

























Rafforzare e proteggere le elezioni
- Categoria
- Azienda
- Data
Trusted by 1M+ users • Free to start



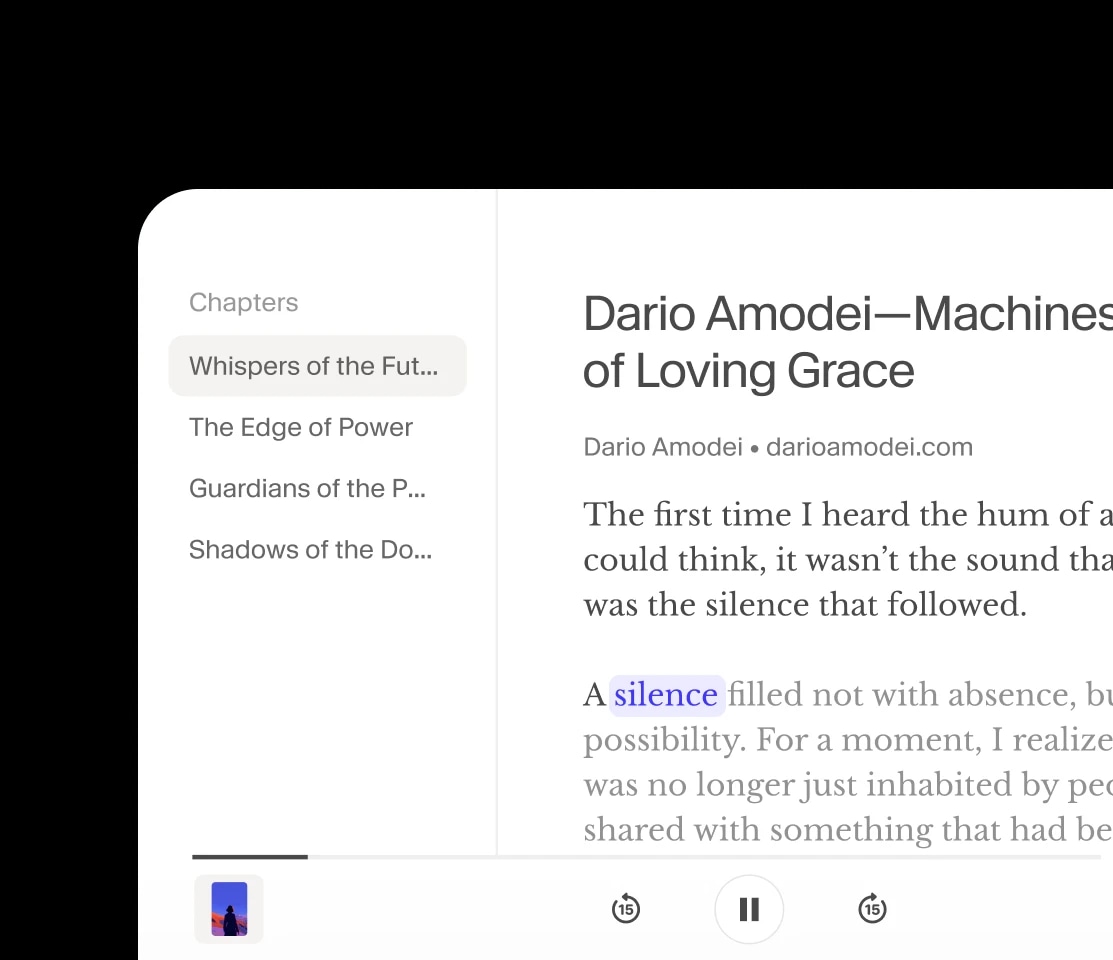
Narrazione
Voci espressive che danno vita ad audiolibri e podcast.
Pubblicità
Voci persuasive che spingono all’azione e rafforzano il ricordo del brand.
Personaggi
Voci vivaci e coinvolgenti per cartoni animati o videogiochi.
Narrazione
Voci espressive che danno vita ad audiolibri e podcast.
Conversazione
Voci naturali ideali per contesti informali.
Social Media
Voci di tendenza e d'impatto per contenuti brevi.

