Framework di valutazione degli agenti vocali: spiegati i 6 pilastri
- Scritto da
- Jack Limebear
- Pubblicato
- Ultimo aggiornamento
AscoltaAscolta questo articolo
Gli agenti vocali devono coordinare una serie di strumenti quasi simultanei. È un equilibrio delicato tra registrare i commenti del cliente in tempo reale con
Con così tante componenti in gioco, come puoi valutare con precisione le prestazioni di un agente vocale?
In questo articolo ti proponiamo un framework di valutazione degli agenti vocali basato su sei pilastri, che spiega cosa misurare per valutare il successo di un agente. Vedremo anche perché settori diversi dovrebbero dare peso diverso a questi pilastri e quali sono gli errori più comuni da evitare durante la valutazione.
Riepilogo
- I sei principali pilastri da considerare nella valutazione di un agente vocale sono: qualità della voce TTS, qualità della conversazione, uso degli strumenti e completamento dei task, intelligenza, conformità e sicurezza, affidabilità.
- Gli obiettivi di produzione più importanti sono un MOS di 4,3, un TSR superiore all’85% e un time-to-first audio inferiore a 500ms.
- Ogni settore darà peso diverso a ciascun pilastro, con alcune implementazioni che privilegiano uno rispetto agli altri.
- Gli errori più comuni nei test includono valutare solo audio puliti e ignorare i picchi di latenza P99.
- ElevenLabs è leader nelle metriche che contano davvero: Scribe v2 raggiunge il WER più basso del settore con il 2,2% (Artificial Analysis, giugno 2026), Flash v2.5 e Turbo v2.5 sono i modelli più veloci (Artificial Analysis, giugno 2026) e ElevenAgents offre una latenza di inferenza modello di circa 75ms.
Cos’è un framework di valutazione degli agenti vocali?
Un framework di valutazione degli agenti vocali IA è un sistema strutturato che ti permette di testare le prestazioni su più dimensioni. Un framework completo include metriche per valutare tutto, dalla fedeltà audio al flusso della conversazione, fino alla conformità normativa.
A differenza di un chatbot testuale, un agente vocale gestisce ogni interazione tramite almeno tre tecnologie sovrapposte: il riconoscimento vocale automatico (ASR), che trasforma le parole dell’utente in testo; un LLM che genera la risposta; e un sistema TTS che converte la risposta in audio. Se anche solo uno di questi sistemi fallisce, l’esperienza complessiva ne risente.
Questa complessità è proprio il motivo per cui le aziende devono valutare gli agenti vocali prima di scegliere un fornitore e avviare la distribuzione. Qualsiasi latenza aggiuntiva o risposta imprecisa può avere conseguenze reali, come la perdita di clienti o, nei casi peggiori, sanzioni e danni reputazionali.
Un framework di valutazione degli agenti vocali utilizza benchmark e dati misurabili per definire se un agente è adatto a determinati casi d’uso. Dal punto di vista aziendale, poter valutare diversi modelli vocali ti permette di scegliere quello migliore per i tuoi clienti.
I sei pilastri da valutare per gli agenti vocali
Anche se creare e distribuire un agente IA non è mai stato così semplice, i processi attivi dietro le quinte sono piuttosto complessi. Diversi componenti lavorano insieme per ascoltare l’utente, capire cosa vuole, trasmettere l’informazione a un LLM e produrre una risposta audio: molte azioni avvengono quasi in contemporanea.
Per scegliere il miglior agente vocale possibile, le aziende hanno bisogno di un framework rigoroso a cui fare riferimento.
