Ramverk för utvärdering av voice agents: 6 pelare förklarade
- Skriven av
- Jack Limebear
- Publicerad
- Senast uppdaterad
Röstagenter behöver samordna flera verktyg nästan samtidigt. Det handlar om att spela in kundens kommentarer i realtid med
Med så många delar i rörelse, hur utvärderar du egentligen en voice agents prestanda?
I den här artikeln föreslår vi ett ramverk med sex pelare för utvärdering av voice agents, där vi går igenom vad du faktiskt ska mäta för att bedöma agentens framgång. Vi tar också upp varför olika branscher bör väga dessa pelare olika och vanliga misstag att undvika vid utvärdering.
Sammanfattning
- De sex viktigaste pelarna för utvärdering av voice agents är TTS-röstkvalitet, samtalskvalitet, verktygsanvändning och uppgiftslösning, intelligens, efterlevnad och säkerhet samt tillförlitlighet.
- De viktigaste produktionsmålen att sikta på är en MOS på 4,3, en TSR över 85 % och en time-to-first audio under 500 ms.
- Olika branscher kommer att väga varje pelare olika, där vissa användningsområden prioriterar en pelare framför de andra.
- Vanliga testmisstag är att bara utvärdera rent ljud och att ignorera P99-latensspikar.
- ElevenLabs leder på de viktigaste mätvärdena: Scribe v2 har lägst WER i branschen på 2,2 % (Artificial Analysis, juni 2026), Flash v2.5 och Turbo v2.5 är snabbast (Artificial Analysis, juni 2026) och ElevenAgents levererar ~75 ms modell-latens.
Vad är ett ramverk för utvärdering av voice agents?
Ett ramverk för utvärdering av AI voice agents är ett strukturerat system som låter dig testa prestanda inom flera områden. Ett heltäckande ramverk innehåller mätvärden för allt från ljudkvalitet till samtalsflöde och även regelefterlevnad.
Till skillnad från en textbaserad chatbot går varje interaktion med en voice agent genom minst tre tekniker: automatisk taligenkänning (ASR) som omvandlar användarens ord till text, en LLM som skapar ett svar och ett TTS-system som gör om svaret till ljud. Om någon av dessa delar fallerar påverkas hela upplevelsen.
Den här komplexiteten är just varför företag behöver utvärdera voice agents innan de väljer leverantör och sätter igång. Extra latens eller otydliga svar kan få verkliga konsekvenser, som tappade kunder eller i värsta fall böter och skadat rykte.
Ett ramverk för utvärdering av voice agents använder benchmarking och mätbar data för att avgöra om en agent passar för vissa användningsområden. För företag innebär det att kunna jämföra olika voice-modeller och välja den bästa för dina kunder.
De sex pelarna du bör utvärdera hos voice agents
Även om det aldrig varit enklare att skapa och lansera en AI-agent är processerna bakom kulisserna ganska komplexa. Flera komponenter samarbetar för att lyssna på användaren, förstå vad de vill, skicka informationen till en LLM och sedan skapa ett ljudsvar – allt sker nästan samtidigt.
För att hitta den bästa voice agenten behöver företag ett tydligt ramverk att jämföra mot.
Om du är mer intresserad av att se testresultat så erbjuder Artificiell analys flera jämförelser av agenter baserat på olika komponenter. Nedan ser du resultatet av deras modell-till-modell-hastighetstest, där ElevenLabs Turbo v2.5 och Flash v2.5 leder stort i antal bearbetade tecken per sekund.
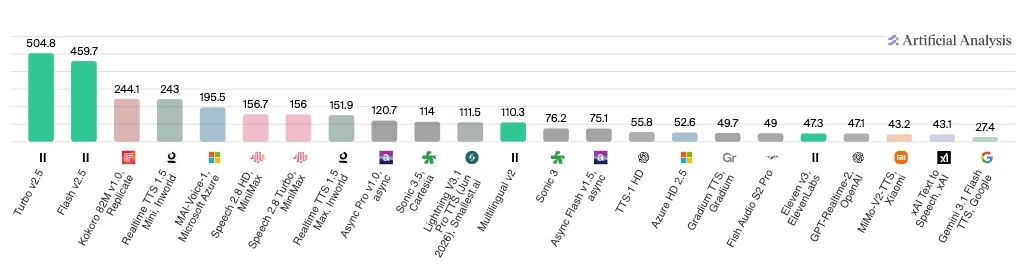
För utvecklare eller företag som vill göra egna tester, här är de sex pelarna i ett ramverk för utvärdering av AI-agenter du bör använda:
- TTS-röstkvalitet: Hur naturligt, tydligt och uttrycksfullt det syntetiska talet låter för slutanvändaren. Toppmodeller som Eleven v3 erbjuder mänsklig och känslosam leverans på över 70 språk.
