नेरेशन
भावपूर्ण आवाज़ें जो ऑडियोबुक्स और पॉडकास्ट्स को जीवंत बनाती हैं
1 मिलियन+ यूज़र्स का भरोसा • शुरू करें मुफ़्त में
नेरेशन
भावपूर्ण आवाज़ें जो ऑडियोबुक्स और पॉडकास्ट्स को जीवंत बनाती हैं

कन्वर्सेशनल
अनौपचारिक परिस्थितियों के लिए प्राकृतिक आवाज़ें।
कैरेक्टर्स
कार्टून या वीडियो गेम्स के लिए मज़ेदार और आकर्षक आवाज़ें

सोशल मीडिया
शॉर्ट-फॉर्म कंटेंट के लिए ट्रेंडी, ध्यान आकर्षित करने वाली आवाज़ें

मनोरंजन
शो, ट्रेलर और प्रोमो के लिए प्रसारण-तैयार आवाज़ें

विज्ञापन
ऐसी असरदार आवाज़ें जो एक्शन और ब्रांड को याद रखने में मदद करें।
शैक्षिक
ट्यूटोरियल्स और ई-लर्निंग के लिए स्पष्ट, भरोसेमंद आवाज़ें।

वॉइस एक पल के लिए रुकी, [धीरे से] जैसे कि विचारों को इकट्ठा कर रही हो, फिर आगे बढ़ी। हर सांस जानबूझकर ली गई लग रही थी, हर हिचकिचाहट बिल्कुल सही समय पर थी।