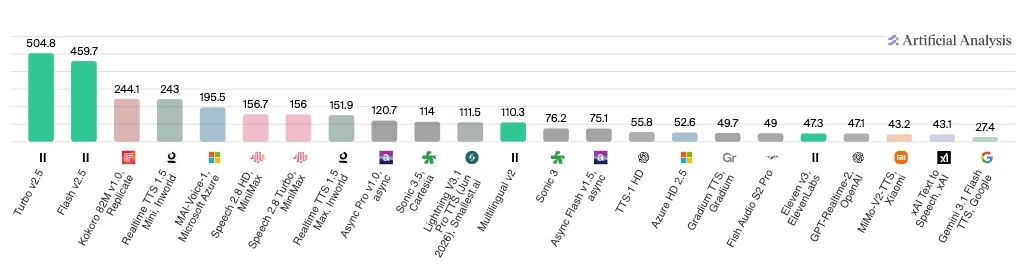
Se ti interessa vedere i risultati dei test, Analisi artificiale offre diversi confronti tra agenti basati su varie componenti. Qui sotto puoi vedere i risultati del confronto sulla velocità tra modelli, con ElevenLabs Turbo v2.5 e Flash v2.5 nettamente in testa per caratteri elaborati al secondo.
Per sviluppatori o aziende che vogliono condurre i propri test, ecco i sei pilastri di un framework di valutazione degli agenti IA da utilizzare:
- Qualità della voce TTS: Quanto la voce sintetizzata risulta naturale, chiara ed espressiva per l’utente finale. I migliori modelli del settore, come Eleven v3, offrono una resa umana ed emotiva in oltre 70 lingue.
- Qualità della conversazione: Il modello comprende il parlato umano, interpreta il significato e risponde in modo contestuale e rapido su più turni?
- Uso degli strumenti: Quanto un agente IA riesce a completare task utilizzando le risorse disponibili senza bisogno di intervento umano.
- Intelligenza: Quanto il modello ragiona, gestisce input nuovi ed evita di produrre risposte imprecise o allucinate.
- Conformità e sicurezza: Oltre a tutte le funzionalità,
- Affidabilità: Componenti come uptime totale e prestazioni costanti sotto carico per capire se un agente conversazionale IA può scalare con la domanda.
Anche se ogni pilastro è indipendente, sono tutti collegati per offrire un’esperienza finale di alta qualità all’utente. Ad esempio, se un modello migliora la qualità della voce ma mantiene una latenza elevata, il cliente si troverà ad aspettare in modo innaturale prima di sentire la risposta.
Vediamo più da vicino ciascuno di questi pilastri di valutazione della voce IA.
Qualità della voce TTS
Partiamo dalla qualità della voce, perché è probabilmente la prima cosa che una persona nota quando interagisce con un agente conversazionale IA. Se la voce suona robotica o innaturale, l’esperienza soggettiva sarà molto meno piacevole.
Una delle metriche di valutazione originali, definita dall’International Telecommunication Union Telecommunication Standard Sector (ITU-T), è il Mean Opinion Score (MOS). Il MOS va da 1 a 5, dove 1 è inutilizzabile e 5 è eccellente. Essendo una misura soggettiva, si basa su ascoltatori umani che danno un feedback dopo una chiamata.
Un punteggio MOS inferiore a 3,5 è poco soddisfacente, soprattutto secondo gli standard attuali, e probabilmente influirà sulla soddisfazione del cliente.
Anche se il MOS è una metrica centrata sull’ascoltatore umano, diversi requisiti tecnici contribuiscono a questo valore:
- Coerenza dell’intonazione e jitter: Intonazione e jitter sono due elementi linguistici che le persone percepiscono naturalmente mentre ascoltano. L’“intonazione” riguarda le variazioni naturali della voce, come quando alzi la voce per fare una domanda. Il jitter si verifica quando il modello vocale non mantiene una prosodia coerente all’interno di una frase. Il valore di riferimento per il jitter nel settore è 30ms.
- Espressività emotiva: Una voce chiara e precisa suona comunque sbagliata se il tono non corrisponde all’emozione della frase. Senza segnali tonali accurati, gli ascoltatori umani avranno meno empatia verso gli agenti conversazionali IA e li valuteranno peggio. ElevenAgents offre espressività quasi umana per abbinare ogni risposta a un’intenzione emotiva chiara.