- Samtalskvalitet: Förstår modellen mänskligt tal, tolkar betydelsen och svarar snabbt i rätt kontext över flera turer?
- Verktygsanvändning: Hur väl AI-agenten slutför uppgifter med tillgängliga resurser utan att behöva mänsklig hjälp.
- Intelligens: Hur bra modellen resonerar, hanterar nya indata och undviker felaktiga eller påhittade svar.
- Efterlevnad och säkerhet: Utöver alla funktioner måste
- Tillförlitlighet: Faktorer som total tillgänglighet och jämn prestanda under belastning avgör om en conversational AI-agent kan skala efter behov.
Även om varje pelare är självständig hänger de ihop för att ge användaren en bra helhetsupplevelse. Om en modell till exempel förbättrar röstkvaliteten men fortfarande har hög latens, får kunden ändå vänta onaturligt länge på svar.
Låt oss titta närmare på varje pelare för utvärdering av voice AI.
TTS-röstkvalitet
Vi börjar med röstkvalitet, eftersom det ofta är det första en människa märker när de pratar med en AI-agent. Om rösten låter robotlik eller konstig blir upplevelsen sämre.
Ett av de ursprungliga mätvärdena, enligt International Telecommunication Union Telecommunication Standard Sector (ITU-T), är Mean Opinion Score (MOS). MOS mäts på en skala från 1 till 5, där 1 är oanvändbart och 5 är utmärkt. Det är en subjektiv bedömning där människor lyssnar och ger feedback efter ett samtal.
Allt under MOS 3,5 på denna skala är ganska svagt, särskilt med dagens standard, och påverkar troligen kundnöjdheten.
Även om MOS är ett mänskligt mätvärde finns det flera tekniska krav som påverkar resultatet:
- Tonal stabilitet och jitter: Ton och jitter är två språkliga element som människor automatiskt uppfattar. “Ton” handlar om hur intonationen ändras, till exempel när du höjer rösten vid en fråga. Jitter är när modellens förståelse av ton varierar, vilket gör att den inte kan hålla en jämn prosodi genom meningen. Branschstandarden för jitter är 30 ms.
- Känslomässigt uttryck: En röst som är tydlig och exakt låter ändå fel om tonen inte matchar meningen. Utan rätt tonfall får användaren svårare att känna förtroende för AI-agenten och rankar den lägre. ElevenAgents erbjuder nästan mänskligt uttryck för att matcha varje svar med rätt känsla.
- Bakgrundsljud: Bakgrundsljud i voice agents har två sidor att utvärdera. På ut-sidan läggs diskret bakgrundsljud till för att göra agenten mer naturlig. På in-sidan kan bakgrundsljudsfilter i STT-lagret aktiveras för bättre noggrannhet. När du utvärderar en agent, testa båda: lyssna på om bakgrundsljudet låter naturligt och kontrollera STT-noggrannheten med filtret på och av.
När du räknar ut MOS bör du sikta på 4,3–4,5, vilket visar höga poäng i alla dessa kategorier. För MOS-prediktion i stor skala utan mänskliga paneler kan du använda verktyg som UTMOS och NISQA.
Samtalskvalitet
Samtalskvalitet är en sammansatt pelare mellan röstkvalitet och uppgiftslösning. Den mäter hur effektivt en voice agent förstår användarens behov, kan avbryta i rätt kontext och hålla ihop en dialog över flera turer.
Det viktigaste mätvärdet här är noggrannhet i intent-klassificering, där typiska resultat ligger mellan 85 % och 92 %, och de bästa når över 96 %. Även om 85 % låter högt betyder det ändå att 15 % av all trafik hamnar fel.
