Eleven v3 오디오 태그란? 그리고 왜 중요한가
- 게시일
- 최종 업데이트
이제 Eleven v3 출시로 오디오 프롬프트가 필수 스킬이 되었습니다. AI 음성이 말할 내용을 직접 입력하거나 붙여넣는 대신, 이제 새로운 기능인 오디오 태그를 활용해 감정부터 전달 방식까지 모두 제어할 수 있습니다.
Eleven v3는 알파 버전의 연구 프리뷰 모델입니다. 이전 모델보다 더 많은 프롬프트 엔지니어링이 필요하지만, 생성 결과는 놀랍습니다.
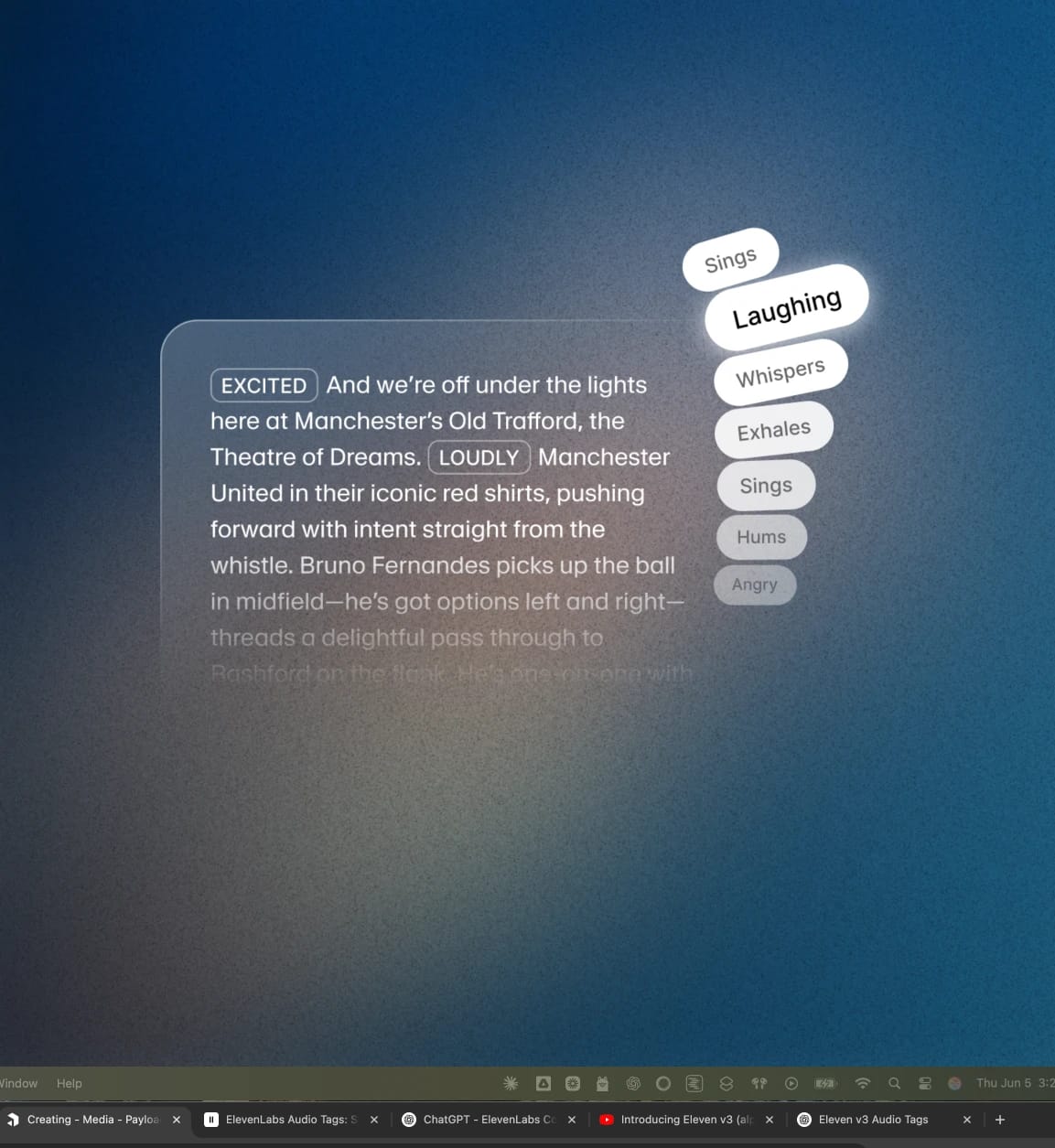
ElevenLabs 오디오 태그는 대괄호로 감싼 단어로, 새로운 Eleven v3 모델이 해석해 오디오 연출을 지시할 수 있습니다. 예를 들어 [excited], [whispers], [sighs]부터 [gunshot], [clapping], [explosion]까지 다양하게 사용할 수 있습니다.
오디오 태그를 사용하면 AI 음성의 톤, 멈춤, 속도 같은 비언어적 요소까지 자유롭게 조절할 수 있습니다. 몰입감 있는
오디오 태그로 연출하기
오디오 태그는 스크립트 어디에나 넣어 실시간으로 전달 방식을 바꿀 수 있습니다. 한 문장이나 스크립트 내에서 여러 태그를 조합해 사용할 수도 있습니다. 태그는 주요 카테고리로 나뉩니다:
감정
이 태그로 음성의 감정 톤을 설정할 수 있습니다. 예를 들어 [sad], [angry], [happily], [sorrowful] 등을 단독 또는 조합해 사용할 수 있습니다.


