テキスト読み上げとスピーチtoテキスト:何が違う?
- 公開日
- 最終更新日
聴くこの記事を聴く
こんな場面を想像してください。通勤中、スマートフォンが未読メールをテキスト読み上げソフトウェア(TTS)で読み上げてくれます。さらに、スマホに触れたり目を離したりせずに返信もできるのは、スピーチtoテキスト(STT)ソフトのおかげです。
これらの技術は、単なる未来的なアイデアではありません。すでに日常生活の中で欠かせない存在となり、日々の作業をシンプルにし、アクセシビリティも高めています。
AIを活用したTTSとSTTの世界を深掘りし、それぞれの特徴や違い、仕組み、TTSやSTTプロバイダー選びのポイント、そしてさまざまな業界での活用例についてご紹介します。
TTSとスピーチtoテキストの違い
TTSとスピーチtoテキスト技術にはいくつかの大きな違いがあります。主なポイントは以下の通りです。
機能の違い
TTS(テキスト読み上げ)は、書かれたテキストを音声に変換します。一方、スピーチtoテキスト(STT)はその逆で、話された言葉をテキストに書き起こします。TTSは、視覚障害や学習障害のある方のために、テキストを聞けるようにする音声アシスタントとして活用されます。STTは、話した内容をテキスト化することで、音声入力やディクテーションに役立ちます。
利用シーン
TTSは、電子書籍リーダーや公共アナウンス、バーチャルアシスタントなどで音声出力としてよく使われています。STTは、文字起こしサービスや音声操作アプリ、聴覚障害者向けのリアルタイム字幕などで活用されています。TTSは主に「出力」に特化し、情報を音声で伝える役割です。対してSTTは「入力」に特化し、話された言葉を捉えて処理する役割があります。
技術的アプローチ
TTS技術は、テキスト解析・言語処理・音声合成を組み合わせて、イントネーションやリズムなど話し言葉のニュアンスを再現します。STTは、高度な音声認識技術を使い、さまざまなアクセントや方言、話し方をリアルタイムで正確にテキスト化します。
TTS(テキスト読み上げ)とは?
TTS(テキスト読み上げ)は、書かれたテキストを音声に変換する技術です。基本的に、TTS はコンピューターにテキストを読み上げさせ、どんな文章でも合成音声に変換できます。この技術は、バーチャルアシスタントから読書が苦手な方のためのアクセシビリティツールまで、幅広く活用されています。
高度なTTS技術の代表例がElevenLabsのTTS機能です。ElevenLabsのTTSは、非常に自然で人間らしい音声を生成できる点が特長です。高度なAIアルゴリズムを活用し、人間の声の響きだけでなく、自然な話し方の抑揚やニュアンスまで再現します。
このリアルさにより、ElevenLabsのTTSはさまざまなメディア向けの魅力的な音声コンテンツ作成や、音声フィードバックによるユーザーインターフェースの強化、視覚障害者向けの読み上げ代替手段としても最適です。
スピーチtoテキスト(STT)とは?
Text from Speech, also known as Speech to Text (STT), is the process of converting spoken language into written text. This speech recognition technology is pivotal in creating transcriptions from audio recordings, enabling voice commands, and facilitating real-time captioning for accessibility.
ElevenLabs made significant advancements in STT technology. Our Scribe model efficiently converting audio and video into text in 99 languages. It offers a user-friendly interface, making it ideal for capturing meetings, lectures, and interviews in written form, from audio and video files.
TTSはどのように動作する?
TTS(テキスト読み上げ)技術は、書かれたテキストを音声に変換します。このプロセスにはいくつかのステップがあります。
まず、TTSシステムがテキストを分解し、言語の最小音単位である音素に区切ります。この分割によって、さまざまな単語を正確に発音できるようになります。
音素への分割が終わると、システムはこれらの音をデジタル音声に変換します。ここでAI(人工知能)が重要な役割を果たします。大量の話し言葉データで訓練されたAIアルゴリズムを使い、人間らしいトーンやリズムの音声を生成します。生成された音声は音素と組み合わされ、自然な仕上がりになります。
AIや機械学習の進化により、現代のTTS技術は大きく進化しました。文脈のニュアンスを理解したり、多言語に対応したり、感情の抑揚をある程度再現できるようになっています。これにより、より自然で親しみやすいデジタル音声体験が実現しています。
おすすめのTTSプロバイダーは?