Tekniska faktorer som bidrar till hög noggrannhet i intent-klassificering är:
- Turordning: Turordning avgör hur bra en voice agent hanterar det naturliga samtalsflödet. Det handlar om att veta när den ska lyssna, svara eller vänta på mer input. Det gäller också att hantera avbrott, där modellen avbryter ett pågående svar och skapar ett nytt utifrån ny input. ElevenLabs använder en multi-context websocket för att smidigt hantera dessa avbrott.
- Latens: Latens beskriver fördröjningen från att användaren pratat klart till att agenten börjar sitt ljudsvar. Voice agents för produktion bör sikta på time-to-first audio under 500 ms, där under 300 ms är ännu bättre. ElevenLabs Flash-modeller erbjuder branschledande inferenstid på ~75 ms, vilket ger dig ett försprång här.
- Fallback-frekvens: Fallback-frekvens mäter hur ofta en AI-agent inte förstår användaren och ber om förtydligande eller upprepning. Det beror ofta på STT-noggrannheten – om taligenkänningen hör fel får LLM fel input. Fallback-frekvens räknas så här: Fallback rate (%) = (Antal fallbacks / Totalt antal interaktioner) * 100.
ElevenLabs Scribe V2 har lägst WER på 2,2 % i Artificial Analysis speech to text-utvärdering
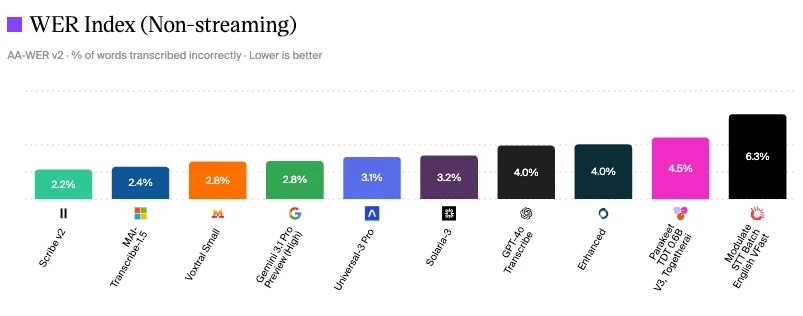
Artificial Analysis speech to text-modellutvärdering
Ett sätt att mäta samtalskvalitet är att titta på branschstandarder för olika komponenter. Som du ser har ElevenLabs Scribe v2 lägst Word Error Rate på 2,2 % i juni 2026, vilket betyder färre felläsningar, färre fallbacks och mer träffsäker intent-klassificering.
Företag kan märka att samtalskvalitet också beror på vilket workflow agenten används i. I kundtjänst kan till exempel kvaliteten på överlämning eller FAQ-lösning vara viktig.
Verktygsanvändning och uppgiftslösning
Medan kvalitet mäter hur samtalet kändes, mäter uppgiftslösning om det faktiskt ledde till ett lyckat resultat. Företag bör lägga extra vikt vid denna del av ramverket, eftersom det är direkt kopplat till affärsresultat.
Ett mått på verktygsanvändning är slot-fill-noggrannhet, som visar hur bra AI-agenter klarar rutinuppgifter, som att fylla i ett formulär med kunduppgifter. Hög slot-fill-noggrannhet visar att agenten kan gå från samtal till handling utan att tappa information.
Task Success Rate (TSR) är ett procentmått på hur många uppgifter agenten slutfört från början till slut. Här räknas det som klart när agenten både förstår en begäran och använder rätt verktyg (API:er, databaser, Retrieval-Augmented Generation (RAG) och interna kunskapsbaser) för att hjälpa till.
Formeln för TSR är:
TSR = (Fullt slutförda uppgifter / Totalt antal försökta uppgifter) x 100
Voice agents redo för produktion bör sikta på en TSR över 85 %, och samtidigt övervaka noggrannhet och tillförlitlighet i verktygsanrop. För att undvika tapp i TSR, regressionstesta alltid vid ändringar i prompt eller modell. Även små avvikelser kan få stor effekt på TSR.