전달 방식
이 태그는 톤과 연기 스타일에 더 가깝습니다. 볼륨이나 에너지를 조절해 절제된 장면이나 강렬한 장면을 연출할 수 있습니다. 예시: [whispers], [shouts], [x accent] 등.


인간 반응
자연스러운 말에는 반응이 포함됩니다. 예를 들어, 자연스럽고 즉흥적인 순간을 추가해 현실감을 높일 수 있습니다. 예시: [laughs], [clears throat], [sighs].


더 표현력 있는 모델 기반
이 기능들의 기반에는 v3의 새로운 아키텍처가 있습니다. 이 모델은 텍스트의 맥락을 더 깊이 이해해 감정 신호, 톤 변화, 화자 전환까지 자연스럽게 따라갈 수 있습니다. 오디오 태그(Audio Tags)와 결합하면 이전보다 훨씬 더 풍부한 표현력이 가능해집니다
이제 다중 화자 대화도 자연스럽게 만들 수 있습니다. 최소한의 프롬프트로 끼어들기, 분위기 전환, 대화의 뉘앙스까지 구현할 수 있습니다.
지금 사용 가능
프로페셔널 음성 복제(PVC)는 현재 Eleven v3에 완전히 최적화되어 있지 않아 이전 모델에 비해 복제 품질이 다소 낮을 수 있습니다. 연구 프리뷰 단계에서는 Instant
Eleven v3는 ElevenLabs UI에서 사용할 수 있으며, 6월 말까지 80% 할인을 제공합니다. Eleven v3(알파)용 공개 API도 이용 가능합니다. 실험이든 대규모 적용이든, 지금이 새로운 가능성을 탐색할 기회입니다.
오디오 태그 만들기

AI 음성이 단순히 읽는 것을 넘어 연기하도록 하려면 오디오 태그를 잘 활용해야 합니다. 저희가 준비한 7가지 간단한 실전 가이드에서 [속삭임], [조용히 웃음], 또는 [프랑스어 억양]와 같은 태그로 맥락, 감정, 속도, 다중 캐릭터 대화까지 하나의 모델로 연출하는 방법을 확인할 수 있습니다.
가이드 시리즈 살펴보기
- 상황 인식 –
[속삭임],[소리침], 그리고[한숨]같은 태그로 Eleven v3가 상황에 맞게 반응합니다. 긴장감을 높이거나, 경고를 부드럽게 하거나, 서스펜스를 위해 멈추는 등 다양한 연출이 가능합니다. - 캐릭터 연기 –
[해적 목소리]부터[프랑스어 억양]까지, 태그 하나로 내레이션이 역할극으로 바뀝니다. 한 줄 안에서 캐릭터를 바꾸거나, 모델을 바꾸지 않고도 완벽한 캐릭터 연기를 연출할 수 있습니다. - 감정 맥락 –
[한숨],[신남], 또는[피곤함]같은 신호로 순간순간 감정을 조절해 긴장, 안도, 유머를 더할 수 있습니다. 재녹음 없이도 가능합니다. - 내러티브 인텔리전스 – 스토리텔링의 핵심은 타이밍입니다.
[잠시 멈춤],[감탄], 또는[극적인 톤]리듬과 강조를 조절해 - 다중 캐릭터 대화 –
[말 끊기],[겹쳐 말함]또는 톤 전환으로 겹치는 대사와 빠른 대화를 연출할 수 있습니다. 하나의 모델로 여러 목소리, 한 번에 자연스러운 대화가 가능합니다. - 전달 제어 – 속도와 강조를 세밀하게 조절하세요.
[잠시 멈춤],[급하게], 또는[길게 끎]같은 태그로 텍스트를 연기로 바꿀 수 있습니다. - 억양 에뮬레이션 – 지역 억양도 즉시 전환!
[미국식 억양],[영국식 억양],[미국 남부 억양]등 다양한 억양을 모델 교체 없이 구현해 문화적으로 풍부한 음성을 만들 수 있습니다.
.webp&w=3840&q=80)
.webp&w=3840&q=80)
