在 ElevenAgents 中处理图片和文档
- 发布时间
- 最近更新
收听收听本文
工地主管发现材料短缺,拍照后通过 WhatsApp 发送给采购智能体,并用语音确认收货地址。智能体处理照片,识别缺少的材料,并在同一次对话中完成加急下单。企业工作流程中,很多关键信息仅靠文字难以传递,可能需要通过损坏物品的照片或政策 PDF 文件来补充。直接将这些信息传递给智能体,可以简化对话流程,加快问题解决。当客户能“展示”而不是“描述”时,智能体无需让客户切换渠道,排查速度更快。Rohlik是欧洲最大的线上生鲜平台之一,智能体支持电话、网页、App 和 WhatsApp 六种语言,自动解决 90% 的客户咨询。多模态输入让客户需要“展示”时也能保持高解决率。ElevenAgents 将文件作为一等输入,和语音、WhatsApp、网页、移动端等渠道统一处理。文件会作为原生消息传递给底层模型,因此同一个智能体可以在一条对话中处理所有输入类型。
本文介绍平台上的多模态输入含义、文件如何从客户设备进入模型上下文、各渠道支持的输入类型,以及客户回访时如何保留上下文。
渠道与输入类型
ElevenAgents 基于企业常用的客户沟通渠道构建,包括网页和移动应用、客服平台、电话、短信、邮件、WhatsApp 等。智能体配置(提示词、模型、工具、知识库和音色)只需设置一次,可在所有渠道共享。每个渠道不同的只有传输层和支持的输入类型。网页和移动应用可通过嵌入式组件、SDK 或 Agents WebSocket 连接。电话通话可通过原生 Twilio、SIP 中继或基于 websocket 的原生集成接入
目前网页、移动端和 WhatsApp 支持文件输入(图片和 PDF)。输入处理以类型为驱动,而非渠道:同一 WhatsApp 会话中,照片和语音消息会走完全不同的处理流程,最终都在传递给模型前汇聚到同一预处理层,作为原生上下文传递,分为两种路径。
输入表示方式:文件引用与内联
无论输入类型或渠道,平台都会将每个输入标准化为两种内部表示之一,再传递给模型。分类方式决定了输入在模型上下文窗口中的编码方式,以及集成时需要如何处理。
文件引用输入
图片和 PDF 会作为原生文件引用传递给模型,而不是文本摘要。平台会存储文件,分配一个file_id,并将该标识符绑定到用户本轮对话。具备视觉或文档处理能力的模型会直接在上下文窗口接收原始文件,而不是衍生表示。集成要求很简单:获取上传接口返回的file_id,并在消息体中引用。如果消息未包含file_id,模型就无法关联到文件,即使上传已成功。文件存储仅限于当前会话,若需在会话结束后保留(包括文件本身、提取字段或结构化输出),需由集成端自行处理。具体方式因渠道和场景而异。