Create controllable, expressive speech layered with emotion, audio events, and immersive soundscapes.
La voce si è fermata un attimo, [a bassa voce] come se raccogliesse i pensieri prima di continuare. Ogni respiro sembrava intenzionale, ogni esitazione perfettamente calibrata.
Non era più una voce sintetica [ride calorosamente] - era una voce che capiva il ritmo, l’emozione e lo spazio tra le parole.
Il testo si è trasformato in presenza. [sospira soddisfatta] Parole che prendono vita, personalità, anima.
Explore an ever-growing collection of expressive, lifelike voices for any use case - from narration to character creation.
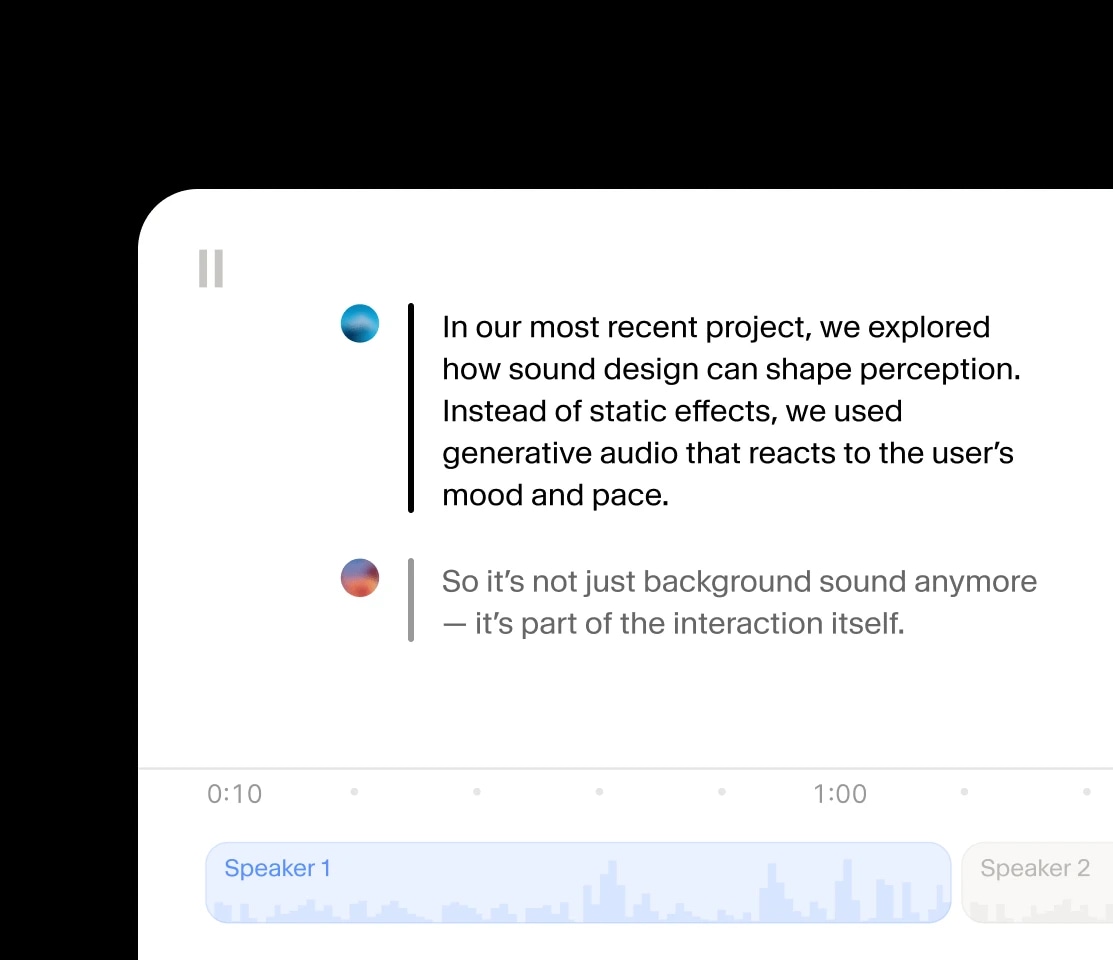
Create audio conversations where speakers share context and emotion.
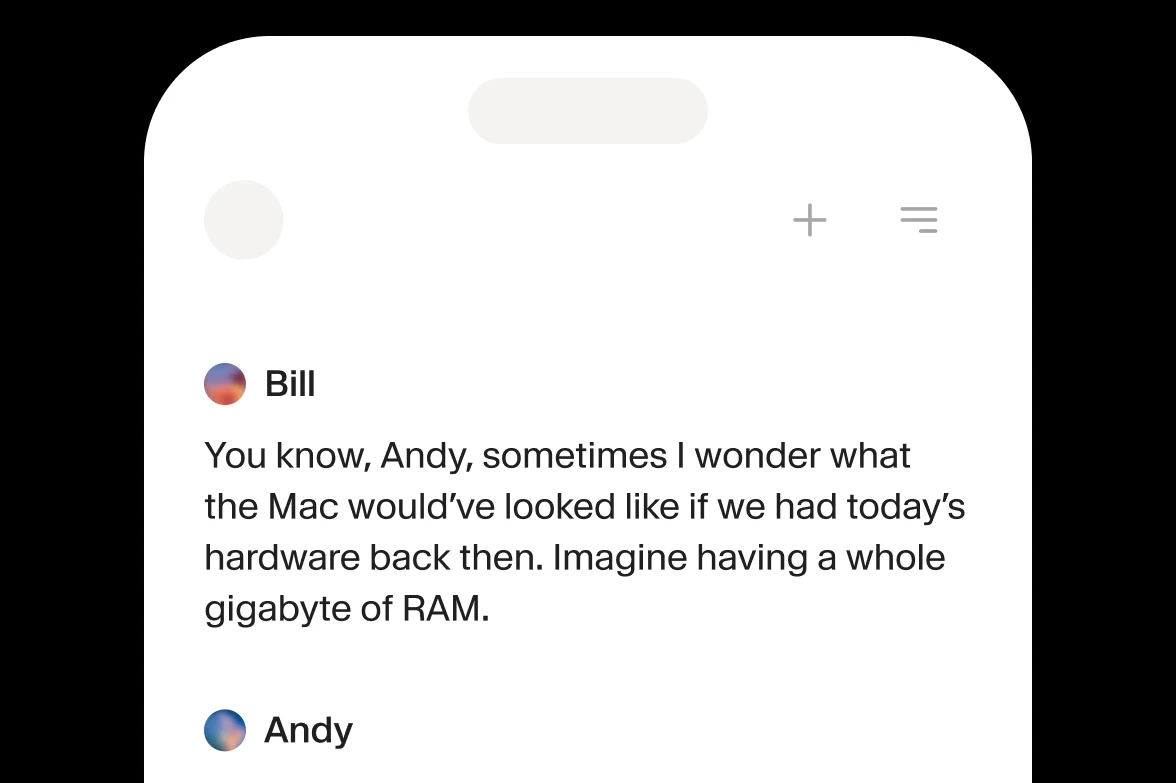
Instantly replicate your own voice or craft unique AI Voices with full control.
Bring stories to life in over 70 languages, all with native-level emotion and clarity.
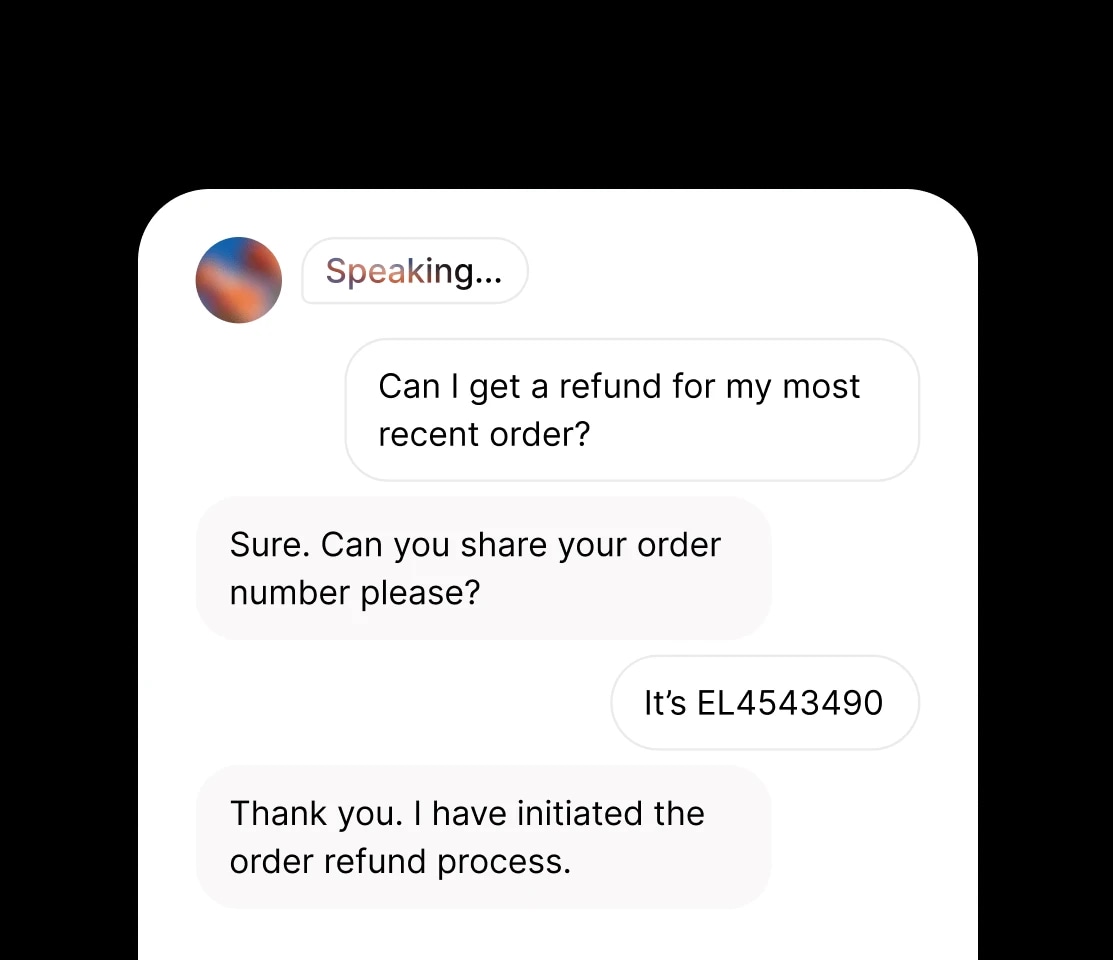



