Ramy oceny agentów głosowych: 6 filarów wyjaśnionych
- Autor
- Jack Limebear
- Opublikowano
- Ostatnia aktualizacja
PosłuchajPosłuchaj tego artykułu
Voice agents muszą korzystać z kilku narzędzi jednocześnie. To delikatna sztuka – nagrywanie wypowiedzi klienta w czasie rzeczywistym przez
Przy tylu elementach, jak rzetelnie ocenić skuteczność agenta głosowego?
W tym artykule przedstawiamy ramy oceny agentów głosowych oparte na sześciu filarach. Dowiesz się, co dokładnie mierzyć, by ocenić skuteczność agenta. Pokażemy też, dlaczego różne branże powinny inaczej ważyć te filary i na jakie błędy uważać podczas testowania.
Podsumowanie
- Sześć głównych filarów oceny agentów głosowych to: jakość głosu TTS, jakość rozmowy, korzystanie z narzędzi i realizacja zadań, inteligencja, zgodność i zabezpieczenia oraz niezawodność.
- Najważniejsze cele produkcyjne to MOS na poziomie 4,3, TSR powyżej 85% i czas do pierwszego dźwięku poniżej 500 ms.
- Różne branże będą przykładać inną wagę do poszczególnych filarów, a niektóre wdrożenia skupią się na jednym bardziej niż na innych.
- Typowe błędy testowania to ocenianie tylko czystego audio i ignorowanie skoków opóźnień P99.
- ElevenLabs prowadzi w najważniejszych metrykach: Scribe v2 osiąga najniższy WER na rynku – 2,2% (Artificial Analysis, czerwiec 2026), Flash v2.5 i Turbo v2.5 to najszybsze modele (Artificial Analysis, czerwiec 2026), a ElevenAgents zapewnia opóźnienie inferencji modelu na poziomie ~75 ms.
Czym są ramy oceny agentów głosowych?
Ramy oceny agentów głosowych AI to uporządkowany system, który pozwala testować skuteczność w różnych obszarach. Dobre ramy obejmują metryki od jakości dźwięku po przebieg rozmowy i zgodność z przepisami.
W przeciwieństwie do czatbota tekstowego, agent głosowy korzysta z co najmniej trzech technologii: rozpoznawania mowy (ASR), które zamienia słowa użytkownika na tekst; LLM, który generuje odpowiedź; i TTS, który zamienia odpowiedź z powrotem na dźwięk. Jeśli którykolwiek z tych elementów zawiedzie, całość traci na jakości.
Ta złożoność sprawia, że firmy muszą oceniać agentów głosowych przed wyborem dostawcy i wdrożeniem. Każde dodatkowe opóźnienie lub niedokładna odpowiedź mogą mieć realne skutki, np. utratę klientów czy nawet kary i straty wizerunkowe.
Ramy oceny agentów głosowych wykorzystują benchmarki i mierzalne dane, by określić, czy agent nadaje się do danego zastosowania. Z biznesowego punktu widzenia możliwość porównania różnych modeli głosowych pozwala wybrać najlepszy dla twoich klientów.
Sześć filarów oceny agentów głosowych, które warto sprawdzić
Chociaż tworzenie i wdrażanie agenta AI nigdy nie było prostsze, to procesy działające w tle są dość złożone. Kilka elementów współpracuje, by słuchać użytkownika, zrozumieć jego intencje, przekazać je do LLM i wygenerować odpowiedź audio – wszystko dzieje się niemal jednocześnie.
Aby wybrać najlepszego agenta głosowego, firmy potrzebują solidnych ram do porównania.
Jeśli bardziej interesują cię wyniki testów, to Sztuczna analiza oferuje porównania agentów na podstawie różnych komponentów. Poniżej widać wyniki pojedynku szybkości modeli, gdzie ElevenLabs Turbo v2.5 i Flash v2.5 wyraźnie prowadzą pod względem liczby przetwarzanych znaków na sekundę.