- Rumore di fondo: Il rumore di fondo negli agenti vocali ha due aspetti distinti da valutare. In uscita, un leggero rumore ambientale viene aggiunto per rendere la voce più naturale. In ingresso, il filtro del rumore sul livello STT è un’opzione che migliora la precisione. Quando valuti un agente, testa entrambi: ascolta se il rumore ambientale suona naturale e verifica la precisione dello STT con il filtro attivo e disattivo.
Quando calcoli il MOS, punta a un valore tra 4,3 e 4,5, che indica punteggi elevati in tutte queste categorie percettive. Per la previsione del MOS su larga scala senza pannelli umani, puoi usare strumenti come UTMOS e NISQA.
Qualità della conversazione
La qualità della conversazione è un pilastro composito tra la qualità della voce e il completamento dei task. Serve a misurare quanto efficacemente un agente vocale comprende le esigenze dell’utente, lo interrompe in modo contestuale e porta avanti un dialogo multi-turno fino alla conclusione.
La metrica principale qui è la precisione nella classificazione dell’intento, che di solito varia tra l’85% e il 92%, con i migliori che arrivano anche al 96%. Anche se l’85% sembra alto, significa comunque che il 15% delle richieste viene classificato male e indirizzato alle risorse sbagliate.
Gli elementi tecnici che contribuiscono a una classificazione accurata dell’intento sono:
- Gestione dei turni: La gestione dei turni valuta quanto bene un agente vocale gestisce il flusso naturale della conversazione. Serve a capire quando ascoltare, rispondere o attendere altri input. Include anche la gestione delle interruzioni (barge-in), dove il modello interrompe una risposta in corso e ne genera una nuova in base al nuovo input. ElevenLabs utilizza un websocket multi-contesto per gestire queste interruzioni in modo fluido.
- Latenza: La latenza indica il tempo che passa tra la fine della frase dell’utente e l’inizio della risposta audio dell’agente. Gli agenti vocali pronti per la produzione dovrebbero puntare a un time-to-first audio inferiore a 500ms, con valori sotto i 300ms considerati eccellenti. I modelli Flash di ElevenLabs offrono tempi di inferenza di circa 75ms, tra i migliori del settore.
- Tasso di fallback: Il tasso di fallback misura quante volte un agente IA non capisce l’utente e chiede una chiarificazione o una ripetizione. Dipende molto dalla precisione dello STT: se il livello di riconoscimento vocale interpreta male ciò che dice il cliente, il LLM riceve un input errato. Il tasso di fallback si calcola così: Tasso di fallback (%) = (Numero di fallback / Numero totale di interazioni) * 100.
ElevenLabs Scribe V2 ha il WER più basso: 2,2% nella valutazione dei modelli speech to text di Artificial Analysis
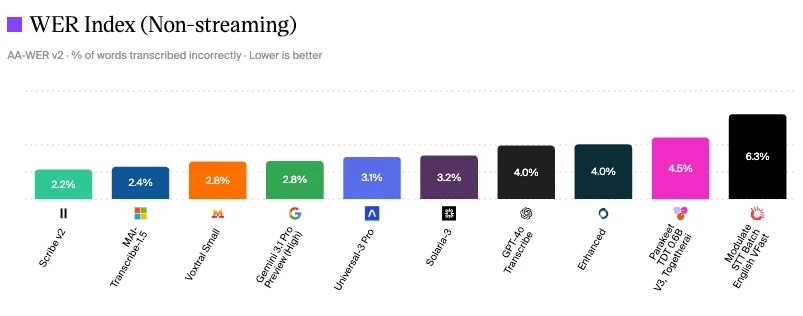
Valutazione dei modelli speech to text di Artificial Analysis
Un modo per misurare la qualità della conversazione è guardare agli standard di benchmark del settore per le diverse componenti. Come puoi vedere, Scribe v2 di ElevenLabs ha il Word Error Rate più basso, 2,2% a giugno 2026: significa meno errori di ascolto, meno fallback e classificazione dell’intento più precisa.