The best TTS software solutions are ElevenLabs, Murf, and PlayHT. Here’s a brief rundown of their main features, pros, cons, and rating out of 5.
スピーチtoテキストはどのように動作する?
スピーチtoテキスト(STT)技術は、話し言葉を複雑なプロセスでテキストに変換します。
まず、マイクなどで話し言葉を録音します。この音声入力をシステムが処理できるデジタルデータに変換します。STTの核となるのは、このデジタル音声を分析する能力です。高度なアルゴリズムで音声を小さな単位に分解します。
これらの単位は音素と呼ばれ、話し言葉の最小音単位です。STTシステムは、これらの音素をあらかじめ定義された言語モデルと照合し、単語やフレーズを特定します。この工程は、さまざまなアクセントや方言、話し方の違いを理解するために重要です。
次に、システムは自然言語処理(NLP)技術を使います。NLPによって話し言葉の文脈や構文を理解し、より正確な文字起こしが可能になります。また、複雑な文や業界特有の用語にも対応できます。
高度なSTTシステムは、機械学習やディープラーニングも活用し、使えば使うほど精度が向上します。これにより、新しい話し方やアクセント、言語にも対応できるようになり、認識精度や効率が高まります。
まとめると、STT技術は音声の取得、音素分析、言語モデル、NLP、そして機械学習を組み合わせて、話し言葉を効果的にテキスト化しています。
おすすめのスピーチtoテキストプロバイダーは?
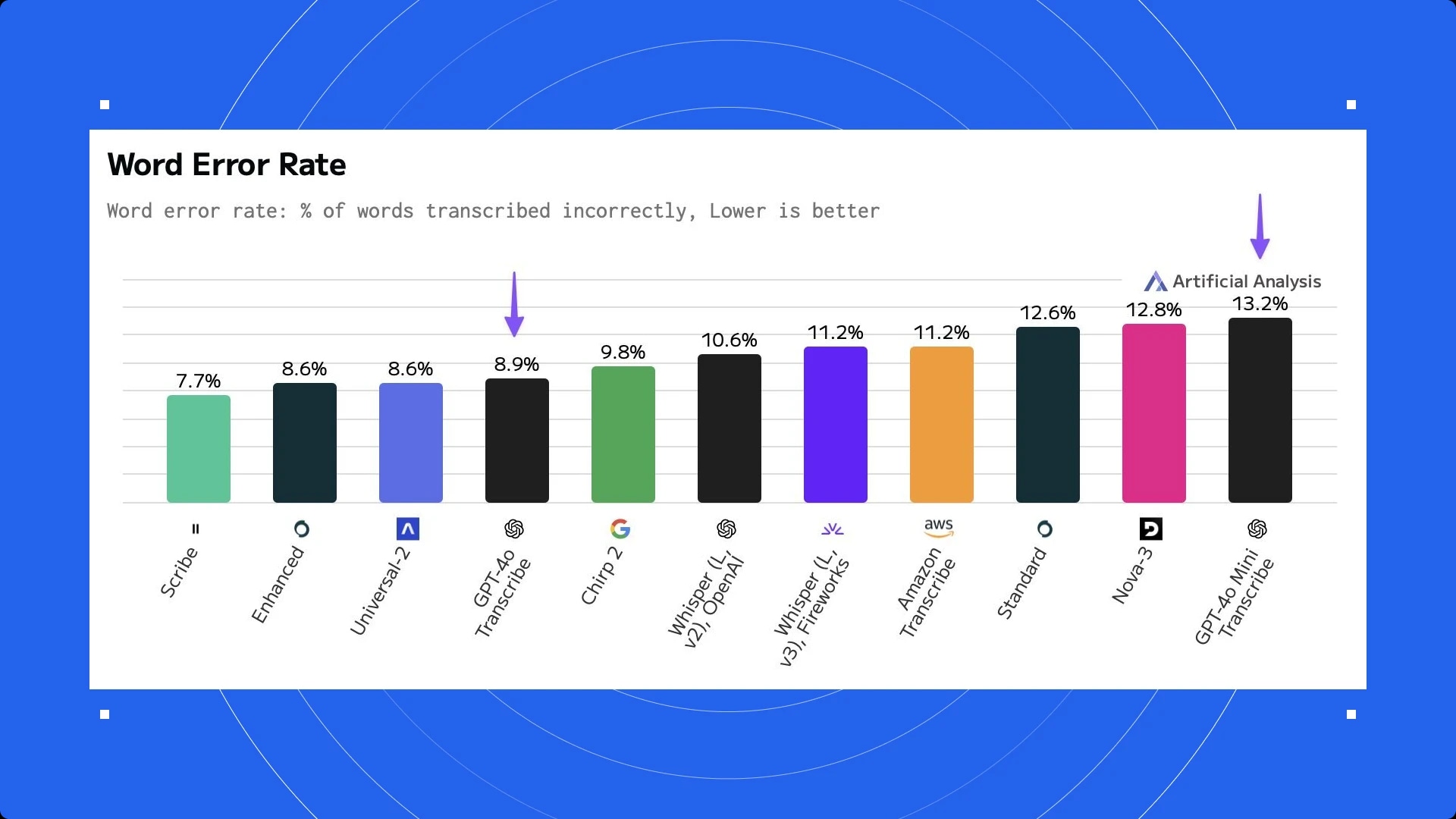
The best speech-to-text providers are ElevenLabs' Scribe, followed by OpenAIand other providers like Google.
