リアルタイム吹き替えへの道
- 公開日
- 最終更新日
聴くこの記事を聴く
リアルタイムダビングは、一部の人にとって『銀河ヒッチハイク・ガイド』のバベルフィッシュを思い起こさせます。
脳波を読み取れるようになるまでは、話し手の言葉を聞いて、目的の言語に翻訳する必要があります。話し手が口にした単語をそのまま逐一翻訳しようとすると、さまざまな課題が生じます。
例えば、英語からスペイン語に翻訳したい場面を想像してください。話し手が「The」と言い始めたとします。スペイン語では「The」は男性名詞なら「El」、女性名詞なら「La」になります。つまり、続きが分かるまで「The」を確実に翻訳することはできません。
英語からスペイン語に翻訳したい状況を想像してください。話者が「The」で始めます。スペイン語では「The」は男性名詞には「El」、女性名詞には「La」と翻訳されます。したがって、もっと聞くまで「The」を確実に翻訳することはできません。

話者が「The running water」と続けたと想像してください。これで最初の3語を「El agua corriente」と翻訳するのに十分な情報があります。文が「The running water is too cold for swimming」と続くと仮定すると、順調です。
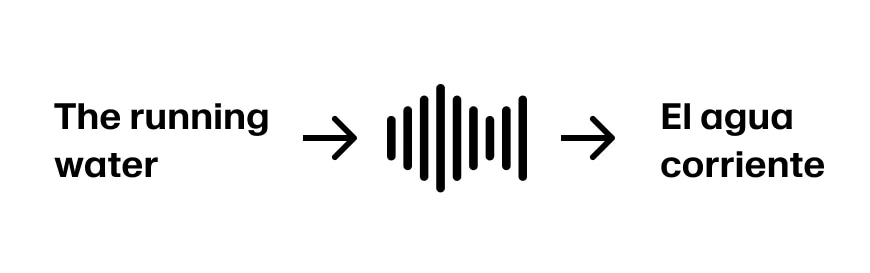
しかし、話者が「The running water buffalo…」と続けた場合、戻って修正する必要があります。
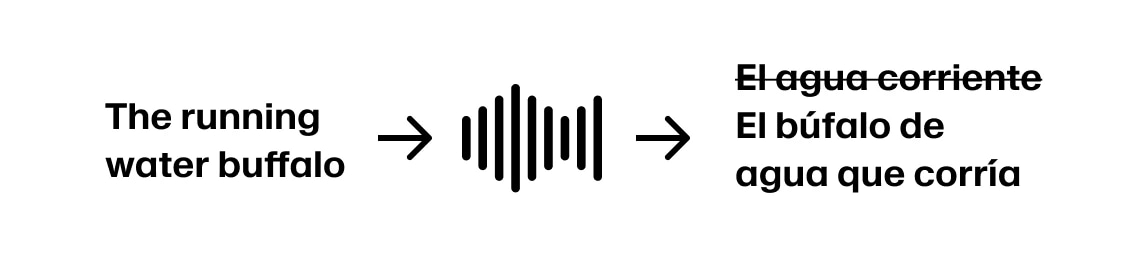
こうした「
用途によっては、吹き替えを早く始めすぎて後から訳を戻す必要があることを受け入れる場合もあります。より正確さを求めるなら、遅延を追加することも選べます。ある程度の遅延はすべての吹き替えのユースケースに不可避なので、「リアルタイム」吹き替えは、音声を継続的にストリーミングし、翻訳されたコンテンツを返すサービスと定義しています。
一部のユースケースでは、ダビングを急ぎすぎて後で修正が必要になることを受け入れるかもしれません。他のケースでは、より正確さを求めて遅延を追加することを選ぶことができます。すべてのダビングユースケースにはある程度の遅延が伴うため、「リアルタイム」ダビングを、音声を連続的にストリーミングし、翻訳されたコンテンツを返すサービスとして定義します。