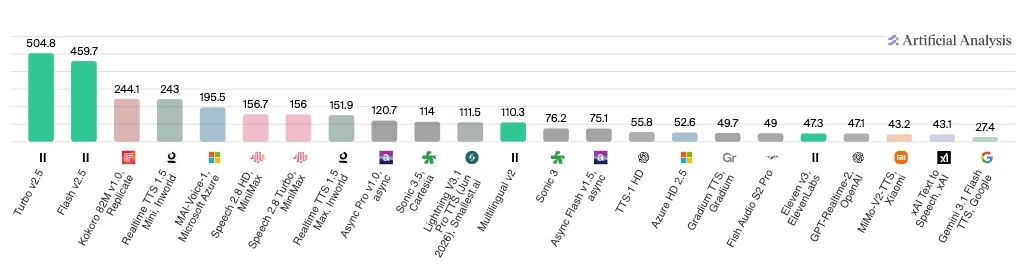
Dla deweloperów i firm, które chcą samodzielnie testować, oto sześć filarów oceny agenta AI, które warto sprawdzić:
- Jakość głosu TTS: Jak naturalnie, wyraźnie i ekspresyjnie brzmi syntezowany głos dla użytkownika. Najlepsze modele, jak Eleven v3, oferują ludzką, emocjonalną mowę w ponad 70 językach.
- Jakość rozmowy: Czy model rozumie ludzką mowę, wychwytuje sens i szybko odpowiada w kontekście przez wiele wymian?
- Korzystanie z narzędzi: Na ile agent AI potrafi samodzielnie wykonać zadania, korzystając z dostępnych zasobów, bez udziału człowieka.
- Inteligencja: Jak dobrze model rozumuje, radzi sobie z nowymi pytaniami i unika błędnych lub zmyślonych odpowiedzi.
- Zgodność i zabezpieczenia: Oprócz wszystkich funkcji
- Niezawodność: Elementy takie jak całkowity czas działania i stabilność pod obciążeniem pokazują, czy Conversational AI może skalować się wraz z rosnącym zapotrzebowaniem.
Każdy z tych filarów jest niezależny, ale razem tworzą wysoką jakość końcową dla użytkownika. Na przykład, jeśli model poprawi jakość głosu, ale nadal będzie miał duże opóźnienia, klient odczuje niezręczne przerwy przed odpowiedzią.
Przyjrzyjmy się bliżej każdemu z tych filarów oceny głosu AI.
Jakość głosu TTS
Zaczynamy od jakości głosu, bo to pierwsza rzecz, którą zauważy człowiek w kontakcie z agentem AI. Jeśli brzmi sztucznie lub dziwnie, cała rozmowa wypada gorzej.
Jedną z podstawowych metryk, zdefiniowaną przez ITU-T, jest Mean Opinion Score (MOS). MOS to skala od 1 do 5, gdzie 1 to nieużywalny, a 5 to świetny głos. To subiektywna ocena – korzysta się z ludzkich słuchaczy i zbiera ich opinie po rozmowie.
Wynik poniżej MOS 3,5 jest dziś słaby i prawdopodobnie wpłynie negatywnie na zadowolenie klientów.
MOS to metryka ludzka, ale wpływa na nią kilka technicznych czynników:
- Spójność tonu i jitter: Ton i jitter to dwa elementy, które ludzie naturalnie wychwytują. „Ton” to zmiany intonacji, np. gdy podnosisz głos zadając pytanie. Jitter to wahania w rozumieniu tonu przez model, przez co nie utrzymuje on spójnej melodii w zdaniu. Standard branżowy dla jitter to 30 ms.
- Ekspresja emocji: Nawet wyraźny i precyzyjny głos brzmi źle, jeśli ton nie pasuje do emocji w zdaniu. Bez właściwych sygnałów emocjonalnych ludzie gorzej odbierają agentów AI i oceniają ich niżej. ElevenAgents oferuje prawie ludzką ekspresję by każda odpowiedź miała wyraźny wydźwięk emocjonalny.
- Szum tła: Szum tła w agentach głosowych ma dwa aspekty. W odpowiedziach można dodać delikatny szum, by brzmiały naturalniej. Po stronie wejścia filtr szumów w warstwie STT to opcja, która poprawia dokładność. Testując agenta, sprawdź oba: czy szum brzmi naturalnie i jak działa STT z filtrem i bez.
Przy obliczaniu MOS celuj w 4,3–4,5, co oznacza wysokie oceny we wszystkich tych kategoriach. Do automatycznej oceny MOS na dużą skalę możesz użyć narzędzi takich jak UTMOS i NISQA.
Jakość rozmowy
Jakość rozmowy to filar łączący jakość głosu i realizację zadań. Chodzi o to, jak skutecznie agent rozumie potrzeby użytkownika, potrafi przerwać w odpowiednim momencie i prowadzi rozmowę do końca przez kilka wymian.
Główna metryka to skuteczność rozpoznawania intencji, zwykle w zakresie 85–92%, a najlepsi osiągają nawet 96%. Nawet 85% oznacza, że 15% zapytań jest źle rozpoznanych i trafia do niewłaściwych zasobów.
