Text to Speech vs Speech to Text: Qual é a diferença?
- Publicado
- Última atualização
OuvirOuça este artigo
Imagine a cena: você está dirigindo para o trabalho e seu smartphone lê seus e-mails não lidos usando Transformar Texto em Áudio (TTS). Melhor ainda, você responde sem precisar tocar no celular ou tirar os olhos da estrada — tudo graças ao Speech to Text (STT).
Essas tecnologias não são apenas conceitos futuristas. Elas já fazem parte do nosso dia a dia, facilitando tarefas e tornando tudo mais acessível.
Vamos mergulhar no mundo do TTS e STT com IA, entender o que são, suas diferenças, como funcionam, o que considerar ao escolher um provedor e como estão sendo aplicadas em diferentes setores.
As diferenças entre TTS e texto a partir da fala
Existem algumas diferenças importantes entre Transformar Texto em Áudio e a tecnologia de texto a partir da fala. Veja a seguir.
Funcionalidade
TTS converte texto escrito em fala, enquanto Speech to Text (STT) faz o oposto, transcrevendo a fala em texto. O TTS é usado para tornar conteúdos escritos audíveis, ajudando pessoas com deficiência visual ou dificuldades de leitura. Já o STT transforma a fala em texto, sendo útil para ditados e comandos de voz.
Contexto de uso
Transformar Texto em Áudio é comum em leitores digitais, sistemas de anúncio público e assistentes virtuais para fornecer saídas de áudio. O STT é usado em serviços de transcrição, aplicativos controlados por voz e legendas em tempo real para pessoas com deficiência auditiva. O TTS é focado na saída de informações em áudio, enquanto o STT é centrado na entrada, capturando e processando a fala.
Abordagem tecnológica
Transformar Texto em Áudio envolve análise de texto, processamento de linguagem e síntese de voz. Precisa transmitir nuances da fala, como entonação e ritmo. O STT exige reconhecimento avançado de voz para transcrever diferentes sotaques, dialetos e padrões de fala, muitas vezes em tempo real.
O que é TTS (TTS)?
Transformar Texto em Áudio (TTS) é uma tecnologia que converte texto escrito em fala. Na essência, Transformar Texto em Áudio permite que computadores leiam em voz alta, transformando qualquer texto em uma voz sintética. Essa tecnologia é muito usada em assistentes virtuais e ferramentas de acessibilidade para quem tem dificuldades de leitura.
Um exemplo de TTS avançado é o TTS da ElevenLabs. O TTS da ElevenLabs se destaca por gerar vozes naturais e realistas. Isso é possível graças a algoritmos de IA sofisticados, que não só imitam o som da fala humana, mas também entendem e reproduzem nuances e entonações típicas da fala natural.
Esse nível de realismo faz do TTS da ElevenLabs uma ótima opção para criar conteúdos de áudio envolventes, melhorar interfaces com feedback por voz e oferecer uma alternativa acessível de leitura para pessoas com deficiência visual.
O que é Texto a partir da Fala (Speech to Text, STT)?
Text from Speech, also known as Speech to Text (STT), is the process of converting spoken language into written text. This speech recognition technology is pivotal in creating transcriptions from audio recordings, enabling voice commands, and facilitating real-time captioning for accessibility.
ElevenLabs made significant advancements in STT technology. Our Scribe model efficiently converting audio and video into text in 99 languages. It offers a user-friendly interface, making it ideal for capturing meetings, lectures, and interviews in written form, from audio and video files.
Como funciona o TTS?
A tecnologia TTS transforma texto escrito em fala audível, passando por várias etapas detalhadas.
Primeiro, o sistema Transformar Texto em Áudio analisa o texto e o divide em fonemas — as menores unidades sonoras de uma língua. Essa divisão é essencial para que o sistema pronuncie corretamente as palavras.
Depois dessa segmentação, o sistema converte esses sons em fala digital. Aqui, a inteligência artificial (IA) tem papel fundamental. Usando algoritmos treinados com grandes volumes de fala, o sistema consegue gerar vozes com tons e ritmos próximos aos humanos. A fala gerada é alinhada aos fonemas identificados, resultando em um áudio natural.
Graças aos avanços em IA e aprendizado de máquina, as tecnologias modernas de Transformar Texto em Áudio evoluíram muito. Agora, conseguem entender nuances de contexto, suportar vários idiomas e até simular emoções. Essas melhorias tornam a fala mais natural e as interações com dispositivos digitais mais envolventes.