Le aziende possono notare che la qualità della conversazione dipende anche dal workflow in cui opera l’agente vocale. Ad esempio, nell’assistenza clienti, un altro aspetto da considerare è la qualità del passaggio all’operatore umano o la risoluzione delle FAQ.
Uso degli strumenti e completamento dei task
Se la qualità misura come si è svolta la conversazione, il completamento dei task valuta se si è arrivati a un risultato concreto. Le aziende dovrebbero prestare molta attenzione a questa parte del framework, perché è direttamente collegata agli obiettivi di business.
Una metrica per l’uso degli strumenti è la precisione nel riempimento degli slot, che indica quanto bene gli agenti IA riescono a completare task di routine, come compilare un modulo con i dati del cliente. Un’alta precisione dimostra che l’agente passa senza problemi dalla conversazione all’azione senza perdere informazioni.
Il Task Success Rate (TSR) è una misura percentuale dei task completati con successo da un agente. Il completamento si basa sulla capacità dell’agente di capire la richiesta e usare gli strumenti collegati (API, database, Retrieval-Augmented Generation (RAG), knowledge base interne) per fornire assistenza.
La formula per il TSR è:
TSR = (Task completati / Task totali tentati) x 100
Gli agenti vocali pronti per la produzione dovrebbero puntare a un TSR superiore all’85%, monitorando la precisione e l’affidabilità delle chiamate agli strumenti. Per evitare cali nel TSR, assicurati di fare regression test dopo ogni modifica ai prompt o ai modelli collegati: anche una piccola variazione può avere un impatto significativo.
Intelligenza
L’intelligenza riguarda le capacità di ragionamento e di livello superiore di un agente vocale. È il pilastro che distingue chiaramente un IVR tradizionale da un agente vocale IA.
Le dimensioni chiave da valutare qui sono:
- Rischio di allucinazione: Le allucinazioni, cioè quando un agente produce informazioni inesatte o incoerenti con i documenti aziendali, sono particolarmente dannose nella voce IA perché possono essere pronunciate con sicurezza.Studi recenti suggeriscono che le allucinazioni comuni danneggiano in modo significativo la soddisfazione dei clienti verso gli agenti vocali.
- Gestione delle richieste fuori ambito: Gli agenti intelligenti capiscono quando una domanda è fuori dal loro dominio e rispondono in modo appropriato. Invece di inventare una risposta, rifiutano o riportano la conversazione su un terreno contestuale.
- Mantenimento del contesto: Su più turni, l’agente riesce a tenere traccia di entità e impegni presi in precedenza? Senza questa capacità, i clienti potrebbero dover ripetere le informazioni o ricevere risposte contraddittorie.
- Ragionamento e logica multi-step: L’agente riesce a gestire correttamente logiche condizionali o concatenare inferenze su più turni? Soprattutto nei casi d’uso tecnici, come nei servizi finanziari, la capacità di ragionare in un contesto predefinito è essenziale.
Esistono diversi benchmark di terze parti per queste dimensioni e componenti. Ad esempio, lo Stanford Holistic Evaluation of Language Models (HELM) valuta le prestazioni degli LLM in varie categorie. Per le allucinazioni, TruthfulQA offre un’analisi robusta della frequenza delle risposte false.
Uno dei vantaggi di ElevenAgents è che, a differenza di alcune piattaforme vocali che ti vincolano a un solo modello, puoi sostituire completamente il layer LLM. In pratica, puoi collegare il modello che ottiene i migliori risultati nei benchmark di ragionamento per il tuo caso d’uso.
Conformità e sicurezza
Le aziende devono implementare guardrail attivi per prevenire output dannosi o che violano le policy. A differenza delle istruzioni di sistema, che possono essere aggirate, i controlli indipendenti funzionano come un layer separato dal modello. Questi valutano gli output prima che arrivino all’utente e bloccano la conversazione se si entra in territori rischiosi.