Na wysoką skuteczność rozpoznawania intencji wpływają:
- Zmiana ról w rozmowie: Chodzi o to, jak agent zarządza naturalnym przebiegiem rozmowy – kiedy słucha, kiedy odpowiada, kiedy czeka na więcej informacji. Dotyczy to też przerywania odpowiedzi (barge-in), gdzie model przerywa odpowiedź i generuje nową na podstawie nowego wejścia. ElevenLabs korzysta z wielokontekstowego websocketu by płynnie obsługiwać takie przerwania.
- Opóźnienie: Opóźnienie to czas od zakończenia wypowiedzi przez użytkownika do rozpoczęcia odpowiedzi audio przez agenta. Produkcyjne agenty głosowe powinny celować w czas do pierwszego dźwięku poniżej 500 ms, a najlepiej poniżej 300 ms. Modele ElevenLabs Flash oferują czas inferencji ~75 ms, co daje przewagę w tej kategorii.
- Wskaźnik fallback: To miara, jak często agent AI nie rozumie użytkownika i prosi o powtórzenie lub doprecyzowanie. Wynika to głównie z dokładności STT – jeśli warstwa rozpoznawania mowy źle zrozumie klienta, LLM dostaje błędne dane. Wskaźnik fallback liczy się tak: Fallback rate (%) = (Liczba fallbacków / Liczba wszystkich interakcji) * 100.
ElevenLabs Scribe V2 ma najniższy WER – 2,2% w teście Artificial Analysis dla modeli speech to text
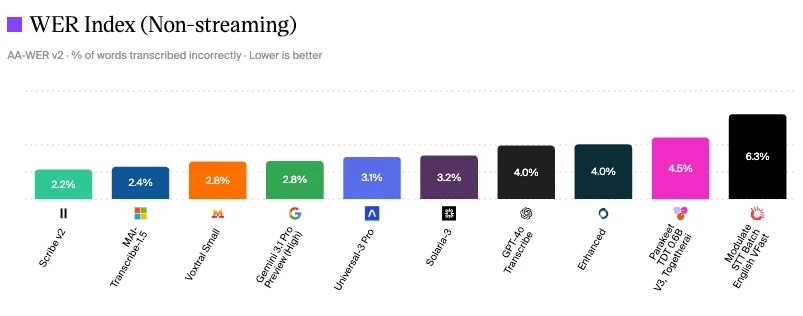
Ocena modeli speech to text według Artificial Analysis
Jednym ze sposobów mierzenia jakości rozmowy są branżowe benchmarki dla różnych komponentów. Jak widać, Scribe v2 od ElevenLabs ma najniższy WER – 2,2% (czerwiec 2026), co oznacza mniej błędów, mniej fallbacków i lepsze rozpoznawanie intencji.
Firmy mogą zauważyć, że jakość rozmowy zależy też od workflow, w którym działa agent. W obsłudze klienta ważna będzie np. jakość przekazania sprawy człowiekowi lub rozwiązywania FAQ.
Korzystanie z narzędzi i realizacja zadań
Jakość rozmowy mówi, jak przebiegała rozmowa, a realizacja zadań – czy zakończyła się sukcesem. Firmy powinny zwracać szczególną uwagę na ten filar, bo jest bezpośrednio powiązany z efektami biznesowymi.
Jedną z miar korzystania z narzędzi jest skuteczność wypełniania pól (slot-fill), czyli jak dobrze agent AI radzi sobie z rutynowymi zadaniami, np. uzupełnianiem formularza danymi klienta. Wysoka skuteczność pokazuje, że agent płynnie przechodzi od rozmowy do działania bez utraty informacji.
Task Success Rate (TSR) to procent zadań zakończonych sukcesem przez agenta. Sukces oznacza tu zarówno zrozumienie prośby, jak i użycie odpowiednich narzędzi (API, bazy danych, RAG, wewnętrzne bazy wiedzy) do jej realizacji.
Wzór na TSR:
TSR = (Zadania zakończone sukcesem / Wszystkie podjęte zadania) x 100
Gotowe do produkcji agenty głosowe powinny celować w TSR powyżej 85%, monitorując dokładność i niezawodność wywołań narzędzi. By uniknąć spadków TSR, testuj regresję przy każdej zmianie promptu lub modelu. Nawet drobna zmiana może mocno wpłynąć na TSR.
