
Eleven v3 Audio Tags: Emotionalen Kontext in Sprache ausdrücken
- Kategorie
- Ressourcen
- Datum
Wie wir KI-Systeme entwickeln, die in Echtzeit kommunizieren – mit Einblicken in technische Entscheidungen zu Gesprächsführung, Latenz und ausdrucksstarker Wiedergabe sowie den Modellen, die wir bereitgestellt haben.

Wir arbeiten seit Jahren auf diese Kategorie hin. Dieser Beitrag zeigt, was wir entwickelt haben, und erläutert die zugrunde liegenden Forschungs- und Produktentscheidungen.
Unser Flaggschiffprodukt – ElevenAgents mit v3 Conversational
Expressive Mode – Mark – Persönlicher Kredit Inbound (Panik) – Launch-Asset.mp4
Drei Faktoren müssen zusammenkommen, damit ein Interaktionssystem zuverlässig funktioniert und natürliche, ansprechende Interaktionen ermöglicht:
*Bezieht sich nur auf die Inferenzzeit des Modells. Die tatsächliche End-to-End-Latenz hängt unter anderem von Standort und verwendetem Endpunkt ab.
Einige unserer bisherigen Entwicklungen
Spekulatives Turn-Taking.Eine separate Funktion in v3 Conversational, die während Nutzerpausen die LLM-Antwortgenerierung vorab startet und so die wahrgenommene Latenz reduziert.
Flash v2.5.Unser schnellstes Text to Speech-Modell für Echtzeitanwendungen mit niedriger Latenz, etwa 75 ms Inferenzzeit.*
Scribe v2.Unser Speech to Text-Modell mit branchenführender Genauigkeit.
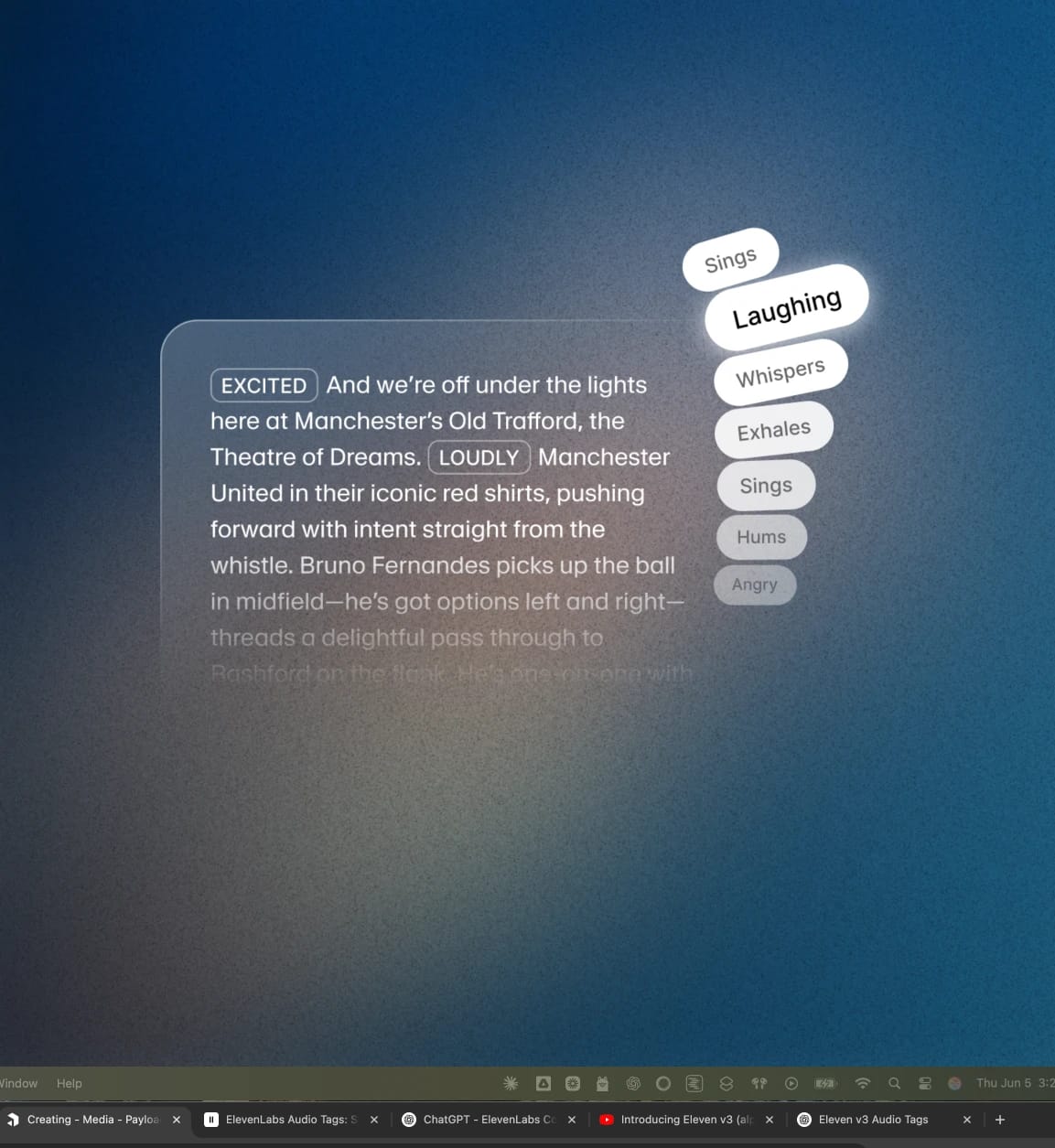
ElevenAgents Expressive Mode.Ermöglicht Agenten den Einsatz von ausdrucksstarken Tags wie [lacht], [flüstert], [seufzt] und [langsam], um die Wiedergabe im Kontext zu steuern.
ElevenAgents Expressive Mode.Ermöglicht Agenten den Einsatz von ausdrucksstarken Tags wie [lacht], [flüstert], [seufzt] und [langsam], um die Wiedergabe im Kontext zu steuern.
ElevenAgents Expressive Mode.Ermöglicht Agenten die Nutzung von ausdrucksstarken Tags wie [lacht], [flüstert], [seufzt] und [langsam], um die Wiedergabe im Kontext zu steuern.
Wohin die Entwicklung geht
Viele KI-Gespräche wirken noch wie Anfragen. Echte Gespräche tun das nicht. Diese Lücke zu schließen, ist unser Ziel.