L’auditabilità è un requisito correlato: gli agenti in produzione devono mantenere log dettagliati di decisioni e output in un formato che consenta la revisione successiva. Soprattutto nei settori regolamentati, dimostrare la conformità a posteriori è importante quanto raggiungerla in tempo reale.
Le normative a cui la tua azienda deve adeguarsi variano in base al settore. Alcuni dei framework più comuni sono:
- HIPAA: Per i dati sanitari protetti negli Stati Uniti.
- PCI-DSS: Per agenti che gestiscono dati di carte di pagamento.
- GDPR: Obblighi di privacy dei dati per l’UE e le aziende con clienti nell’UE.
Per le aziende che valutano la propria conformità, ElevenLabs è conforme a AICPA SOC Type II e GDPR, oltre ad aver ottenuto la certificazione AIUC-1. L’AIUC-1 è uno standard di sicurezza pensato specificamente per gli agenti IA.
Affidabilità
L’affidabilità è l’ultimo pilastro del nostro framework di valutazione degli agenti vocali e riguarda la capacità di un agente di offrire prestazioni costanti in tempo reale.
Quando valuti un agente vocale, cerca queste caratteristiche:
- Uptime: Ogni distribuzione rivolta ai clienti si aspetta un uptime del 99,9% per evitare interruzioni. Soprattutto per i casi d’uso always-on, come il supporto inbound, l’affidabilità è fondamentale.
- Degrado controllato: Vista la complessità degli agenti vocali, se una componente inizia a fallire, l’agente dovrebbe gestire il degrado in modo controllato. In pratica, significa passare la conversazione a un umano invece di continuare a funzionare con errori o sotto stress.
- Prestazioni sotto carico:I test di carico dovrebbero simulare almeno il doppio della tua massima concorrenza prevista prima del go-live. Testare sotto forte pressione aiuta a individuare aumenti di latenza o cali di prestazioni che emergono solo su larga scala.
Anche un modello di alta qualità che soddisfa tutti gli altri criteri può essere inutilizzabile se non scala con la domanda dei clienti. ElevenAgents è scelto da oltre 1.000.000 tra creator e aziende leader, a dimostrazione della capacità della piattaforma di fornire deployment su scala enterprise senza compromettere le prestazioni.
Come misurare il MOS per gli agenti vocali (step by step)
Se vuoi misurare il MOS manualmente, ti servirà un ampio gruppo di ascoltatori umani e una selezione di clip audio da conversazioni reali. È un processo strutturato che prevede la raccolta dei feedback, la media e l’interpretazione dei dati.
Ecco come misurare il MOS per gli agenti vocali nella pratica:
- Prepara il set di test: Seleziona un campione rappresentativo di output audio del tuo agente, con almeno 100 clip su conversazioni diverse.
- Esegui la sessione di valutazione: Chiedi agli ascoltatori umani di valutare ciascuna clip su una scala da 1 a 5 in base alla qualità dell’esperienza di comunicazione.
- Aggrega i punteggi e calcola il risultato: Fai la media dei punteggi per ogni clip, poi la media di tutte le clip per ottenere il MOS complessivo. Un MOS di 4,3 o superiore indica che il tuo agente vocale è pronto per la produzione.
Anche se questo processo è manuale e impegnativo, ti darà un MOS solido per l’agente scelto. Se vuoi testare su larga scala, puoi sostituire gli ascoltatori umani con strumenti automatici come NISQA, che prevedono i punteggi MOS in modo programmato. Puoi integrare questi sistemi nei tuoi workflow per monitorare continuamente il MOS nel tempo.
Benchmark IA vs. umani: FCR, AHT e CSAT
Calcolare il MOS nel tempo è utile per vedere miglioramenti o regressioni del modello, ma puoi aggiungere contesto confrontando i risultati con le prestazioni umane. Vedere cosa ottengono gli umani in ruoli simili ti aiuta a capire se il tuo agente vocale si avvicina al livello ideale.