Intelligens
Intelligens handlar om agentens förmåga att resonera och lösa mer avancerade uppgifter. Det är här skillnaden mellan en röststyrd IVR och en voice AI-agent blir tydlig.
Viktiga områden att utvärdera här är:
- Hallucinationsrisk: Hallucinationer, där agenten ger felaktig eller inkonsekvent information jämfört med företagets dokument, är särskilt problematiskt i voice AI eftersom det kan låta övertygande.Nya studier visar att vanliga hallucinationer kraftigt försämrar kundnöjdheten med voice agents.
- Hantering av frågor utanför området: Intelligenta agenter förstår när en fråga ligger utanför deras område och kan svara på rätt sätt. Istället för att hitta på ett svar tackar de nej eller styr samtalet tillbaka till rätt område.
- Kontextminne: Kan agenten hålla koll på vad som sagts och lovats över flera turer? Utan denna förmåga kan kunder behöva upprepa sig eller få motsägelsefulla svar.
- Resonemang och flerstegsförmåga: Kan agenten hantera villkor och dra slutsatser över flera turer? Särskilt i tekniska användningsområden, som finansiella tjänster, är förmågan att resonera inom en given kontext avgörande.
Det finns flera tredjeparts-benchmark för dessa områden. Till exempel utvärderar Stanfords Holistic Evaluation of Language Models (HELM) LLM-prestanda i olika kategorier. För hallucinationer ger TruthfulQA en bra analys av hur ofta felaktiga svar dyker upp.
En fördel med ElevenAgents är att du, till skillnad från vissa voice-plattformar som låser dig till en modell, kan byta ut LLM-lagret helt. Det betyder att du kan använda den modell som är bäst på resonemang för just ditt användningsområde.
Efterlevnad och säkerhet
Företag behöver aktiva skydd för att förhindra skadliga eller policybrytande svar. Till skillnad från systeminstruktioner, som kan kringgås, körs oberoende skydd som ett separat lager utanför modellen. Dessa granskar svaren innan de når användaren och stoppar samtalet om det går åt fel håll.
Spårbarhet är också viktigt – produktionsagenter behöver detaljerade loggar över beslut och svar i ett format som går att granska i efterhand. Särskilt i reglerade branscher är det lika viktigt att kunna visa efterlevnad i efterhand som att uppnå den från början.
Exakt vilka regler ditt företag måste följa varierar mellan branscher. Några av de vanligaste ramverken är:
- HIPAA: För skyddade hälsodata i amerikansk sjukvård.
- PCI-DSS: För agenter som hanterar betalningskortdata.
- GDPR: Dataskyddskrav för EU och företag med kunder i EU.
För företag som utvärderar sin efterlevnad har ElevenLabs AICPA SOC Type II och GDPR-efterlevnad, samt AIUC-1-certifiering. AIUC-1 är en säkerhetsstandard särskilt för AI-agenter.
Tillförlitlighet
Tillförlitlighet är den sista pelaren i vårt ramverk och handlar om agenten kan leverera konsekvent i realtid.
När du utvärderar en voice agent, titta på dessa egenskaper:
- Tillgänglighet: Alla kundnära lösningar förväntas ha 99,9 % tillgänglighet för att undvika driftstopp. Särskilt för alltid-på-tjänster, som inkommande support, är tillförlitlig tillgänglighet avgörande.
- Smidig nedtrappning: På grund av den underliggande komplexiteten bör agenten hantera fel i en komponent på ett smidigt sätt. Det innebär i praktiken att styra över till en människa, istället för att fortsätta med ökande fel eller belastning.
- Prestanda under belastning: Belastningstest bör simulera minst dubbla din förväntade toppbelastning innan du går live. Test under hög belastning kan avslöja latensproblem eller försämrad prestanda som bara syns i stor skala.
Även en högkvalitativ modell kan bli oanvändbar om den inte skalar med din kundbas. ElevenAgents används av 1 000 000 ledande kreatörer och företag, vilket visar att plattformen klarar storskalig drift utan att tumma på prestanda.
Så mäter du MOS för voice agents (steg för steg)
Om du vill mäta MOS manuellt behöver du en stor grupp lyssnare och ett urval ljudklipp från riktiga samtal. Det är en strukturerad process där du samlar in feedback, räknar ut snitt och tolkar resultatet.