Inteligencja
Inteligencja to zdolność rozumowania i zaawansowane funkcje agenta głosowego. To właśnie ten filar odróżnia zwykły IVR od agenta AI.
Warto ocenić tu m.in.:
- Ryzyko halucynacji: Halucynacje, czyli generowanie przez agenta nieprawdziwych lub niezgodnych z dokumentacją informacji, są szczególnie groźne w głosie AI, bo mogą brzmieć bardzo przekonująco. Najnowsze badania pokazują że częste halucynacje mocno obniżają satysfakcję klientów z agentów głosowych.
- Radzenie sobie z pytaniami spoza zakresu: Inteligentny agent rozpoznaje, gdy pytanie wykracza poza jego kompetencje i potrafi odpowiednio zareagować. Zamiast wymyślać odpowiedź, odmawia lub kieruje rozmowę z powrotem na właściwy tor.
- Utrzymanie kontekstu: Czy agent potrafi śledzić wątki i ustalenia przez kilka wymian? Bez tego klienci muszą się powtarzać lub dostają sprzeczne odpowiedzi.
- Rozumowanie i logika wieloetapowa: Czy agent radzi sobie z warunkami i łańcuchami wnioskowania przez kilka wymian? W technicznych zastosowaniach, np. w finansach, umiejętność rozumowania w określonym kontekście jest kluczowa.
Istnieją zewnętrzne benchmarki dla tych obszarów. Np. Stanford HELM ocenia LLM w różnych kategoriach, a TruthfulQA sprawdza, jak często pojawiają się fałszywe odpowiedzi.
Zaletą ElevenAgents jest to, że – w przeciwieństwie do niektórych platform – możesz całkowicie wymienić warstwę LLM. W praktyce oznacza to, że możesz podłączyć model, który najlepiej wypada w benchmarkach rozumowania dla twojego zastosowania.
Zgodność i zabezpieczenia
Firmy muszą wdrażać aktywne zabezpieczenia, by zapobiegać szkodliwym lub niezgodnym z polityką odpowiedziom. W przeciwieństwie do instrukcji systemowych, które można obejść, niezależne zabezpieczenia działają jako osobna warstwa poza modelem. Sprawdzają odpowiedzi przed wysłaniem do użytkownika i zatrzymują rozmowę, jeśli pojawi się ryzyko.
Ważna jest też audytowalność – produkcyjne agenty muszą prowadzić szczegółowe logi decyzji i odpowiedzi, by umożliwić późniejszą kontrolę. W branżach regulowanych udowodnienie zgodności po fakcie jest równie ważne, jak jej bieżące utrzymanie.
Dokładne przepisy, których musisz przestrzegać, zależą od branży. Najczęściej spotykane ramy to:
- HIPAA: Dla danych medycznych w USA.
- PCI-DSS: Dla agentów obsługujących dane kart płatniczych.
- RODO: Obowiązki dotyczące prywatności danych w UE i dla firm obsługujących klientów z UE.
Dla firm oceniających zgodność, ElevenLabs spełnia wymagania AICPA SOC Type II i RODO oraz posiada certyfikat AIUC-1. AIUC-1 to standard bezpieczeństwa stworzony specjalnie dla agentów AI.
Niezawodność
Niezawodność to ostatni filar naszych ram oceny agentów głosowych – chodzi o to, czy agent zawsze działa w czasie rzeczywistym.
Oceniając agenta głosowego, zwróć uwagę na:
- Czas działania (uptime): Wdrożenia skierowane do klientów wymagają 99,9% uptime, by uniknąć przerw. Szczególnie w obsłudze 24/7 niezawodność jest kluczowa.
- Łagodne przechodzenie w tryb awaryjny: Jeśli któryś z elementów zaczyna zawodzić, agent powinien przekierować rozmowę do człowieka, zamiast działać z błędami lub pod zwiększonym obciążeniem.
- Wydajność pod obciążeniem:Testy obciążeniowe powinny symulować co najmniej 2x spodziewaną maksymalną liczbę równoczesnych rozmów przed startem. Testy pod dużym obciążeniem pozwalają wykryć wzrost opóźnień lub spadek wydajności, które pojawiają się dopiero w skali.
Nawet najlepszy model może być bezużyteczny, jeśli nie skaluje się do twoich potrzeb. ElevenAgents zaufało już 1 000 000 twórców i firm, co pokazuje, że platforma radzi sobie z wdrożeniami na dużą skalę bez kompromisów w wydajności.