Quais são os melhores provedores de TTS?
The best TTS software solutions are ElevenLabs, Murf, and PlayHT. Here’s a brief rundown of their main features, pros, cons, and rating out of 5.
Como funciona o Speech to Text?
A tecnologia Speech to Text (STT) transforma a fala em texto por meio de um processo complexo e com várias etapas.
Primeiro, ela capta a fala, geralmente por um microfone. Esse áudio é convertido em formato digital para ser processado. O núcleo do STT está na análise desse áudio digital, usando algoritmos para dividir a fala em segmentos menores e reconhecíveis.
Esses segmentos são fonemas, as menores unidades sonoras da fala. O sistema STT compara esses fonemas com um modelo linguístico para identificar palavras e frases. Essa etapa é fundamental para entender diferentes sotaques, dialetos e variações de fala.
Depois, o sistema aplica técnicas de processamento de linguagem natural (PLN). O PLN ajuda a entender o contexto e a estrutura da fala, permitindo transcrições mais precisas. Também possibilita lidar com frases complexas e termos técnicos.
Sistemas STT avançados usam aprendizado de máquina e deep learning, melhorando conforme recebem mais dados e uso. Assim, aprendem novos padrões de fala, sotaques e até idiomas, aumentando a precisão e eficiência.
Resumindo, a tecnologia STT envolve captação de áudio, análise fonêmica, modelagem linguística e PLN, tudo apoiado por aprendizado de máquina para converter fala em texto de forma eficiente.
Quais são os melhores provedores de Speech to Text?
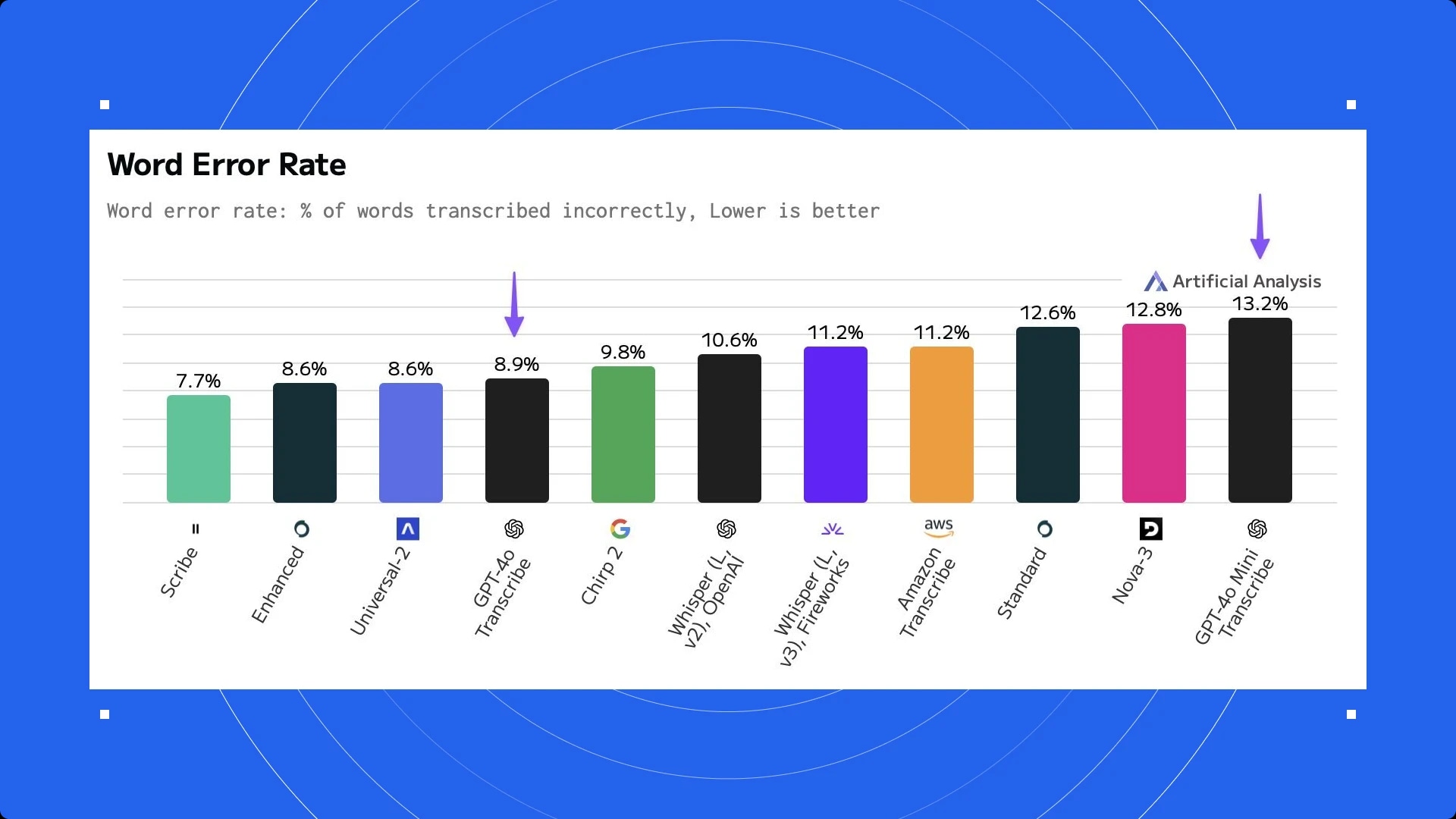
The best speech-to-text providers are ElevenLabs' Scribe, followed by OpenAIand other providers like Google.