Så här mäter du MOS för voice agents i praktiken:
- Förbered testmaterialet: Välj ett representativt urval av ljudklipp från din agent, minst 100 klipp från olika samtal.
- Genomför betygssättningen: Be dina lyssnare betygsätta varje klipp på en skala 1–5 utifrån kommunikationskvalitet.
- Sammanställ och räkna ut poäng: Räkna ut snittbetyg för varje klipp och sedan för hela urvalet för att få ett övergripande MOS. Ett MOS på 4,3 eller högre visar att din voice agent är redo för produktion.
Även om processen är arbetsintensiv ger den dig ett stabilt MOS för din valda agent. Om du vill testa i större skala kan du ersätta lyssnarna med automatiska verktyg som NISQA, som förutspår MOS-poäng programmatiskt. Du kan integrera dessa i dina arbetsflöden för att kontinuerligt övervaka MOS över tid.
AI vs mänskliga testmått: FCR, AHT och CSAT
Att räkna ut MOS över tid visar modellens utveckling, men du kan få mer kontext genom att jämföra med mänsklig prestanda. Att se vad människor faktiskt uppnår i liknande roller visar om din voice agent presterar nära idealnivån.
Här är några mätvärden att jämföra mellan AI och mänskliga agenter.
AI-agenter bör kunna matcha mänsklig FCR och CSAT, samtidigt som de förbättrar AHT avsevärt. Den förbättringen beror på att AI-agenter ofta hanterar mer generella samtal än människor. Många företag har ett arbetsflöde där AI-agenter tar första kontakten och skickar vidare till mänskliga agenter om det blir för komplext.
Data från Poe, en AI-jämförelsetjänst, visar att ElevenLabs hade bäst förmåga att lösa förfrågningar, och slutförde 74,4 % av alla inkommande ärenden. Det har lett till snabbt växande användning, där Eleven v3 och v2.5-Turbo står för över 60 % av alla meddelanden till AI-modeller över tid.
Meddelanden till AI-modeller över tid, ElevenLabs leder poe voice agent-utvärderingen
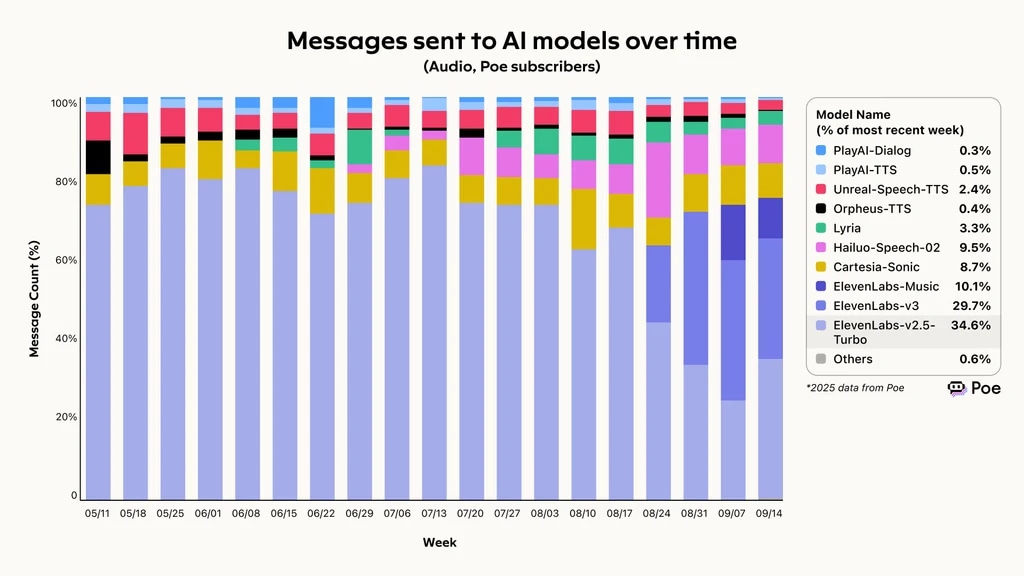
Meddelanden till AI-modeller över tid, enligt Poe
Vanliga misstag vid test av voice agents
När du följer ett ramverk för utvärdering av voice agents är det lätt att bara testa bästa möjliga scenario. I verkligheten kommer kundernas vardagliga upplevelse av dina voice AI-system inte från idealförhållanden.