Jak mierzyć MOS dla agentów głosowych (krok po kroku)
Jeśli chcesz ręcznie zmierzyć MOS, potrzebujesz dużej grupy słuchaczy i zestawu nagrań z prawdziwych rozmów. To uporządkowany proces: zbierasz opinie, uśredniasz i analizujesz dane.
Jak w praktyce zmierzyć MOS dla agentów głosowych:
- Przygotuj zestaw testowy: Wybierz reprezentatywną próbkę nagrań z agenta – co najmniej 100 klipów z różnych rozmów.
- Przeprowadź sesję oceniania: Poproś słuchaczy, by ocenili każdy klip w skali 1–5 za jakość komunikacji.
- Zbierz i policz wyniki: Uśrednij oceny dla każdego klipu, a potem dla całej próbki – to twój MOS. Wynik 4,3 lub wyższy oznacza, że agent jest gotowy do produkcji.
To czasochłonny proces, ale daje rzetelny wynik MOS dla wybranego agenta. Jeśli chcesz testować na dużą skalę, możesz zastąpić słuchaczy narzędziami automatycznymi, jak NISQA, które przewidują MOS programowo. Takie systemy możesz zintegrować z pipeline, by stale monitorować MOS.
AI kontra ludzie: benchmarki FCR, AHT i CSAT
Regularne liczenie MOS pozwala śledzić postępy modelu, ale dodatkowy kontekst daje porównanie z wynikami ludzi. Zobaczenie, co osiągają ludzie na podobnych stanowiskach, pokaże, czy agent głosowy zbliża się do ideału.
Oto kilka metryk do porównania AI z ludźmi:
Agenty AI powinny dorównywać ludziom w FCR i CSAT, a jednocześnie znacznie poprawiać AHT. Wynika to z tego, że AI zwykle obsługuje bardziej ogólne rozmowy niż człowiek. Wiele firm wdraża workflow, gdzie AI jest pierwszą linią, a trudniejsze sprawy przekazuje ludziom.
Dane z 2025 roku od Poe, agregatora porównań AI, pokazują, że ElevenLabs najlepiej radził sobie z realizacją próśb, kończąc sukcesem 74,4% wszystkich zgłoszeń. Przełożyło się to na szybki wzrost użycia – Eleven v3 i v2.5-Turbo odpowiadają za ponad 60% wiadomości wysyłanych do modeli AI.
Wiadomości wysyłane do modeli AI w czasie – ElevenLabs prowadzi w ramie oceny agentów głosowych Poe
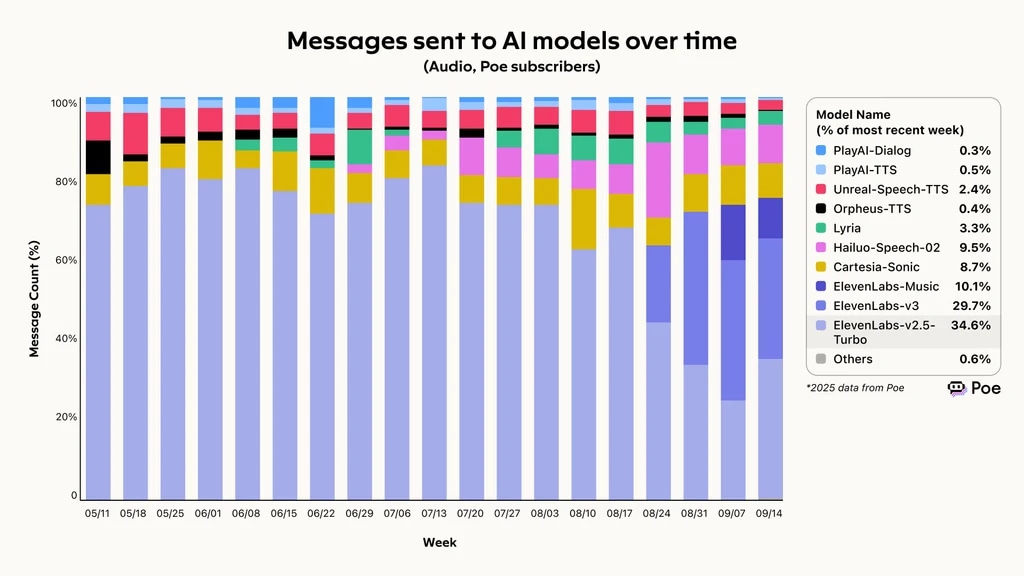
Wiadomości wysyłane do modeli AI w czasie (benchmark Poe)
Typowe błędy podczas testowania agentów głosowych
Testując agentów głosowych, łatwo skupić się na idealnych scenariuszach. W rzeczywistości klienci korzystają z twoich systemów AI w różnych warunkach.