यह अब सिंथेटिक स्पीच नहीं थी [गर्मजोशी से हंसते हुए] - यह एक वॉइस थी जो समय, भावना और शब्दों के बीच की जगह को समझती थी।
टेक्स्ट उपस्थिति में बदल गया। [संतोषपूर्वक आह भरते हुए] शब्दों को जीवन, व्यक्तित्व, आत्मा मिली।
इमोशन, ऑडियो इवेंट्स और इमर्सिव साउंडस्केप्स के साथ कंट्रोल करने योग्य, एक्सप्रेसिव स्पीच बनाएं।
हर जरूरत के लिए एक्सप्रेसिव, लाइफ-लाइक वॉइस की बढ़ती कलेक्शन एक्सप्लोर करें—नरेशन से लेकर कैरेक्टर क्रिएशन तक।
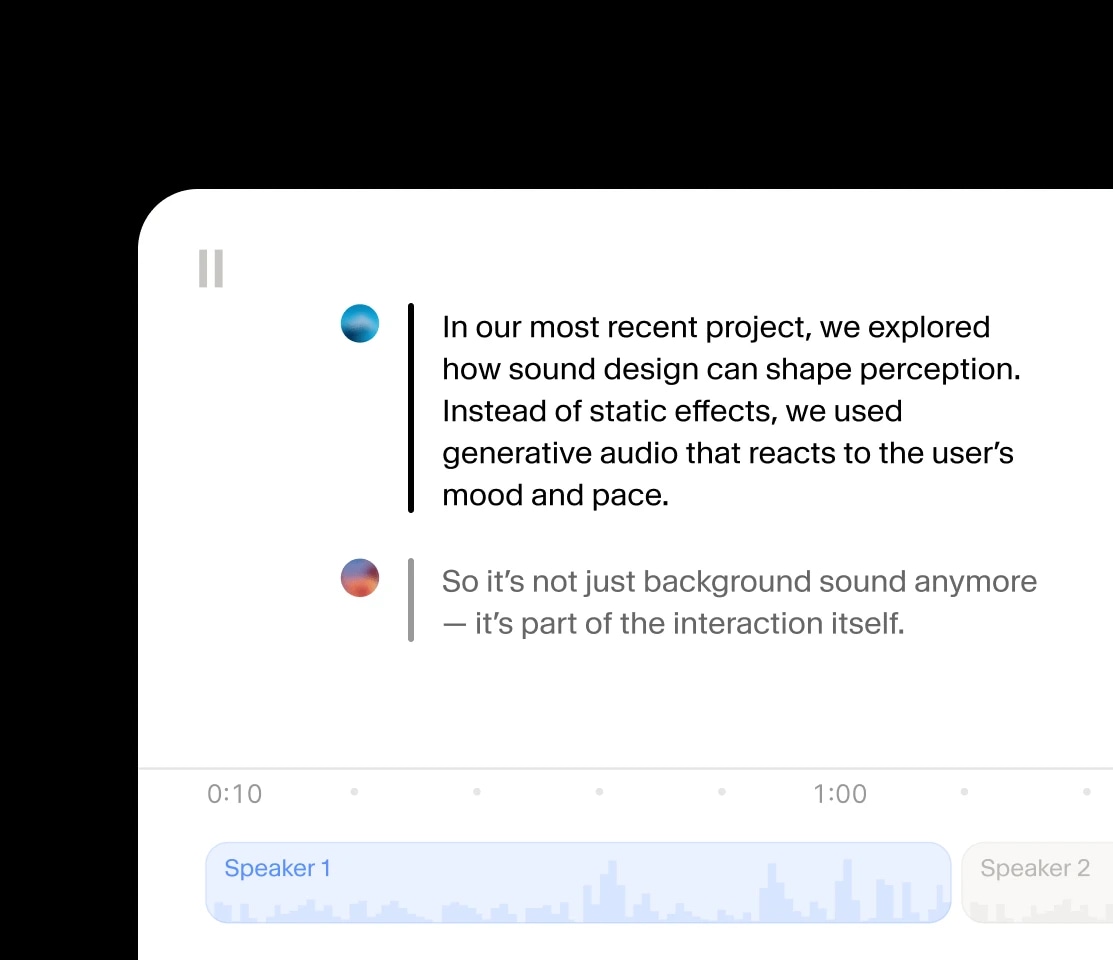
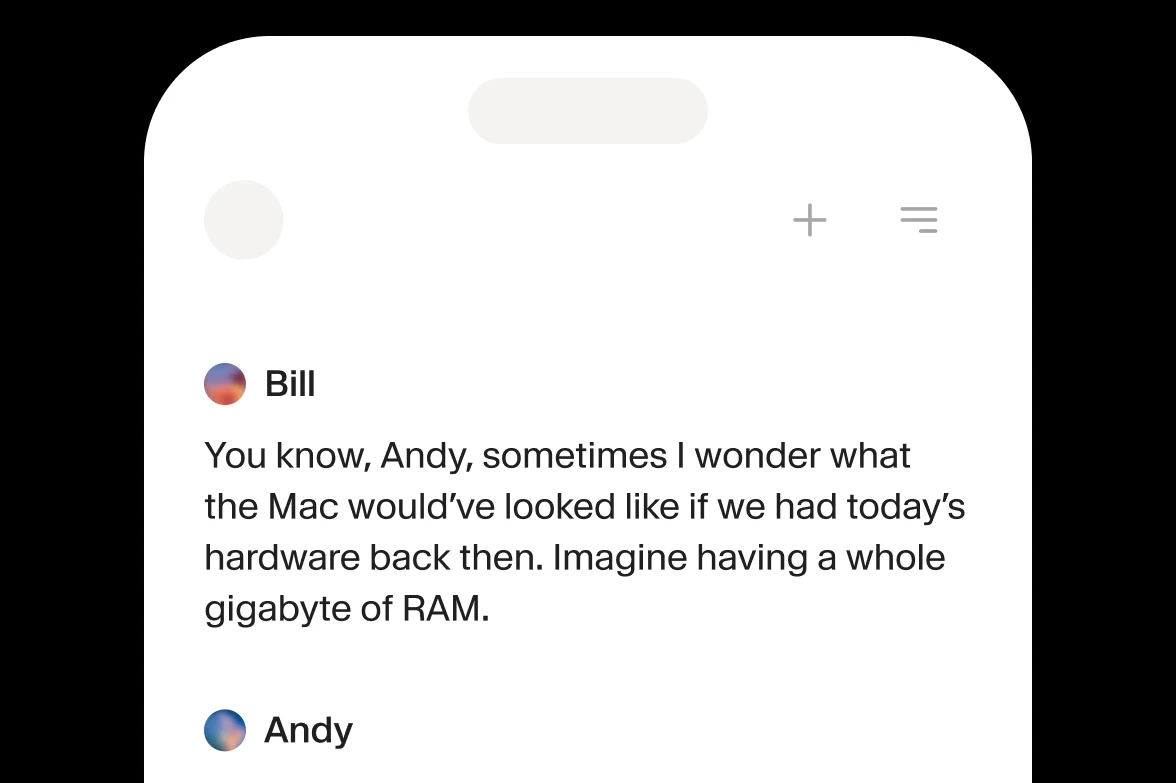
ऐसी ऑडियो बातचीत बनाएं जिसमें स्पीकर्स संदर्भ और भावना शेयर करते हैं।
अपनी खुद की वॉइस तुरंत क्लोन करें या पूरी तरह कंट्रोल के साथ यूनिक AI वॉइस बनाएं।
70 से ज्यादा भाषाओं में कहानियों को जीवंत बनाएं, वो भी नेटिव-लेवल इमोशन और क्लैरिटी के साथ।



