Cómo hicimos que RAG fuera un 50% más rápido
- Escrito por
- Michal Korbela
- Publicado
- Última actualización
EscucharEscucha este artículo
RAG mejora la precisión de los agentes de IA al basar las respuestas de LLM en grandes bases de conocimiento. En lugar de enviar toda la base de conocimiento al LLM, RAG incrusta la consulta, recupera la información más relevante y la pasa como contexto al modelo. En nuestro sistema, añadimos primero un paso de reescritura de consultas, colapsando el historial de diálogo en una consulta precisa y autónoma antes de la recuperación.
Para bases de conocimiento muy pequeñas, puede ser más sencillo pasar todo directamente al prompt. Pero una vez que la base de conocimiento crece, RAG se vuelve esencial para mantener las respuestas precisas sin sobrecargar el modelo.
Muchos sistemas tratan a RAG como una herramienta externa, sin embargo, lo hemos integrado directamente en la canalización de solicitudes para que se ejecute en cada consulta. Esto asegura una precisión constante pero también crea un riesgo de latencia.
Por qué la reescritura de consultas nos ralentizó
La mayoría de las solicitudes de los usuarios hacen referencia a turnos anteriores, por lo que el sistema necesita colapsar el historial de diálogo en una consulta precisa y autónoma.
Por ejemplo:
- Si el usuario pregunta:“¿Podemos personalizar esos límites según nuestros patrones de tráfico máximo?"
- El sistema lo reescribe como:“¿Se pueden personalizar los límites de tasa de la API del plan Enterprise para patrones de tráfico específicos?”
La reescritura convierte referencias vagas como “esos límites” en consultas autónomas que los sistemas de recuperación pueden usar, mejorando el contexto y la precisión de la respuesta final. Pero depender de un único LLM alojado externamente creó una fuerte dependencia de su velocidad y tiempo de actividad. Este paso por sí solo representaba más del 80% de la latencia de RAG.
Cómo lo solucionamos con model racing
Rediseñamos la reescritura de consultas para que se ejecute como una carrera:
- Múltiples modelos en paralelo. Cada consulta se envía a múltiples modelos a la vez, incluidos nuestros modelos Qwen 3-4B y 3-30B-A3B autoalojados. La primera respuesta válida gana.
- Alternativas que mantienen la conversación fluida. Si ningún modelo responde en un segundo, recurrimos al mensaje original del usuario. Puede ser menos preciso, pero evita bloqueos y asegura continuidad.
.webp&w=3840&q=95)
El impacto en el rendimiento
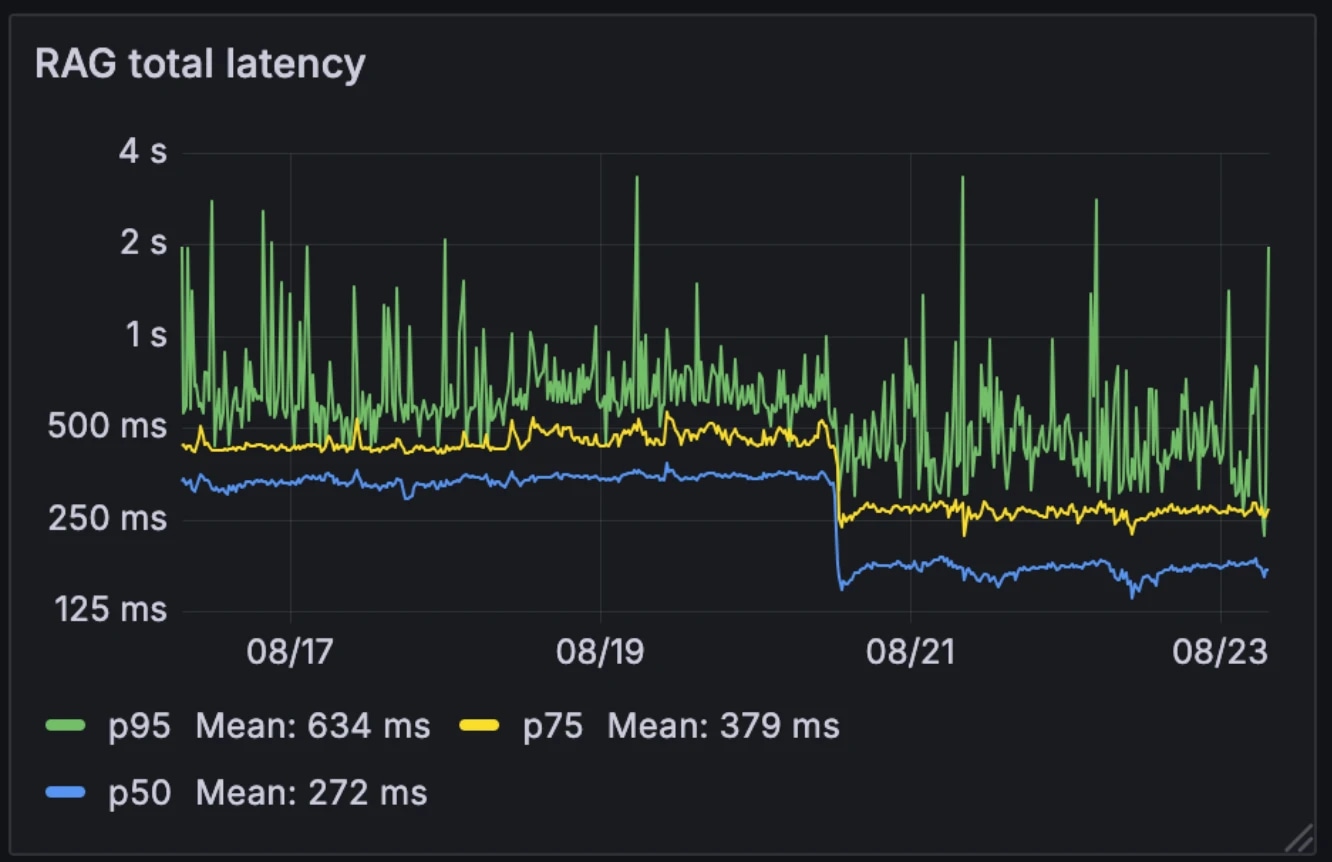
Esta nueva arquitectura redujo la latencia media de RAG a la mitad, de 326ms a 155ms. A diferencia de muchos sistemas que activan RAG selectivamente como una herramienta externa, lo ejecutamos en cada consulta. Con una latencia media reducida a 155ms, el costo adicional de hacerlo es insignificante.
Latencia antes y después:
- Media: 326ms → 155ms
- p75: 436ms → 250ms
- p95: 629ms → 426ms
La arquitectura también hizo que el sistema fuera más resistente a la variabilidad de los modelos. Mientras que los modelos alojados externamente pueden ralentizarse durante las horas de mayor demanda, nuestros modelos internos se mantienen relativamente consistentes. La carrera de modelos suaviza esta variabilidad, convirtiendo el rendimiento impredecible de modelos individuales en un comportamiento del sistema más estable.
Por ejemplo, cuando uno de nuestros proveedores de LLM experimentó una interrupción el mes pasado, las conversaciones continuaron sin problemas en nuestros modelos autoalojados. Dado que ya operamos esta infraestructura para otros servicios, el costo adicional de computación es insignificante.
Por qué es importante
La reescritura de consultas RAG por debajo de 200ms elimina un gran cuello de botella para los agentes conversacionales. El resultado es un sistema que sigue siendo consciente del contexto y en tiempo real, incluso cuando opera sobre grandes bases de conocimiento empresariales. Con la sobrecarga de recuperación reducida a niveles casi insignificantes, los agentes conversacionales pueden escalar sin comprometer el rendimiento.



.webp&w=3840&q=80)
