Möt Eleven v3.
Vår mest uttrycksfulla AI-röstmodell.


294/1000
Drivs av Eleven v3
Kontrollera känsla, leverans och riktning med ljudtaggar
Skapa kontrollerbart, uttrycksfullt tal med lager av känsla, ljudhändelser och uppslukande ljudlandskap.

Generera dynamiska samtal mellan flera talare
Skapa ljudsamtal där talare delar kontext och känsla, vilket gör den genererade dialogen naturlig och mänsklig.

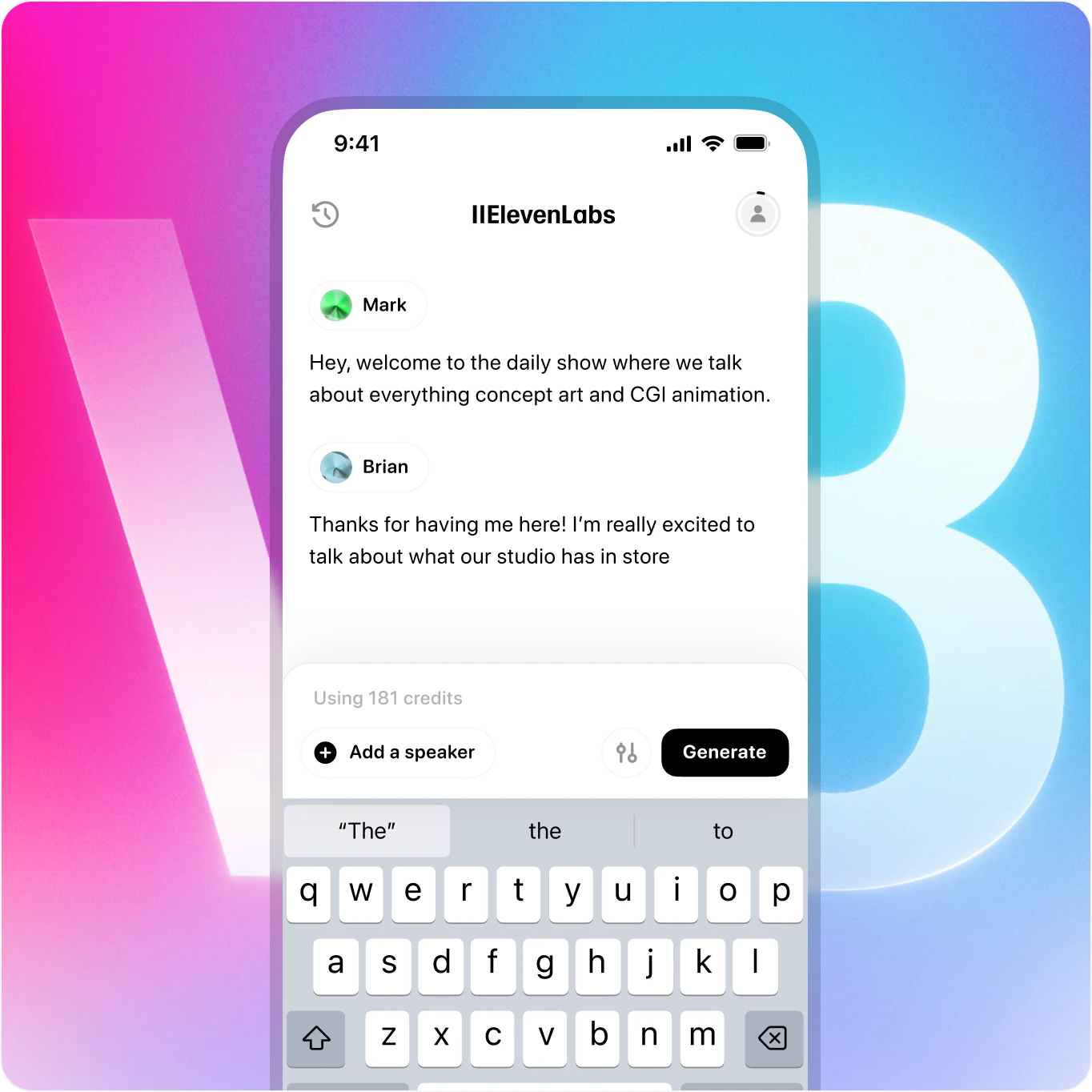
Ta med v3 överallt - nu tillgänglig på mobilen
Skapa naturtrogen tal med rik emotion - direkt från din telefon. Vår röst-AI levererar studiokvalitet var du än är.
Mänskligt liknande tal på 70+ språk
Nå globala publiker med uttrycksfullt och nyanserat tal på alla stora språk.

Engelska

Kinesiska

Spanska

Franska

Portugisiska

Tyska

Japanska

Italienska

Hindi
Upplev vår mest uttrycksfulla modell med känslomässigt djup och rik leverans.
Eleven v3 skiljer sig från andra ElevenLabs-modeller och erbjuder ett brett dynamiskt omfång som styrs genom inline-ljudtaggar.
Flera talare (Dialogläge)
Taggstöd
Fullt spektrum av känslor, händelser, övergripande riktning, rytm
Standardliknande pauser, avbrott
Språk
70+
29
Bygg med Eleven v3 API
Generera naturtrogen tal på över 70 språk med känsla, riktning och flerhögtalarkontroll med hjälp av inline-ljudtaggar.

import { ElevenLabsClient, play } from '@elevenlabs/elevenlabs-js';
import 'dotenv/config';
const elevenlabs = new ElevenLabsClient();
const voiceId = 'JBFqnCBsd6RMkjVDRZzb';
const audio = await elevenlabs.textToSpeech.convert(voiceId, {
text: '[sakta] På den tiden... [skrattar] hade vi inga telefoner.
[viskar] Bara grusvägar och [hostar] stora drömmar. [ledsen] Sedan hände det',
modelId: 'eleven_v3',
outputFormat: 'mp3_44100_128',
});
await play(audio);