TTS e STT: Precisão e desafios
TTS e Speech to Text buscam precisão próxima à humana. A cada dia, a precisão melhora — mas ainda não é perfeita. Veja o que esperar em termos de precisão e desafios dessas tecnologias.
Precisão e desafios do TTS (TTS)
A voz IA Transformar Texto em Áudio evoluiu muito, mas ainda enfrenta desafios. O principal é alcançar vozes realmente naturais. Embora os sistemas atuais gerem áudio claro e compreensível, transmitir emoções e entonações humanas ainda é difícil. Além disso, o TTS pode errar na interpretação de contexto, pronunciando palavras de forma incorreta. Outro desafio é personalizar vozes para diferentes necessidades, como sotaques e estilos de fala, o que é essencial para acessibilidade global.
Precisão e desafios do Texto a partir da Fala/Speech to Text (STT)
O STT avançou bastante em precisão, principalmente com o deep learning. Porém, ainda encontra dificuldades em ambientes barulhentos, onde ruídos atrapalham o reconhecimento de voz. Transcrever diferentes sotaques e dialetos também é um desafio. Além disso, sistemas STT podem confundir palavras homófonas (que soam igual, mas têm significados diferentes) e ter dificuldade com frases complexas ou gírias, o que afeta a eficácia em situações reais.
Aplicações em diferentes setores
Transformar Texto em Áudio e Speech to Text têm usos inovadores em vários setores, mudando a forma como interagimos com informações e ampliando a acessibilidade.
Aplicações do TTS em setores
O TTS é usado em diversas áreas. Na educação, ajuda a criar materiais acessíveis para alunos com dificuldades de leitura ou deficiência visual, como transformar livros em audiolivros.
Na indústria automotiva, o TTS é usado em respostas de voz em sistemas de navegação. No atendimento ao cliente, o TTS automatiza respostas em call centers, aumentando a eficiência. Também é muito usado no entretenimento, especialmente em jogos e assistentes virtuais, proporcionando experiências interativas.
Aplicações do STT em setores
O STT tem aplicações variadas em muitos setores. Na saúde, ajuda a transcrever conversas entre médicos e pacientes e a ditar documentos clínicos, melhorando a eficiência. No setor jurídico, é usado para transcrever audiências e documentos legais. Na mídia, o STT é fundamental para legendas em tempo real em transmissões para pessoas com deficiência auditiva. No mundo corporativo, facilita a transcrição de reuniões, melhorando o registro e o acesso à informação.
Considerações finais
TTS (TTS) e Speech to Text (STT), apesar de parecidos, têm funções diferentes. O TTS transforma texto em fala, dando vida ao conteúdo escrito com vozes naturais. Já o STT faz o caminho inverso, convertendo a fala em texto e capturando nuances da linguagem falada.
Ambas as tecnologias usam IA avançada, mas atendem a necessidades distintas: Transformar Texto em Áudio para consumir conteúdo escrito em áudio, e STT para criar registros escritos a partir da fala.
Pronto para começar? Experimente o Eleven v3, nosso modelo de text-to-speech mais expressivo até agora.
Se quiser conhecer a tecnologia TTS de ponta, cadastre-se na ElevenLabs hoje mesmo. Você vai se surpreender.