リアルタイム吹き替えが最も効果的な商用用途は、次のような場合です。
リアルタイムダビングの最適な商業用途は、次のような場合です。
- グローバルな視聴者がいる
- ライブコンテンツである
- 放送に多少の 遅延が許容される
スポーツ
フォーブスは2019年に報告しましたNBAが国際テレビ権で5億ドルを稼いでいると。NFLは今、ブラジル、イギリス、ドイツ、メキシコで試合を開催しており、国際的な拡大を将来の主要な収益源と見なしています。
通常、現場には複数のカメラや音声オペレーターがいて、映像を制作施設にストリーミングします。制作施設ではカメラ映像を切り替え、音声をミックスし、グラフィックを重ね、解説を追加します。また、不適切な発言や予期せぬ内容を検知して消音するため、意図的に追加の遅延を設けることもあります。
メインの制作フィードは放送ネットワークに送られ、そこで独自のブランディングやCMが追加され、各地域のネットワークに配信されます。最終的に、ケーブル、衛星放送、ストリーミングサービスを通じて消費者に届けられます。
メインの制作フィードは放送ネットワークに送られ、彼らは自社のブランドやコマーシャルを追加し、コンテンツをローカルネットワークに配信します。最後に、ラストマイルプロバイダーがケーブル、衛星フィード、ストリーミングサービスを通じて消費者にコンテンツを共有します。

スポーツ企業が最も重視するのは、質の高いプロダクトを提供することです。そのためには、実況者の感情やタイミングを的確に捉えることが重要だと考えています。「シュート!ゴール!」のような場面は、熱意を持って伝える必要があります。
ElevenLabsのボイスクローンモデルは、吹き替えサービスの基盤として、元の話者の感情や話し方を再現できます。翻訳とは異なり、文脈が多ければ多いほど良い結果になるとは限りません。ただし、スペインのサッカー実況者のような感情表現には、まだ到達していません!
各ボイスクローンは、入力された音声の平均的な特徴を持ちます。例えば、「残り2分しかないので、もっと積極的にいく必要がある」という淡々としたセリフと、「シュート!ゴール!」のような熱いセリフを組み合わせると、平均的なトーンのクローンが生成されます。
各ボイスクローンは、その入力の平均です。「残り2分でより積極的になる必要がある」と平坦に伝えられるラインと「彼がシュートし、彼が得点!」を組み合わせると、結果として得られるクローンはその2つの平均的な伝達になります。

ニュース放送
「ライブ」スポーツと同様に、ニュース放送も制作工程で遅延が発生します。メディア企業との会話から、感情表現も重要ですが、多くのニュースキャスターは話し方が一貫しているため、再現は比較的容易です。それよりも、翻訳の正確さと微妙なニュアンスが何よりも重要です。
自動翻訳サービスが失敗する可能性があるだけでなく、言語によっては直接的な翻訳ができない概念もあります。例えば、次のような文を考えてみてください。
「The community gathered for a day of remembrance, where survivors shared their stories and elders performed traditional prayers for healing.」
スペイン語:「La comunidad se reunió para un día conmemorativo, donde los sobrevivientes compartieron sus historias y los ancianos realizaron oraciones tradicionales para la sanación.」
技術的には正確でも、「survivors」と「sobrevivientes」では歴史的トラウマの文脈で重みが異なります。英語では「survivors」はしばしば強さや尊厳を意味しますが、「sobrevivientes」は被害者性を強調することがあります。同様に、「performed prayers」と「realizaron oraciones」も敬意の度合いが異なり、「performed」は儀式的な意味合いを持ちますが、「realizaron」は手続き的に聞こえることがあります。
ボーナス - 会話型吹き替えへの道
同じ言語を話さない人同士が自然に対面で会話できるようにするには、ほぼ瞬時の翻訳が必要です。
LLMの次トークン予測確率を使うことで、文がどこに向かうかをリアルタイムで予測できます。
LLMの次のトークン予測確率を使用することで、文がどこに向かっているかのリアルタイムモデルを持つことができます。

画像ソース - Hugging Face「テキスト生成方法」
この内容に興味があり、AIオーディオの未来を一緒に作りたい方は、
これに興味があり、AIオーディオの未来について一緒に働きたいですか?こちらでオープンロールを探す。




