Eleven v3 音频标签是什么,有什么用
- 发布时间
- 最近更新
随着 Eleven v3 发布,音频提示成为一项必备技能。现在不仅能输入或粘贴要让 AI 语音说的话,还能用全新功能——音频标签——来控制情感和表达方式。
Eleven v3 是一款 alpha 版本的 研究预览,基于全新模型。相比之前的模型,需要更多 提示词设计,但生成效果非常惊艳。
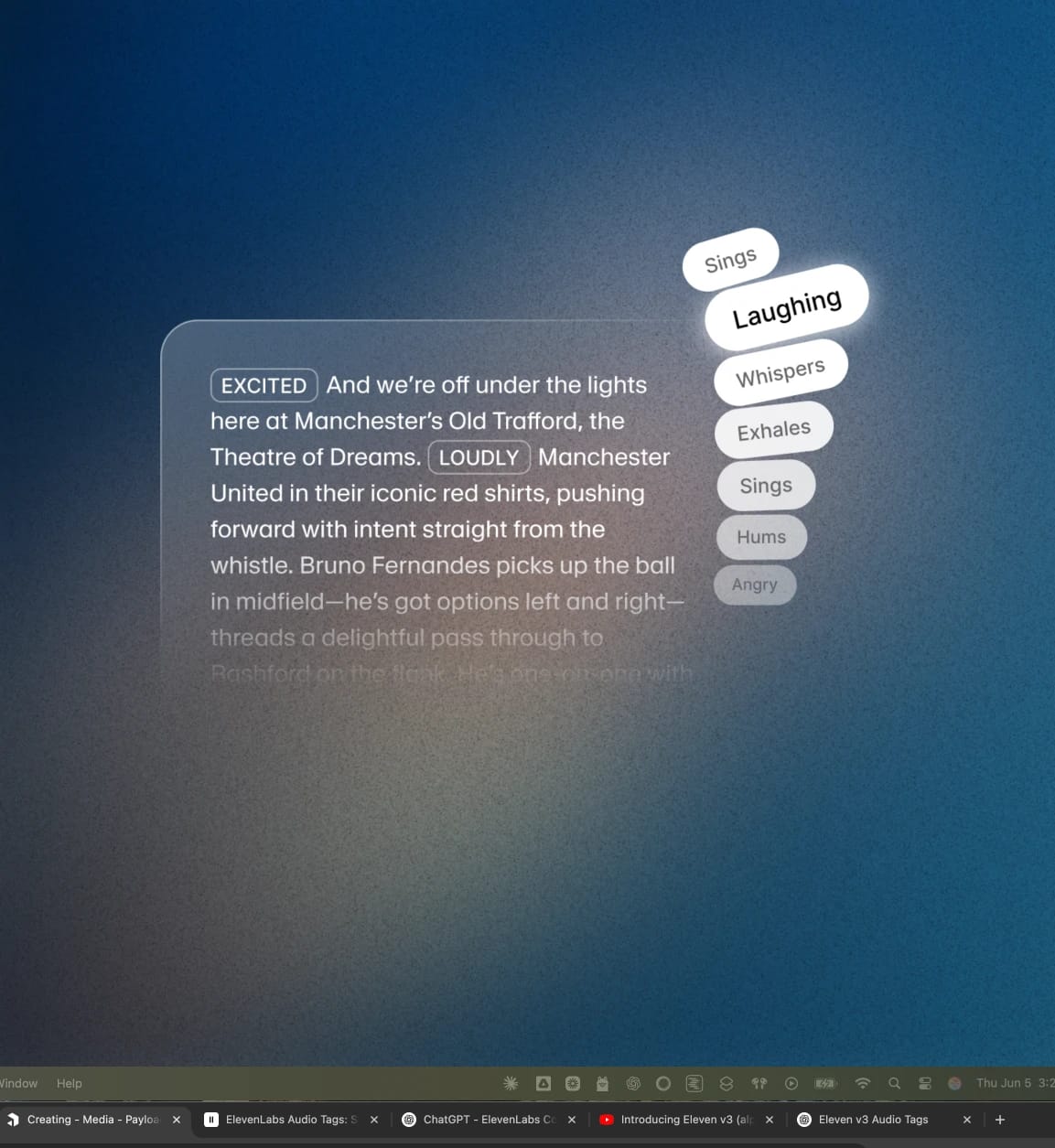
ElevenLabs 音频标签是用方括号包裹的词语,Eleven v3 新模型能识别并据此调整语音表现。例如 [excited]、[whispers]、[sighs],甚至 [gunshot]、[clapping]、[explosion] 等。
音频标签可自定义
用音频标签引导演绎
可在脚本任意位置插入音频标签,实时调整语音表现。标签可组合使用,甚至一句话内也能混用。标签主要分为几类:
情感
这些标签可设定语音的情感基调,比如低落、激烈或愉快。可以单独或组合使用 [sad]、[angry]、[happily]、[sorrowful] 等。


表达方式
这类标签主要调节语气和表现力。可用来调整音量和情绪强度,适合需要克制或强调的场景。例如:[whispers]、[shouts],甚至 [x accent]。


人类反应
自然语音包含各种反应。可用这些标签让语音更真实,加入自然、即兴的细节。例如:[laughs]、[clears throat]、[sighs]。


基于更具表现力的新模型
这些功能背后是 v3 的全新架构。模型能更深入理解文本语境,更自然地把握情感变化、语气转换和说话人切换。结合音频标签,带来比以往更丰富的表达能力,突破传统
现在还可以创建 多角色对话,让对话更自然,支持打断、情绪切换和细腻互动,只需简单提示即可实现。
现已上线
专业语音克隆(PVC)目前尚未完全适配 Eleven v3,克隆质量可能低于早期模型。在当前研究预览阶段,如需使用 v3 功能,建议选择即时
Eleven v3 已在 ElevenLabs UI 上线,现 6 月底前享受 8 折优惠。Eleven v3(alpha)公测 API 也已开放。无论是试用还是大规模部署,现在正是探索新可能的好时机。
音频标签用法

要让 AI 语音真正“演绎”而非只“朗读”,关键在于掌握音频标签。我们准备了 7 份简明实用指南,演示如何用 标签,如 【低语】, 【轻声笑】,或 【法国口音】,灵活控制语境、情感、语速,甚至多角色对话。
查看系列教程
- 情境感知 – 通过标签如
【低语】,【喊叫】,以及【叹气】,Eleven v3 可根据场景调整表现,强化氛围、缓和警告或制造悬念。 - 角色演绎 – 从
【海盗语气】到【法国口音】,标签让旁白变成角色扮演。可随时切换角色,无需更换模型。 - 情感表达 – 用标签如
【叹气】,【兴奋】,或【疲惫】,实时调节情绪,叠加紧张、轻松或幽默,无需重新录制。 - 叙事节奏 – 讲故事讲究节奏。用标签如
【停顿】,【敬畏】,或【戏剧性语气】控制语速和重音, - 多角色对话 – 用
【打断】,【重叠】或语气切换,写出重叠台词和快速对话。一个模型,多种声音,一次完成自然对话。 - 表达控制 – 精细调节语速和重音。用标签如
【停顿】,【急促】,或【拉长】,精准把控节奏,让文本变成表演。 - 口音模拟 – 随时切换地区口音——
【美式口音】,【英式口音】,【美国南方口音】等,无需更换模型即可实现多元文化表达。