内联输入
第二种表示方式为内联,适用于其他所有输入。语音和语音消息会被转写。文本输入、转写语音、WhatsApp 定位和联系人卡片等,都会在模型运行前标准化为转录文本。定位会转为坐标和可选地址,联系人转为姓名和手机号。这些不会作为文件存储,也不会生成文件引用,直接保存在转录文本中。
为何区分这两种方式
区分方式决定了集成工作重点。内联路径无需额外操作,平台会自动标准化为文本,直接写入转录内容。文件引用路径则有独立的集成接口。平台不会在模型运行前将文件内容转为文本,而是直接将原始文件传递给模型上下文。模型可基于文件结构处理,而不是仅依赖文本描述,保留空间关系、视觉布局和文档格式。理解这一区别后,后文将介绍具体实现:如何配置智能体、文件如何在各渠道流转、如何在多次会话中保留上下文。
配置多模态输入
启用多模态输入时,网页、移动端和 WhatsApp 使用同一套智能体配置。之后,文件上传和后续获取方式会因渠道而异。
启用文件输入
要支持文件输入,需在智能体配置中设置两项。首先,将conversation_config.conversation.file_input.enabled设为True,可在创建智能体时通过 API 设置,或在控制台设置 > 高级设置 > 文件输入中开启。其次,需配置具备视觉和文档处理能力的模型。仅设置开关无效,模型本身也必须支持图片或文档处理,二者缺一不可。
SDK 与 WebSocket
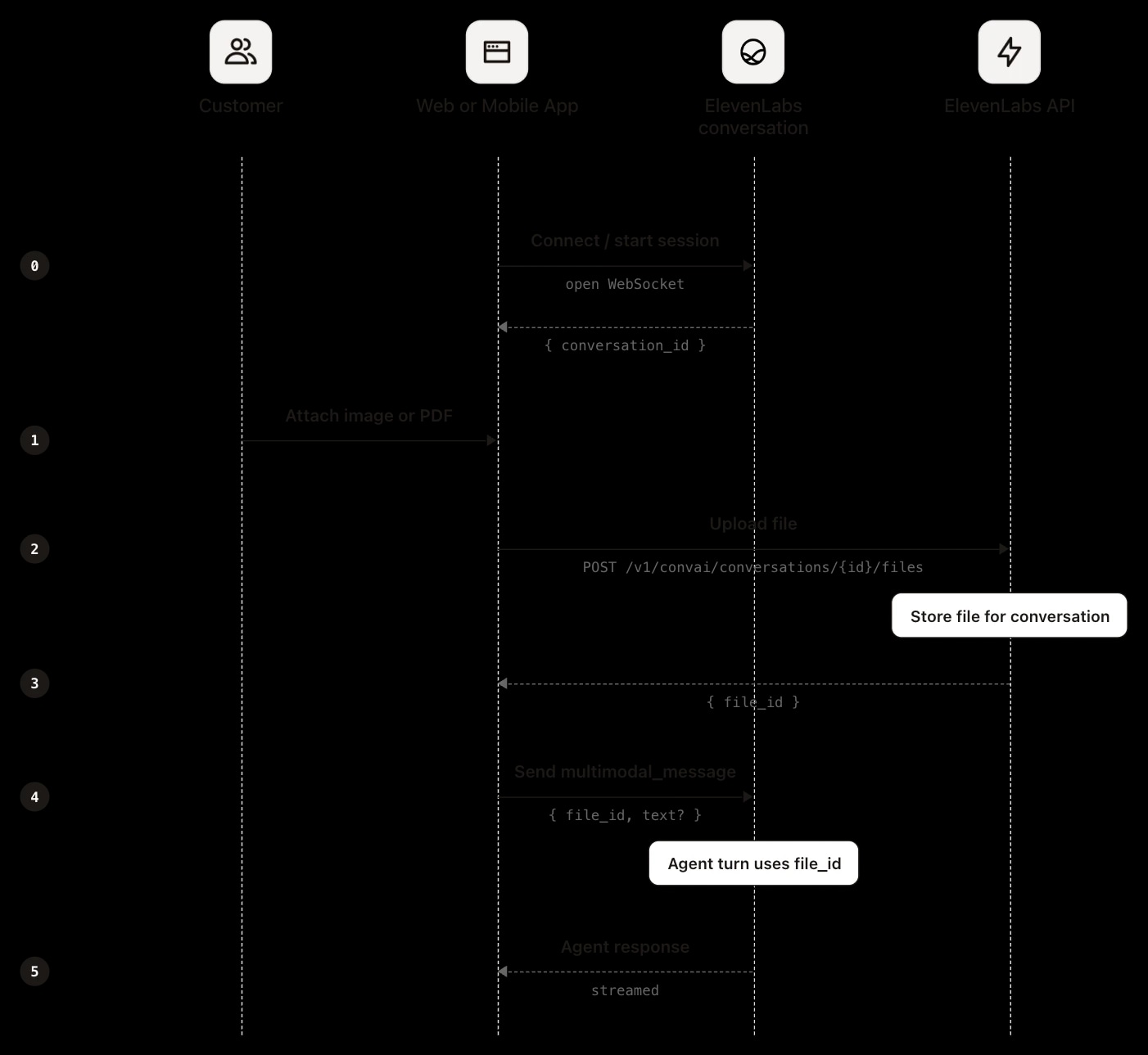
网页或移动端的文件输入需基于 SDK 或原生 Agents websocket 自定义聊天客户端。三者流程一致,且顺序必须严格:文件需先上传,消息体需引用上传返回的标识符。
先上传文件:
详见文件上传,包含完整请求与响应示例:
然后通过连接发送引用返回file_id的消息:
SDK 会将上传和引用步骤封装为一次调用,内部自动处理文件标识。详见multimodal_message 规范,了解完整消息格式。由于上传由应用端完成,文件此时已在本地。如仅用于当前会话,上传并引用标识即可。如需长期保存,建议在上传时由应用端自行存储。也可通过 post-call webhook 获取,详见会话上下文部分。