हमारा सबसे एडवांस्ड, एक्सप्रेसिव मॉडल जिसमें इमोशनल कंट्रोल के लिए ऑडियो टैग्स हैं। स्टोरीटेलिंग, गेमिंग और मीडिया प्रोडक्शन के लिए बेस्ट—70+ भाषाओं में।

हमारा सबसे लाइफ-लाइक, इमोशन से भरपूर टेक्स्ट टू स्पीच मॉडल जो 29 भाषाओं को सपोर्ट करता है। वॉइसओवर, ऑडियोबुक्स, पोस्ट-प्रोडक्शन और कंटेंट क्रिएशन के लिए बेस्ट।

हमारा हाई क्वालिटी, लो लेटेंसी TTS मॉडल 32 भाषाओं में। डेवलपर्स के लिए बेस्ट, जहां स्पीड जरूरी है और नॉन-इंग्लिश भाषाएं चाहिए।

हाई क्वालिटी, लो-लेटेंसी मॉडल जिसमें क्वालिटी और स्पीड का अच्छा बैलेंस है

एक ही पावरफुल एडिटर में सबसे बेहतरीन AI ऑडियो मॉडल्स।

हमारे iOS और Android ऐप्स से कुछ सेकंड में एक्सप्रेसिव ऑडियो जनरेट करें।
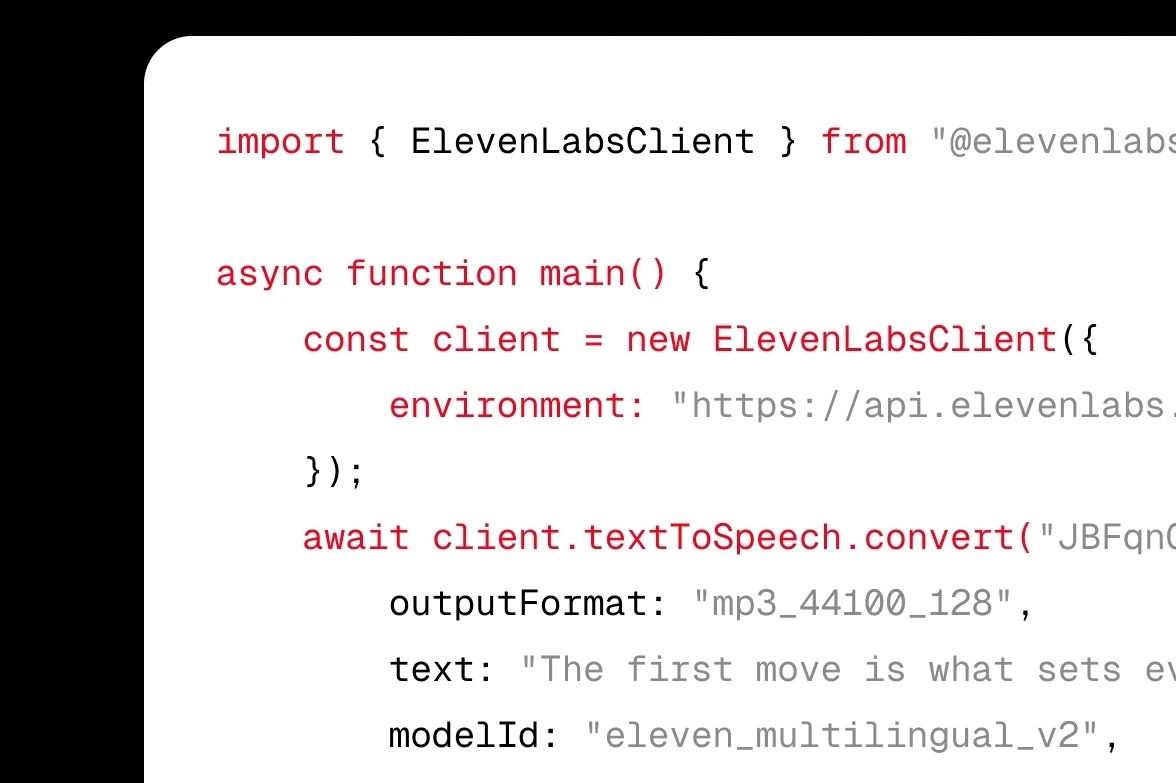
ElevenLabs टेक्स्ट टू स्पीच (TTS) को API या SDK के ज़रिए अपने प्रोडक्ट में इंटीग्रेट करें।
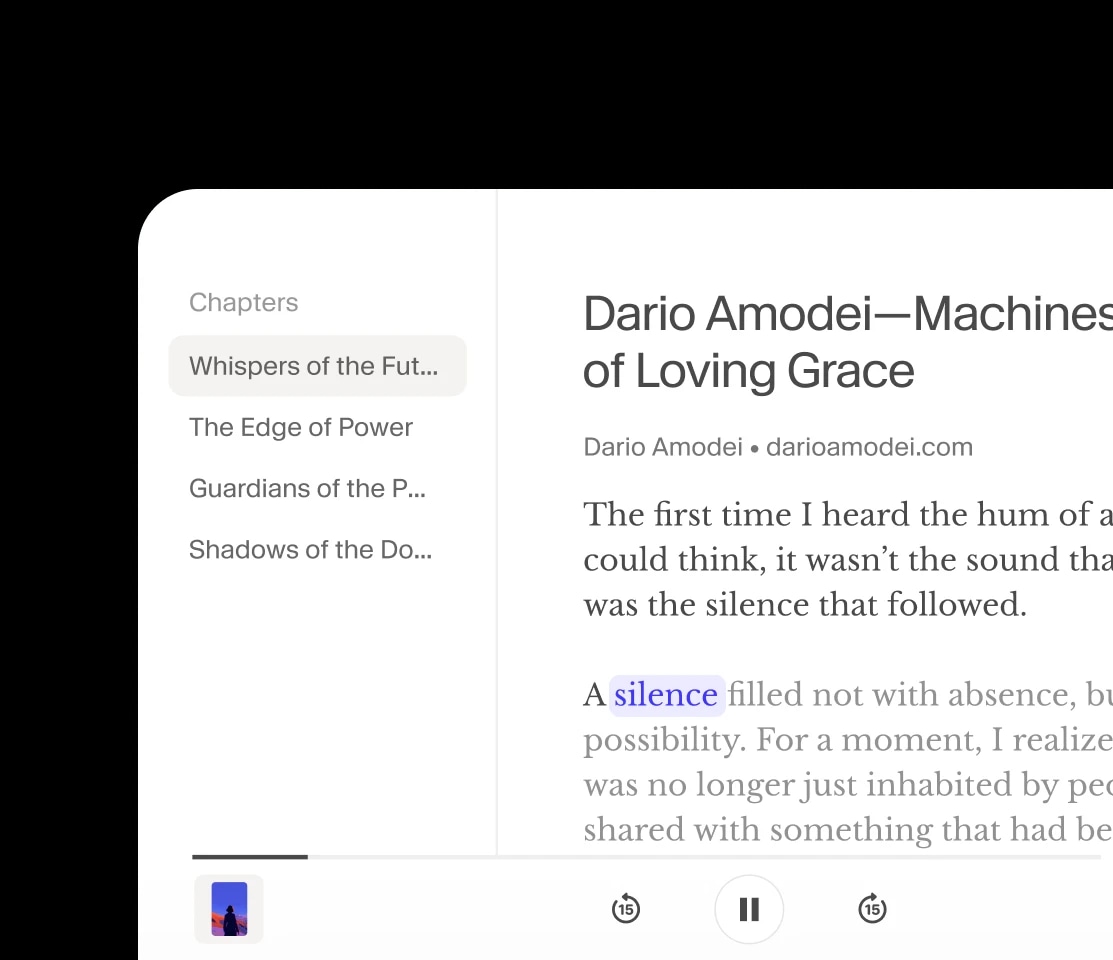
