我们如何让 RAG 提速 50%
- 发布时间
- 最近更新
RAG 通过将 LLM 的回答与大型知识库结合,提高 AI 智能体的准确性。RAG 不会把整个知识库传给 LLM,而是先对查询进行嵌入,检索最相关的信息,再作为上下文传递给模型。在我们的系统中,首先会进行查询重写,把对话历史压缩成一个精准、独立的查询,再进行检索。
对于很小的知识库,可以直接把所有内容放进提示词。但知识库一旦变大,RAG 就变得不可或缺,既能保证回答准确,又不会让模型负担过重。
很多系统把 RAG 当作外部工具使用,而我们直接把它集成进请求流程,每次查询都会运行。这保证了准确性,但也带来了延迟风险。
查询重写为何拖慢了速度
大多数用户请求都会引用之前的对话,所以系统需要把对话历史压缩成一个精准、独立的查询。
例如:
- 如果用户问:“可以根据我们的高峰流量模式自定义这些限制吗?”
- 系统会重写为:“Enterprise 方案的 API 速率限制可以针对特定流量模式自定义吗?”
重写会把“这些限制”这样的模糊表达变成检索系统能用的独立查询,提升上下文和最终回答的准确性。但如果只依赖单一外部 LLM,就会受限于它的速度和可用性。这个步骤占了 RAG 延迟的 80% 以上。
我们用模型竞速解决了这个问题
我们把查询重写设计成竞速模式:
- 多模型并行。每个查询会同时发送给多个模型,包括我们自有的 Qwen 3-4B 和 3-30B-A3B,最先返回有效结果的模型获胜。
- 保障对话流畅的兜底方案。如果 1 秒内没有模型响应,就直接用用户原始消息。虽然可能不够精准,但能避免卡顿,保证对话不中断。
.webp&w=3840&q=95)
性能提升效果
新架构让 RAG 的中位延迟从 326 毫秒降到 155 毫秒。和很多只在部分请求用 RAG 的系统不同,我们每次查询都运行 RAG。中位延迟降到 155 毫秒后,这样做的额外开销几乎可以忽略。
优化前后延迟对比:
- 中位数:326ms → 155ms
- p75:436ms → 250ms
- p95:629ms → 426ms
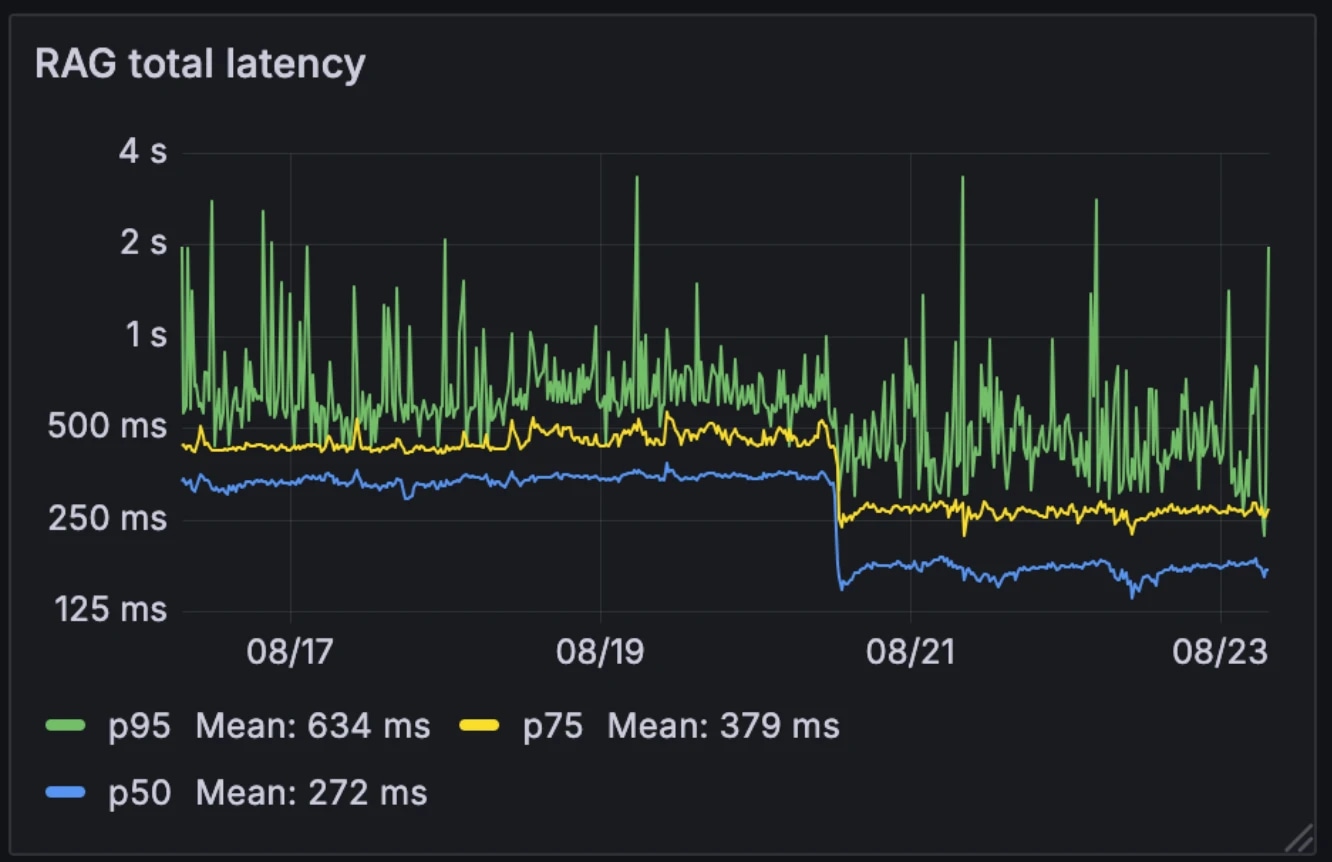
新架构还提升了系统对模型波动的抗性。外部模型在高峰时段可能变慢,而我们的自有模型表现更稳定。模型竞速能平滑这些波动,让系统整体表现更可控。
比如,上个月某 LLM 服务商宕机时,对话还能无缝切换到我们的自有模型。由于这些基础设施本来就为其他服务运行,新增算力成本几乎可以忽略。
意义何在
RAG 查询重写低于 200 毫秒,消除了对话式智能体的主要瓶颈。即使面对大型企业知识库,系统也能实时响应并保持上下文。检索开销降到几乎可以忽略,智能体可以大规模扩展而不影响性能。



.webp&w=3840&q=80)