Ecco alcune metriche da considerare per i benchmark IA vs. umani.
Gli agenti IA dovrebbero raggiungere FCR e CSAT simili agli umani, migliorando però notevolmente l’AHT. Questo perché gli agenti IA gestiscono spesso conversazioni più generali rispetto agli operatori umani. Molte aziende adottano un workflow in cui gli agenti IA sono i primi a rispondere, passando la chiamata agli umani solo se troppo complessa per essere gestita in autonomia.
I dati 2025 di Poe, aggregatore di confronto IA, mostrano che ElevenLabs ha mantenuto la capacità più alta di soddisfare le richieste, completando il 74,4% di tutte le richieste in ingresso. Questo successo si riflette in una crescita rapida dell’utilizzo, con Eleven v3 e v2.5-Turbo che rappresentano oltre il 60% dei messaggi inviati ai modelli IA nel tempo.
Messaggi inviati ai modelli IA nel tempo, ElevenLabs guida il framework di valutazione degli agenti vocali secondo Poe
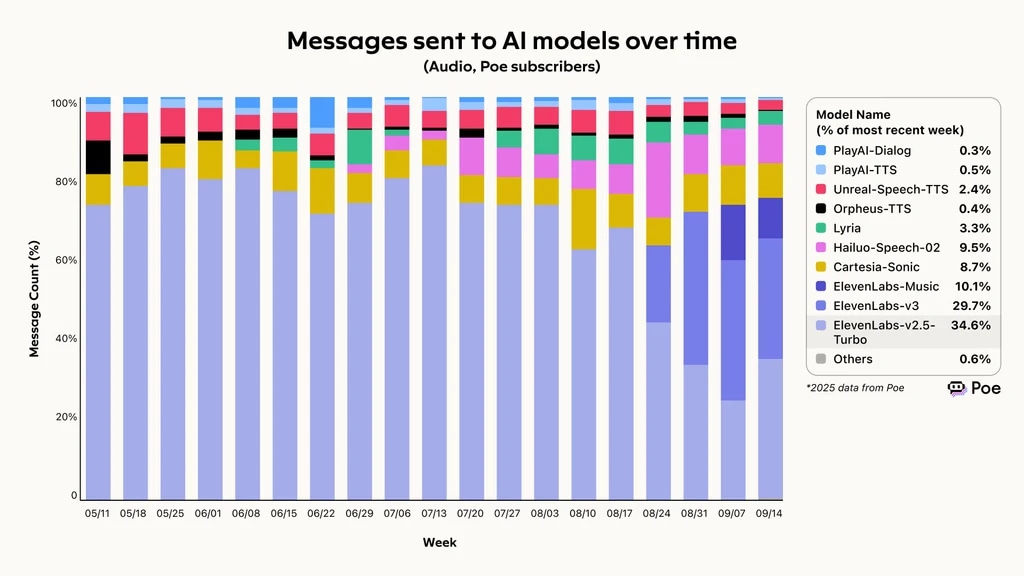
Messaggi inviati ai modelli IA nel tempo, benchmark Poe
Errori comuni nei test degli agenti vocali
Seguendo un framework di valutazione degli agenti vocali, è facile testare solo gli scenari migliori. In realtà, l’esperienza quotidiana dei clienti con i tuoi sistemi vocali IA non avverrà in condizioni ideali.
Ecco tre errori comuni nei test degli agenti vocali e come evitarli:
- Testare solo i casi più semplici: Soprattutto quando scegli le clip audio per il MOS, includi anche casi limite. Clip con rumore di fondo o accenti sono molto comuni nella realtà, quindi testare solo su file “puliti” porta a un MOS poco rappresentativo.