Oto trzy typowe błędy i jak ich uniknąć:
- Testowanie najłatwiejszych przypadków: Wybierając nagrania do MOS, uwzględnij trudniejsze sytuacje. Klipy z szumem tła czy akcentem są bardzo częste, więc testowanie tylko na „czystym” audio zafałszuje wynik.
- Stawianie na zatrzymanie zamiast rozwiązania: Optymalizowanie modeli pod utrzymanie użytkownika w systemie zawyża wskaźnik zatrzymania, ale nie poprawia efektów. Jeśli FCR jest niski mimo wysokiego zatrzymania, agent wprowadza użytkownika w irytującą pętlę. Pozwól użytkownikowi połączyć się z człowiekiem, jeśli tego chce.
- Ignorowanie wysokich percentyli opóźnień: SLA często określa opóźnienia na poziomie P95. To ważne dla większości klientów, ale ostatnie 5% to też prawdziwi ludzie. Przy 10 000 rozmów dziennie to aż 500 osób z wolną obsługą. Skup się na P99 jako głównym celu SLA, nie tylko medianie czy P95.
Dzięki temu ustalisz rzetelne i reprezentatywne standardy, zamiast opierać się na wyidealizowanych średnich.
Dlaczego warto oceniać agentów pod kątem konkretnego zastosowania
Sześć filarów opisanych w tych ramach to dobry punkt wyjścia, ale ich waga zależy od branży. Np. firma finansowa postawi na zgodność i narzędzia, a marka konsumencka na jakość głosu TTS.
Oto dwa przykłady oceny agentów pod konkretne zastosowanie i jak zmieniają one wagę filarów.
Obsługa klienta
W niektórych branżach, np. w call center, ważne są dodatkowe metryki, jak First Call Resolution (FCR). Skuteczne obsłużenie zgłoszenia bez udziału człowieka mocno odciąża zespół wsparcia.Według McKinsey call center z agentami głosowymi mogą zmniejszyć liczbę interakcji nawet o 50%.
Choć TSR jest ważniejszy, warto też śledzić wskaźnik zatrzymania. Jeśli jest wysoki, a FCR niski, agent trzyma ludzi na linii bez rozwiązania sprawy – to frustrujące dla klienta.
Warto też mierzyć AHT – agenty AI powinny szybko rozwiązywać rutynowe sprawy. Dlatego w obsłudze klienta najważniejsza będzie jakość rozmowy, zwłaszcza zmiana ról i wskaźnik fallback.
Opieka zdrowotna
Opieka zdrowotna to branża mocno regulowana, z wysokimi wymaganiami dotyczącymi zgodności – obsługa agentów głosowych jest tu bardzo delikatna. Zgodność i zabezpieczenia są kluczowe, a waga filaru bezpieczeństwa i inteligencji jest tu największa.
Chatboty medyczne muszą obsługiwać rejestrację wizyt, teleporady, triaż objawów i pytania o ubezpieczenie. Wszystko to wymaga wysokiej inteligencji i korzystania z narzędzi, co pokazuje, że branża wpływa na to, który filar jest najważniejszy.
Niezależnie od branży, znajomość kluczowych filarów oceny agentów głosowych i ich zrównoważone stosowanie pomoże ci znaleźć najlepsze rozwiązanie.
Buduj z ElevenAgents – wysoka wydajność i niskie opóźnienia
Platforma, na której budujesz, bezpośrednio wpływa na to, jak agenty głosowe radzą sobie w prawdziwych workflow. Szczególnie w kontakcie z klientami musisz mieć pewność, że agent sprawdzi się w każdej kategorii.
ElevenAgents to rozwiązanie do wdrożeń produkcyjnych, łączące najlepszy TTS przez Eleven v3, STT w czasie rzeczywistym przez Scribe v2, oraz warstwę orkiestracji agentów stworzoną z myślą o dużej skali. Każdy element jest zoptymalizowany pod benchmarki z tych ram, więc możesz dostarczać klientom wysoką jakość.
Niezależnie, czy dopiero rozważasz opcje, czy chcesz zacząć budować – ElevenLabs ma dla ciebie rozwiązanie. Sprawdź platformę ElevenAgents i zobacz, jak pasuje do twojego zastosowania, albo załóż konto i zacznij budować już dziś.