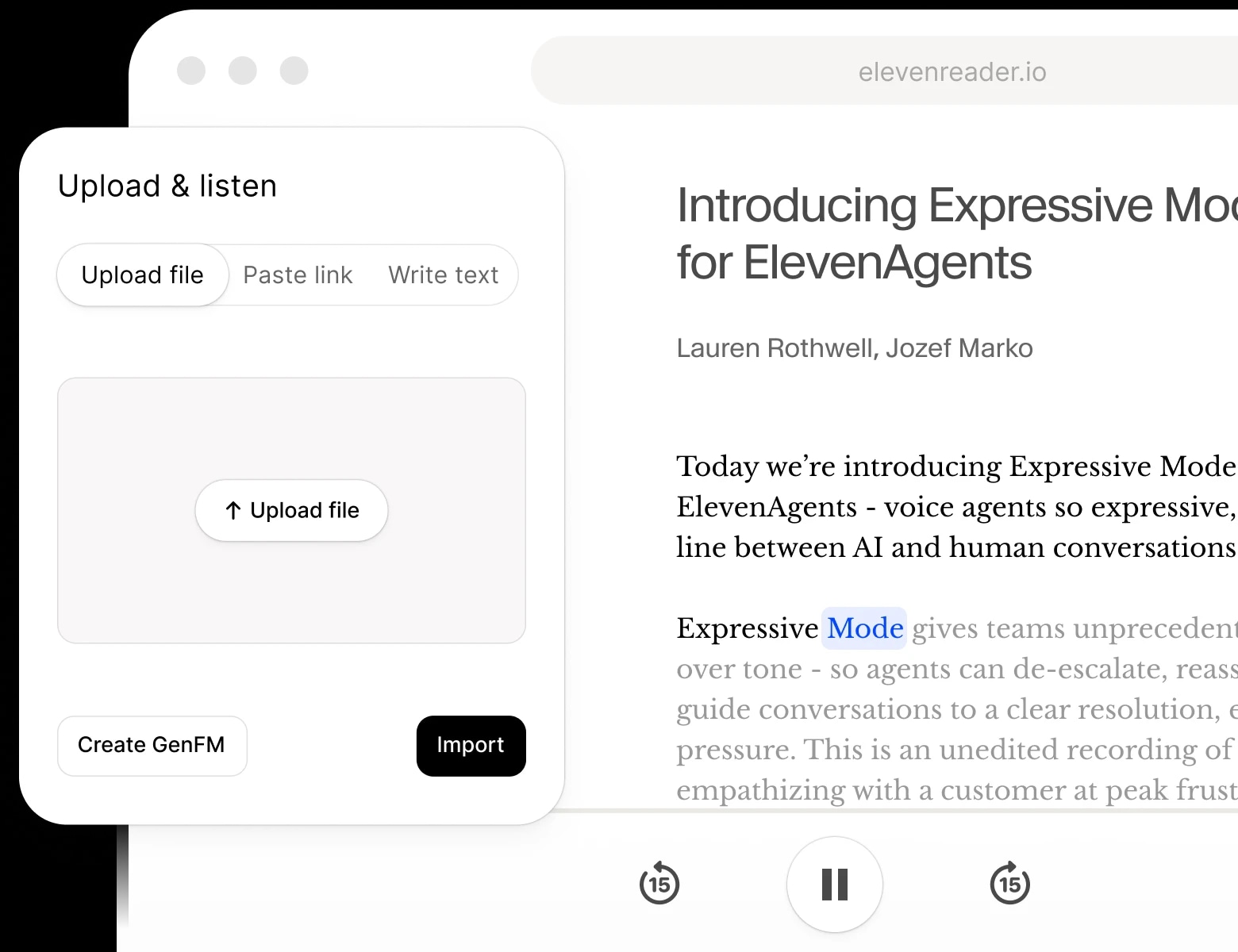
आर्टिकल्स, PDFs, ईबुक्स और वेबपेज को ElevenReader के ज़रिए शानदार नेचुरल AI वॉइस में सुनें—यह हमारा मुफ़्त रीड अलाउड ऐप है iOS, Android और Chrome के लिए। अपना खुद का कंटेंट अपलोड करें या हज़ारों बुक्स में से चुनें, अपनी पसंद की वॉइस चुनें, और सफर, पढ़ाई या रिलैक्स करते हुए सुनें।




.webp&w=3840&q=80)






























































