TTSとSTT:精度と課題
TTSとスピーチtoテキスト技術は、人間に近い精度を目指して進化しています。精度は年々向上していますが、完璧とは言えません。ここでは両技術の精度や課題についてご紹介します。
TTS(テキスト読み上げ)の精度と課題
AI音声TTS技術は大きく進化していますが、課題も残っています。最大の課題は、より自然な人間らしい声を実現することです。現代のTTSはクリアで聞き取りやすい音声を生成できますが、人間らしい抑揚や感情を込めるのはまだ難しい部分があります。また、文脈による単語の発音ミスや、多様なアクセントや話し方への対応など、グローバルなアクセシビリティのためにはさらなるカスタマイズも必要です。
スピーチtoテキスト(STT)の精度と課題
STT技術はディープラーニングの進化で精度が向上していますが、騒がしい環境ではバックグラウンドノイズが認識の妨げになることがあります。また、多様なアクセントや方言の正確な認識も大きな課題です。さらに、同音異義語(発音は同じでも意味が異なる単語)や複雑な文、スラングの理解が難しく、実際の利用シーンでの効果に影響することもあります。
さまざまな業界での活用例
TTSとスピーチtoテキスト技術は、多くの業界で新しい活用方法が生まれており、情報との関わり方やアクセシビリティを大きく変えています。
TTSの業界での活用例
TTS技術はさまざまな分野で活用されています。教育分野では、読書が苦手な生徒や視覚障害のある方のために、教材をアクセシブルにするのに役立ちます。たとえば、教科書をオーディオブック化するなどです。
自動車業界では、TTSがカーナビの音声案内を支えています。カスタマーサービス分野では、コールセンターの自動応答にTTSが使われ、業務効率化に貢献しています。さらに、エンタメ業界ではゲームやバーチャルアシスタントなど、インタラクティブなユーザー体験にも活用されています。
STTの業界での活用例
STT技術も多様な業界で活躍しています。医療分野では、医師と患者の会話や診療記録の文字起こしに役立ち、業務効率化を実現します。法律分野では、法廷での発言や書類の文字起こしに利用されています。メディア業界では、放送のリアルタイム字幕生成により聴覚障害者のサポートにも貢献。ビジネス分野では、会議の議事録作成や情報共有の効率化にも役立っています。
まとめ
TTS(テキスト読み上げ)とスピーチtoテキスト(STT)は、一見似ているようで異なる役割を持っています。TTSはテキストを音声に変換し、人間らしい声で文章を「聞ける」ようにします。一方、STTは話し言葉をテキスト化し、話し言葉のニュアンスを文字で記録します。
どちらも高度なAI技術を活用していますが、用途は異なります。TTSはテキストを音声で聞きたいとき、STTは話し言葉を記録したいときに活躍します。
始めてみませんか?まずは Eleven v3、これまでで最も表現力豊かなテキスト読み上げモデルをお試しください。
最先端のTTS技術を体験したい方は、ElevenLabsに登録してみてください。きっとご満足いただけます。