Här är tre vanliga misstag vid test av voice agents – och hur du undviker dem:
- Testa bara enklaste vägen: Särskilt när du väljer ljudklipp för MOS, se till att ta med svårare fall. Klipp med bakgrundsljud eller brytning är mycket vanliga, så att bara testa på 'rent' ljud ger felaktig MOS.
- Prioritera inlåsning framför lösning: Om du optimerar dina modeller för att hålla användare kvar i agenten ökar inlåsningsgraden utan att förbättra resultatet. Om din FCR är låg trots hög inlåsning fastnar användarna i en frustrerande loop. Se till att det alltid går att prata med en mänsklig agent om användaren vill.
- Ignorera latensprocentiler: SLA:er anger ofta latens på P95-nivå. Det är viktigt för en jämn upplevelse för de flesta kunder, men glöm inte att de sista 5 % också är riktiga användare. I stor skala är 5 % av 10 000 samtal ändå 500 personer som får en långsam upplevelse. Fokusera på P99 som huvudmål, inte bara median eller P95.
Genom att tänka på detta kan du sätta rättvisa och representativa baslinjer istället för att utgå från idealvärden.
Argument för utvärdering utifrån användningsområde
Även om de sex pelarna i ramverket ger vägledning, beror vikten av varje pelare på din bransch. Ett företag inom finansiella tjänster kan till exempel prioritera efterlevnad och verktygsanvändning, medan ett konsumentvarumärke fokuserar på TTS-röstkvalitet.
Här är två exempel på utvärdering utifrån användningsområde och hur det påverkar balansen mellan pelarna.
Kundsupport
I vissa branscher, som callcenter, är andra mått som First Call Resolution (FCR) viktiga. Att kunna lösa ett inkommande samtal utan mänsklig hjälp minskar trycket på kundtjänst.McKinsey uppskattar att callcenter med voice agents kan minska samtalsvolymen med upp till 50 %.
Även om det inte är lika viktigt som task success rate är inlåsningsgrad en annan faktor. Inlåsningsgrad mäter samtalets totala längd. Om inlåsningsgraden är hög men FCR låg hålls kunder kvar i samtalet utan att få en lösning, vilket kan bli frustrerande.
Andra mått att följa är AHT, där AI-agenter ska lösa rutinproblem snabbt. Därför prioriterar kundsupport samtalskvalitet, särskilt turordning och fallback-frekvens, framför andra områden.
Sjukvård
Sjukvård är en hårt reglerad bransch med strikta krav, vilket gör voice agent-drift extra känslig. Efterlevnad är centralt och gör att säkerhetspelaren väger tyngst, tillsammans med intelligens.
Sjukvårds-chatbots behöver hantera bokningar, tillgång till digital vård, symtomtriage och försäkringsfrågor. Allt detta kräver hög intelligens och verktygsanvändning, vilket visar att branschspecifika krav styr vilka pelare som är viktigast.
Oavsett bransch hjälper det dig att förstå och balansera de viktigaste pelarna för utvärdering av voice agents för att hitta rätt agent för dig.
Bygg med ElevenAgents för hög prestanda och låg latens
Plattformen du bygger på avgör hur dina voice agents presterar i verkliga arbetsflöden. Särskilt när du möter dina kunder behöver du vara säker på att agenten levererar i varje kategori.
ElevenAgents är byggt för produktion av voice agents, med branschledande TTS via Eleven v3, realtids-STT med Scribe v2, och ett orkestreringslager för agenter för företagsskala. Varje del är byggd för att klara de benchmark som beskrivs i ramverket, så att du kan leverera hög kvalitet till dina kunder.
Oavsett om du jämför alternativ eller är redo att börja bygga har ElevenLabs en väg för dig. Utforska ElevenAgents-plattformen för att se hur den passar dina behov, eller registrera dig och börja bygga redan idag.
.webp&w=3840&q=80)


