ाइन की गई है। हर कंपोनेंट इस फ्रेमवर्क में बताए गए बेंचमार्क्स पर खरा उतरने के लिए बना है, जिससे आप अपने ग्राहकों को हाई-क्वालिटी एक्सपीरियंस दे सकते हैं।
चाहे आप विकल्पों का तुलनात्मक मूल्यांकन कर रहे हों या तुरंत बनाना शुरू करना चाहते हों, ElevenLabs आपके लिए तैयार है। ElevenAgents प्लेटफॉर्म एक्सप्लोर करें और देखें कि यह आपके यूज़ केस से कैसे मेल खाता है, या साइन अप करें और आज ही बनाना शुरू करें।



.webp&w=3840&q=80)