Our most advanced, expressive model with audio tags for precise emotional control. Best for storytelling, gaming and media production in 70+ languages.

Our most lifelike, emotionally rich text to speech model supporting 29 languages. Best for voiceovers, audiobooks, post-production and content creation.

Our high quality, low latency TTS model in 32 languages. Best for developer use cases where speed matters and you need non-English languages

High quality, low-latency model with a good balance of quality and speed

The best AI audio models in one powerful editor.

Generate expressive audio in seconds using our iOS and Android apps.
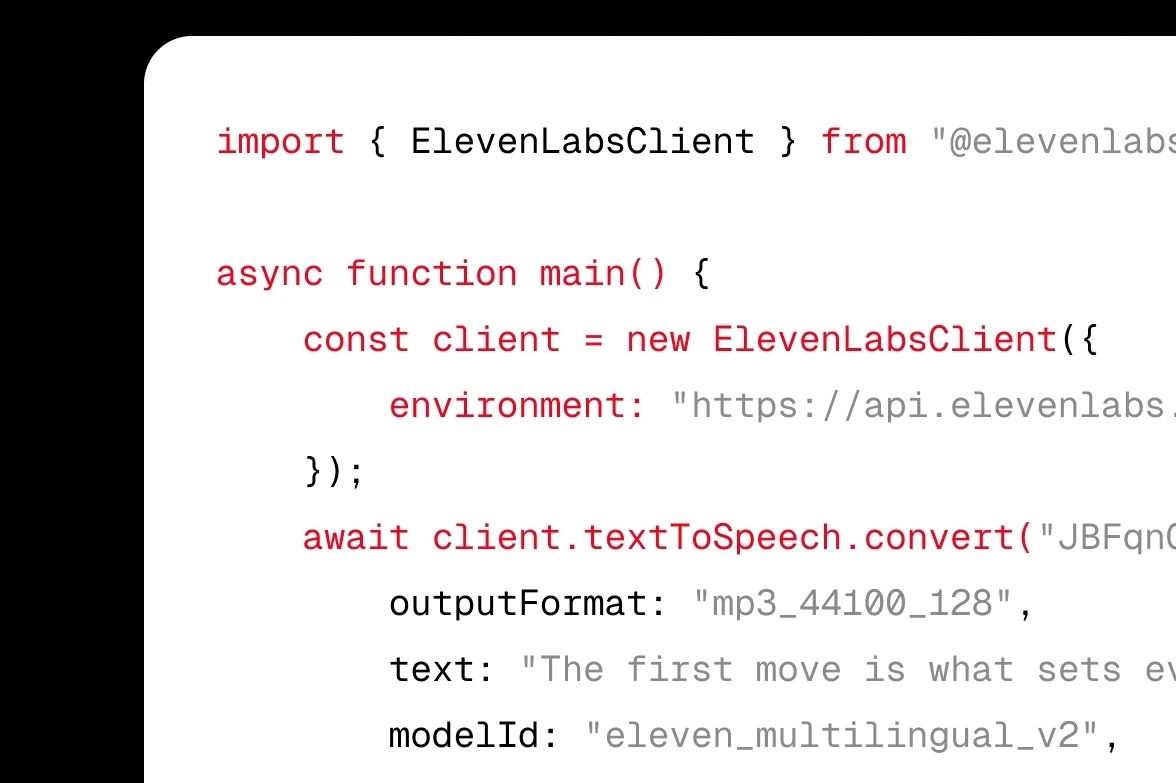
Integrate ElevenLabs Text to Speech (TTS) into your product via APIs or SDKs.
.png&w=3840&q=80)

.jpg&w=3840&q=80)

.jpg&w=3840&q=80)


.png&w=3840&q=80)
