실시간 더빙을 향한 여정
- 게시일
- 최종 업데이트
일부에게 실시간 더빙은 '은하수를 여행하는 히치하이커를 위한 안내서'의 바벨피시를 떠올리게 합니다.
바벨피시는 '뇌파 에너지를 먹고, 무의식적인 주파수를 흡수해 의식적인 주파수로 변환하여 뇌의 언어 중추에 전달한다'고 합니다. 실제로는 귀에 바벨피시를 넣으면, 누가 어떤 언어로 말하든 즉시 내 모국어로 들리고, 원래의 음성은 전혀 들리지 않는다는 의미입니다.
아직 뇌파를 읽을 수는 없으니, 우리는 화자의 말을 듣고 목표 언어로 번역해야 합니다. 화자가 말을 할 때마다 단어별로 바로 번역하려고 하면 실제로 여러 어려움이 생깁니다.
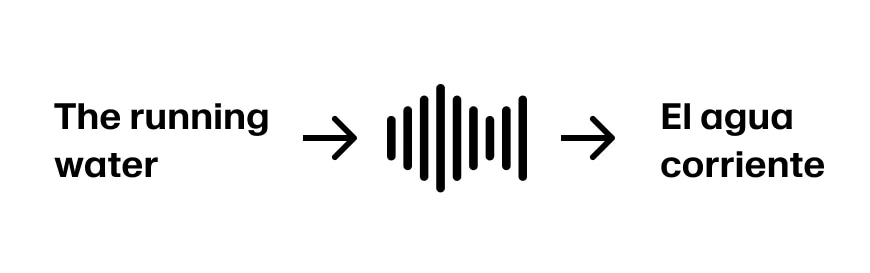
예를 들어 영어에서 스페인어로 번역한다고 가정해봅시다. 화자가 'The'라고 시작하면, 스페인어에서는 남성 명사에는 'El', 여성 명사에는 'La'를 사용합니다. 그래서 더 많은 정보를 듣기 전까지는 'The'를 확실히 번역할 수 없습니다.

화자가 계속해서 'The running water'라고 말하면, 이제 앞의 세 단어를 'El agua corriente'로 번역할 수 있습니다. 만약 문장이 'The running water is too cold for swimming'으로 이어진다면, 번역이 잘 맞아떨어집니다.
하지만 화자가 'The running water buffalo…'라고 계속 말하면, 다시 되돌아가야 합니다.
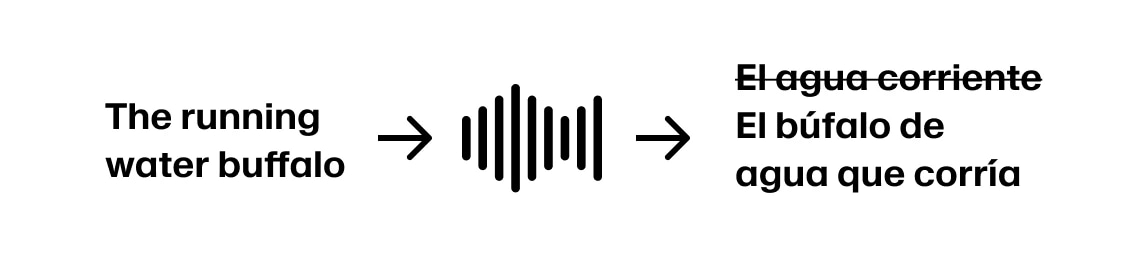
더 나아가, 화자가 'The running water buffalo protected her calf'라고 말한다면, 처음부터 'El búfalo'가 아니라 'La búfala'로 시작했어야 했습니다.
이런 “가든 패스(garden path)” 문장처럼, 처음에는 잘못 해석하기 쉬운 문장 구조는 여러 언어에 존재합니다.
일부 사용 사례에서는 너무 빠르게 더빙을 시작한 후에 다시 되돌아가야 할 수도 있다는 점을 감수할 수 있습니다. 반면, 더 정확성을 원한다면 지연 시간을 추가할 수도 있습니다. 모든

