
Stärka och skydda val
- Kategori
- Företag
- Datum
Scribe v2 är den mest exakta Speech to Text-modellen. Scribe v2 Realtime sätter standarden för live-transkriptioner - driver agenter och realtidsapplikationer. Båda tillgängliga via API.


Scribe v2 Realtime fångar live-tal på under 150 ms med exceptionell noggrannhet – byggd för agenter, möten och AI-agenter som kräver omedelbar förståelse.
Scribe v2 Realtime levererar branschledande noggrannhet med under 150 ms latens, vilket sätter en ny standard för realtids taligenkänning.
Upptäck automatiskt när tal börjar och slutar, segmentera tal med precision för smidigare livebearbetning.
Levererar exceptionell noggrannhet över accenter, dialekter och inspelningsförhållanden.
Bygg in Scribe Realtime v2 i dina produkter med API. Med full streamingstöd och kontroll.


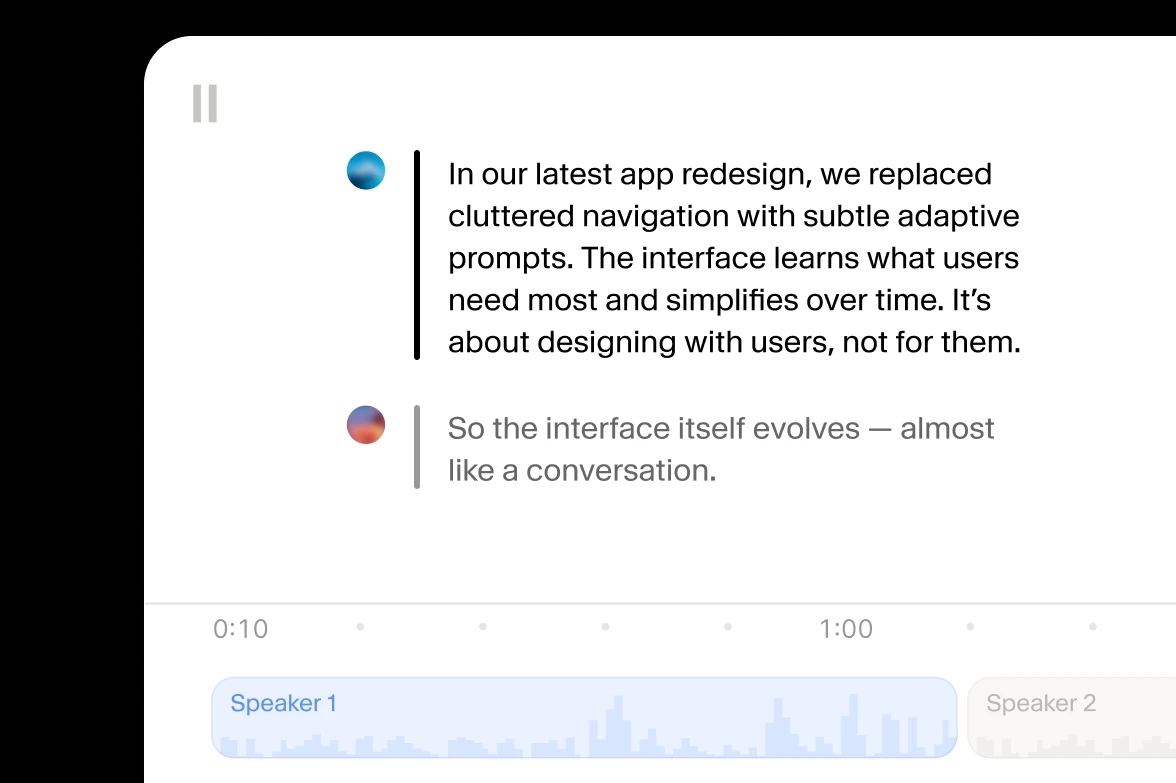
Ladda upp ljud eller video i vilket format som helst — MP4, MOV, MP3, WAV och mer. Scribe v2 konverterar automatiskt tal till exakt text, redo för undertexter, textremsor eller redigering.
Scribe v2 uppnår branschledande transkriptionsnoggrannhet, levererar ren, redigerbar text även i utmanande ljudförhållanden eller över olika accenter.
Välj upp till 1000 specifika ord eller meningar som Scribe ska transkribera exakt utifrån sammanhanget.
Från skratt till fotsteg, Scribe v2 taggar varje ljudhändelse, berikar dina transkriptioner med full kontext.
Scribe v2 känner automatiskt igen och märker upp varje talare, sätter tidsstämplar på entiteter och döljer känslig information i transkriptioner.

Integrera Scribe v2 och Scribe v2 Realtime i din produkt med API eller SDK:er.

Aktivera realtidsröstinteraktioner med omedelbar, låg latens-transkription.
.webp&w=3840&q=100)
Konvertera inspelningar till redigerbar text, undertexter och återanvändbart innehåll.
Vår AI Speech to Text-transkription stöder över 90 språk, välj bara språket och ladda upp din ljudfil.














































