在 WhatsApp 渠道,应用端无需处理上传。客户发送图片、文档或贴纸时,文件先进入 Meta 基础设施。Meta 通过 WhatsApp Business API webhook 通知 ElevenLabs,ElevenLabs 用你绑定的 WhatsApp Business 账号凭证服务器间下载文件,存储副本,并像网页或 SDK 上传一样绑定到会话。智能体将其作为多模态输入,转录中记录file_input事件。
应用端不会直接接触文件,也无法像网页和移动端那样在上传时获取。文件会通过file_url在 post-call webhook 中传递,指向 ElevenLabs 存储的副本。Meta 的媒体 URL 仅用于采集,不会对外暴露。文件获取方式及下载时效,详见会话上下文部分。
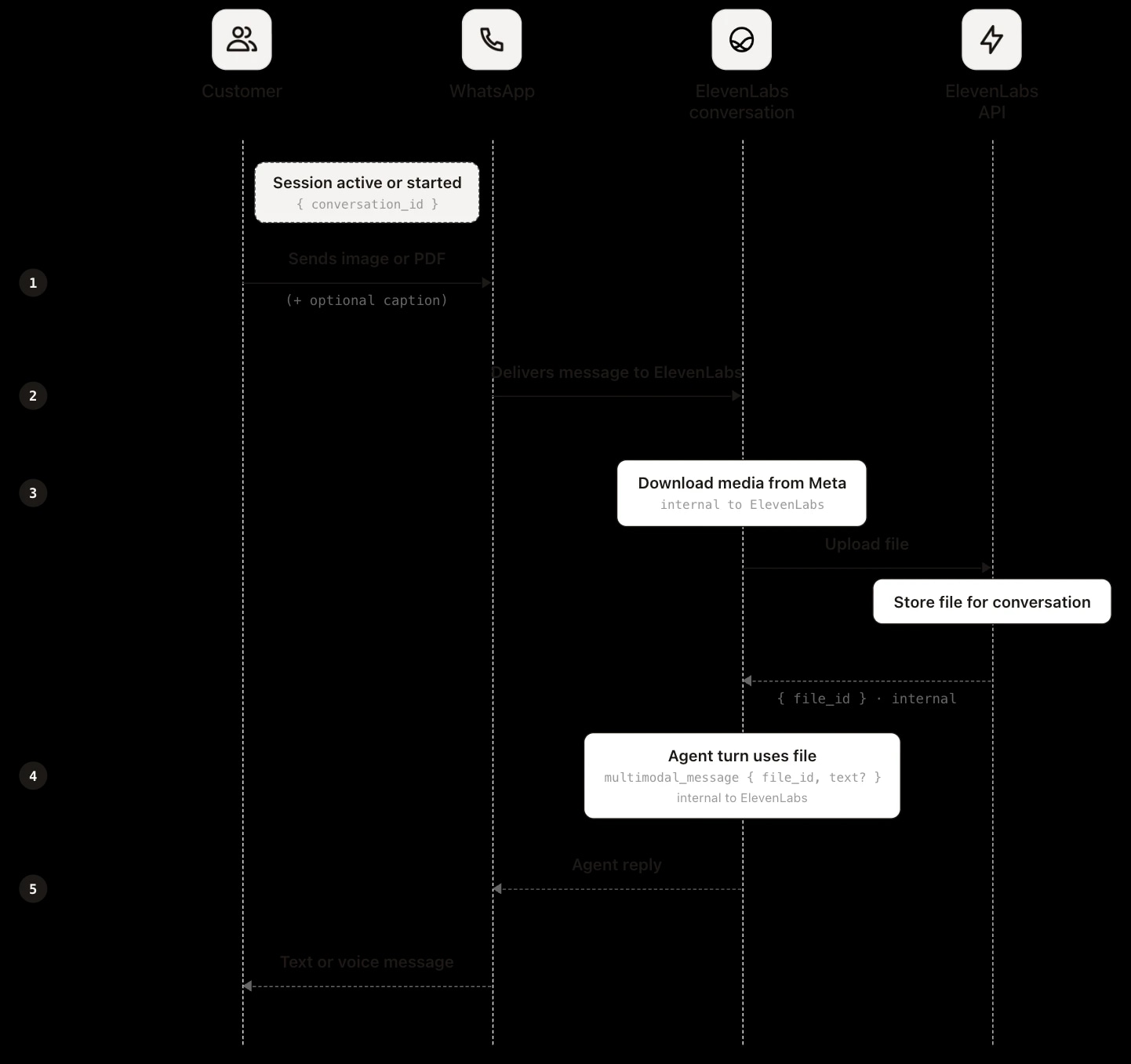
在 WhatsApp 渠道,客户直接在聊天中发送文件。ElevenLabs 从 Meta 获取、存储,并在平台侧绑定file_id。因此无需客户端上传步骤。与网页和移动端不同,应用端无需调用 POST/v1/convai/conversations/{id}/files或通过 WebSocket 发送multimodal_message。ElevenLabs 负责文件传递、存储和智能体处理。
多会话上下文传递
ElevenAgents 独立处理每次会话。客户发送的内容和智能体在会话中解决的问题,不会自动带入下次会话。会话结束后,智能体会通过 post-call webhook 将所有内容传递给你的系统,但跨会话的记忆需在 ElevenLabs 之外维护。是否保留连续性由你决定。
这一架构边界值得重点设计。多模态输入最常见的场景(如客户拍摄损坏物品、上传政策文档、分享定位)往往无法一次会话解决。客户上传损坏零件照片并预约回电时,期望智能体下次能记住照片。若未显式管理上下文,智能体每次都从零开始,客户需重复描述。解决方案分两步:会话结束时,post-call webhook 会返回转录、分析结果、结构化数据字段和所有文件的 URL。你的后端需将相关内容与客户标识(如手机号、用户 ID、账号)关联保存。客户回访时,应用端在会话开始通过动态变量注入已存上下文,让智能体带着已有信息开始对话。对于文件引用输入,webhook 负载中的文件 URL 指向 ElevenLabs 存储副本,是会话结束后唯一的获取方式。平台副本仅限于本次会话,若需在后续会话或自有系统中使用,需在 webhook 到达后及时下载。下载时效取决于保留策略,详见参考文档。webhook 负责导出状态,动态变量负责导入。中间环节由你的系统负责,客户回访、升级或中途继续时,集成工作重点就在这里。