실시간 더빙의 최적 활용 사례
실시간 더빙이 가장 효과적으로 활용되는 상업적 사례는 다음과 같습니다.
- 글로벌 시청자가 있다
- 실시간 콘텐츠다
- 일정 수준의 방송 지연이 허용된다
스포츠
Forbes는 2019년에 NBA가 국제 TV 중계권으로 5억 달러를 벌고 있다고 보도했습니다. NFL은 미래의 핵심 수익원으로 국제 시장 확대를 보고 브라질, 영국, 독일, 멕시코에서 경기를 개최하고 있습니다.
대부분의 스포츠 경기는 실시간으로 시청하는 것이 일반적이지만, 실제로는 많은 사람들이 알게 모르게 어느 정도의 지연에 익숙합니다. 경기장에서 촬영된 영상이 집에서 화면에 도달하기까지 5초에서 몇 분까지 걸릴 수 있습니다.
보통 현장에는 여러 명의 카메라 및 음향 담당자가 있고, 이들이 촬영한 영상을 제작 시설로 전송합니다. 제작 시설에서는 카메라 화면을 전환하고, 오디오를 믹싱하며, 그래픽을 입히고, 해설을 추가합니다. 때로는 욕설이나 예상치 못한 내용을 걸러내기 위해 의도적으로 추가 지연을 두기도 합니다.
주요 제작 영상은 방송사로 전송되어, 방송사는 자체 브랜드와 광고를 추가한 뒤 각 지역 네트워크로 콘텐츠를 배포합니다. 마지막으로, 케이블, 위성, 스트리밍 서비스를 통해 시청자에게 전달됩니다.

많은 제작자들은 더빙을 위해 최대 20초까지 추가 지연을 허용할 수 있다고 말합니다. 추가 지연이 있더라도 시청자가 모국어로 들을 수 있다는 점이 충분히 보상된다고 생각합니다.
스포츠 업계는 무엇보다도 고품질의 콘텐츠 제공을 중요하게 여기며, 그 핵심은 방송인의 감정과 타이밍을 효과적으로 전달하는 것이라고 믿습니다. '슛! 골인!' 같은 순간은 반드시 열정적으로 전달되어야 합니다.
저희 더빙 서비스의 기반이 되는 음성 복제 모델은 원래 화자의 감정과 전달 방식을 잘 포착할 수 있습니다. 번역과 달리, 더 많은 맥락이 항상 더 나은 결과로 이어지지는 않습니다. 하지만 아직 스페인 축구 해설자만큼의 감정 표현에는 도달하지 못했습니다!
각 음성 복제는 입력된 음성의 평균값을 냅니다. 예를 들어, '남은 2분밖에 없으니 더 공격적으로 나가야 합니다.'처럼 평이한 문장과 '슛! 골인!'처럼 감정이 실린 문장을 합치면, 결과물은 두 문장의 평균적인 전달 방식이 됩니다.

오늘날 우리는 텍스트 번역보다
뉴스 방송
‘실시간’ 스포츠처럼, 뉴스 방송도 제작 과정을 거치며 지연이 발생합니다. 미디어 기업들과의 대화에 따르면, 감정 전달도 중요하지만 대부분의 뉴스 앵커는 전달 방식이 매우 일정하기 때문에 상대적으로 쉽고, 오히려 정확하고 미묘한 번역이 가장 중요하다고 합니다.
자동 번역 서비스에 오류가 발생할 가능성 외에도, 어떤 개념은 직접적으로 번역할 수 없는 경우가 있습니다. 예를 들어:
"공동체가 추모의 날에 모여, 생존자들이 자신의 이야기를 나누고 어르신들이 치유를 위한 전통 기도를 올렸습니다."
스페인어: "La comunidad se reunió para un día conmemorativo, donde los sobrevivientes compartieron sus historias y los ancianos realizaron oraciones tradicionales para la sanación."
기술적으로는 정확하지만, 영어의 'survivors'와 스페인어의 'sobrevivientes'는 역사적 트라우마 맥락에서 의미가 다를 수 있습니다. 영어에서는 회복력과 존엄성을 내포하는 반면, 스페인어는 피해자성을 강조할 수 있습니다. 또한 'performed prayers'와 'realizaron oraciones'도 경건함의 뉘앙스가 다릅니다. 'performed'는 의식의 의미를 담지만, 'realizaron'은 더 절차적으로 들릴 수 있습니다.
보너스 - 대화형 더빙을 향한 여정
서로 다른 언어를 쓰는 사람들이 자연스럽게 대면 대화를 하려면 거의 즉각적인 번역이 필요합니다.
LLM의 다음 토큰 예측 확률을 활용하면, 문장이 어디로 이어질지 실시간으로 예측할 수 있습니다.

이미지 출처 - Hugging Face "How to generate text"
이 다음 토큰 예측 모델을 특정 화자에 맞게 파인튜닝하면, 그 사람이 다음에 무슨 말을 할지 어느 정도 예측할 수 있습니다. 이 정보를 활용해, 화자가 어디로 이어갈지 확신이 높을 때 번역과 음성 생성을 미리 진행하는 '치팅'이 가능합니다.
이 내용이 흥미롭고 AI 오디오의 미래를 함께 만들어가고 싶으신가요? 여기에서 채용 공고 확인하기.