- Dare priorità al contenimento invece che alla risoluzione: Ottimizzare i modelli per trattenere gli utenti nel sistema aumenta il tasso di contenimento senza migliorare i risultati. Se il tuo FCR è basso nonostante un alto contenimento, l’agente sta facendo girare gli utenti in tondo. Prevedi la possibilità di parlare con un operatore umano se richiesto.
- Ignorare i percentili di latenza: Le SLA spesso indicano la latenza al livello P95. Anche se questa metrica è importante per offrire un’esperienza coerente alla maggior parte dei clienti, non dimenticare che anche il 5% finale sono clienti reali. Su larga scala, il 5% di un sistema che gestisce 10.000 chiamate al giorno sono comunque 500 persone che vivono una conversazione lenta. Punta al P99 come obiettivo SLA principale, non solo alla mediana o al P95.
Tenendo a mente questi aspetti, puoi stabilire baseline eque e rappresentative invece di basarti su medie idealizzate.
L’importanza delle valutazioni specifiche per caso d’uso
Anche se i sei pilastri di questo framework ti guidano sulle aree da esplorare, il peso di ciascun pilastro dipende dal settore. Ad esempio, un’azienda nei servizi finanziari darà priorità a conformità e uso degli strumenti, mentre un brand consumer punterà soprattutto sulla qualità della voce TTS.
Ecco due esempi di valutazioni specifiche per caso d’uso e come possono cambiare l’equilibrio tra i pilastri.
Assistenza clienti
In alcuni settori, come i call center, altre metriche di completamento come la First Call Resolution (FCR) sono fondamentali. Gestire con successo una chiamata senza intervento umano riduce notevolmente il carico sugli operatori.Secondo McKinsey i call center che usano agenti vocali possono ridurre il volume delle interazioni fino al 50%.
Anche se meno importante del tasso di successo dei task, un’altra dimensione da considerare è il tasso di contenimento, che misura la durata totale della chiamata. Se il tasso di contenimento è molto alto ma il FCR è basso, gli agenti tengono le persone in linea senza risolvere il problema: in pratica, un’esperienza frustrante per il cliente.
Altre metriche da monitorare sono l’AHT, con gli agenti IA che puntano a risolvere rapidamente i problemi di routine. Per questo, l’assistenza clienti darà priorità alla qualità della conversazione, soprattutto nella gestione dei turni e nel tasso di fallback.
Sanità
Sanità è un settore altamente regolamentato, con requisiti di conformità stringenti che rendono l’uso degli agenti vocali molto delicato. La conformità è centrale, spostando il peso del pilastro sicurezza e intelligenza sopra ogni altro.
I chatbot per la sanità devono gestire prenotazioni, accesso alla telemedicina, triage dei sintomi e domande sulle assicurazioni. Tutto ciò richiede un alto livello di intelligenza e uso degli strumenti, a conferma che le esigenze di settore o ruolo influenzano quale pilastro è più importante.
Qualunque sia il settore in cui opera la tua azienda, comprendere i pilastri fondamentali della valutazione degli agenti vocali e applicarli in modo bilanciato ti aiuterà a trovare gli agenti migliori per te.
Costruisci con ElevenAgents per alte prestazioni e bassa latenza
La piattaforma su cui costruisci influisce direttamente sulle prestazioni dei tuoi agenti vocali nei workflow reali. Soprattutto quando interagisci con i clienti, devi essere sicuro che il tuo agente eccella in ogni categoria.
ElevenAgents è pensato per deployment vocali in produzione, combinando TTS di livello top tramite Eleven v3, STT in tempo reale con Scribe v2, e un layer di orchestrazione agenti progettato per la scala enterprise. Ogni componente è costruito per raggiungere i benchmark di questo framework, così puoi offrire esperienze di alta qualità ai tuoi clienti.
Che tu stia valutando le opzioni o sia pronto a iniziare, ElevenLabs ha la soluzione per te. Esplora la piattaforma ElevenAgents per vedere come si adatta al tuo caso d’uso, oppure registrati e inizia a costruire oggi stesso.



.webp&w=3840&q=80)
