Eleven v3 Audio Tags: Situatives Bewusstsein für KI-Audio
- Verfasst von
- Ryan Morrison
- Veröffentlicht
- Zuletzt aktualisiert
AnhörenArtikel anhören
Audio-Tags sind ein grundlegender Bestandteil des neuen
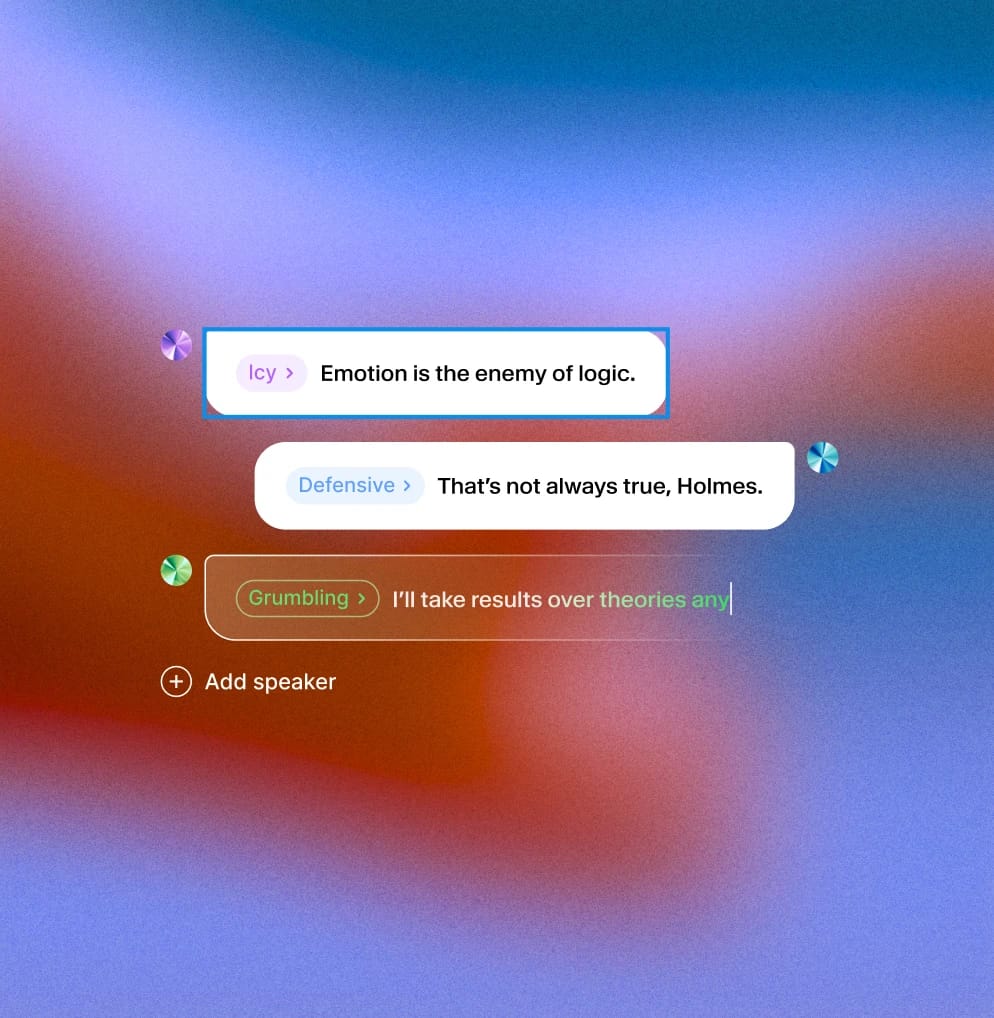
In ihrer einfachsten Form sind Audio-Tags Wörter in eckigen Klammern. Das Modell interpretiert diese als Hinweise zur Darbietung. Das bedeutet, dass Sie die Wiedergabe mitten im Satz anpassen können, um emotionale Akzente oder situative Veränderungen widerzuspiegeln – und der KI ein gewisses Maß an situativem Bewusstsein verleihen.
Was bedeutet situatives Bewusstsein in KI-Sprache?


Situatives Bewusstsein bedeutet, dass die KI ihre Wiedergabe an den Moment anpasst. Mit Audio-Tags steuern Sie nicht nur, was das Modell sagt – sondern auch, wie es reagiert.
Ob Sie mit einem [SHOUTING]-Tag Dringlichkeit hinzufügen, eine Warnung mit einem [WHISPER] abschwächen oder mit [SIGH] Zögern signalisieren, Tags verwandeln Erzählung in Darbietung. Sie sind besonders wertvoll in kontextreichen oder dynamischen Szenen.
Darbietung, nicht nur Lesen
Stellen Sie sich vor, Sie schreiben ein Veo 3 Highlight-Video eines Fußballspiels zwischen 11 United und 12 United. Sie möchten, dass die Intensität mit der Aktion steigt: „Er umspielt einen Verteidiger – [EXCITED] hier kommt die Flanke – [SHOUTING] TOOOOR!“
Oder Sie vertonen einen spannenden Moment in einem
Dies sind keine stilistischen Ergänzungen. Sie definieren den Moment und bestimmen, wie er sich anfühlt. Das Modell liest nicht – es performt.
Gängige Tags für situativen Einsatz
Audio-Tags ermöglichen es Ihnen, eine Reihe von emotionalen und physischen Hinweisen zu simulieren:
- Emotionale Tonlage:[AUFGEREGT], [NERVÖS], [FRUSTRIERT], [MÜDE]
- Reaktionen:[KEUCHT], [SEUFZT], [LACHT], [SCHLUCKT]
- Lautstärke & Energie:[FLÜSTERN], [SCHREIEN], [LEISE], [LAUT]
- Tempo & Rhythmus:[PAUSEN], [STOTTERN], [GEHETZT]
Tags können geschichtet werden, um Nuancen hinzuzufügen: „[NERVOUSLY] Ich... ich bin mir nicht sicher, ob das funktionieren wird. [GULPS] Aber versuchen wir es trotzdem.“
Darbietung, die Sie steuern können
Eleven v3 unterstützt diese Tags mit einem tieferen Kontextmodell. Es kann den Ton mitten im Satz ändern, Unterbrechungen handhaben und den Fluss aufrechterhalten – und bietet Ihnen eine Wiedergabe, die natürlicher wirkt, ohne das Skript neu zu schreiben.
Für
Die richtige Stimme auswählen
Professionelle KI-Stimmenklone (PVCs) sind derzeit noch nicht vollständig für Eleven v3 optimiert. Die Klonqualität kann daher niedriger sein als bei früheren Modellen. In dieser Forschungsphase empfiehlt es sich, für v3-Funktionen einen Instant-