上下文注入方式因渠道而异
注入机制随渠道不同,但核心模式一致。电话渠道,ElevenLabs 会在通话接通前调用你的服务器,你可根据来电号码查找客户并返回动态变量(如姓名、订单号、账号等级),智能体在通话前获取。WhatsApp 渠道,每条入站消息会触发预处理 webhook,你可在智能体处理前补充身份和业务上下文。其他渠道则在会话开启时通过conversation_initiation_client_data字段传递。ElevenAgents 不会将不同渠道的会话合并为同一线程。即使同一客户,WhatsApp 和网页会话也是独立的。但 webhook 输出和动态变量注入方式一致,因此只需一套持久化逻辑即可覆盖所有渠道。上下文注入适用于文本类数据:姓名、订单号、摘要、结构化字段。文件需单独处理。
文件的跨会话传递
文件仅限于单次会话,不会自动保留。是否需要传递取决于下次会话是否需要文件信息或原文件本身。大多数情况下只需信息即可。智能体会在收到文件时解析,但不会自动将解析结果长期保存。结构化输出可通过 post-call 数据获取:转录、摘要和你定义的数据字段。例如客户上传破损门封照片,一周后回访理赔,无需再次上传照片,只需让智能体知道理赔内容即可。你可从 post-call 数据中提取关键信息,关联到客户标识,下次通过动态变量注入。简短摘要或结构化字段通常已足够。
如确需原文件(如合规、存档或下游系统),可通过 post-call webhook 获取。每个上传文件会在转录中以file_input事件出现,并带有签名文件 URL。该 URL 有效期为 15 分钟,建议 webhook 到达后立即下载保存。如错过窗口且会话仍在,可通过 GET conversation API 获取新 URL。请注意,部分场景(如零保留模式)可能没有file_input,不要假设每次文件输入都带 URL。
以上涵盖了完整生命周期:文件进入会话,模型原生处理,结构化输出通过 webhook 导出,持久化层决定智能体下次会话的已知内容。
总结
同一套智能体配置即可在网页、移动端和 WhatsApp 接收图片和 PDF,无需为每个渠道单独开发。文件会标准化、绑定到对话轮次,并作为原生块传递给模型,空间布局、视觉结构和文档格式均可保留。多会话上下文在所有渠道遵循同一模式:post-call webhook 导出状态,动态变量导入。
如果你正在基于 ElevenLabs Agents 开发,希望智能体能同时处理图片、文档、语音和文本,欢迎启用多模态输入并反馈体验。




