实时配音之路
- 发布时间
- 最近更新
对一些人来说,实时配音让人联想到《银河系漫游指南》里的巴别鱼。
巴别鱼“以脑电波为食,吸收无意识频率,并将有意识频率传递到大脑的语言中枢”。实际效果就是,只要把它放进耳朵里,无论别人用什么语言说话,你都能立刻听到自己的母语(完全听不到原音)。
在我们能读取脑电波之前,还需要先听清说话内容,再翻译成目标语言。试图边说边翻译每个词,会遇到不少实际难题。
比如你想把英语翻译成西班牙语。说话人刚说了“The”。在西班牙语中,“The”要根据后面词的性别选“El”或“La”。所以没听到更多内容前,无法确定怎么翻译。

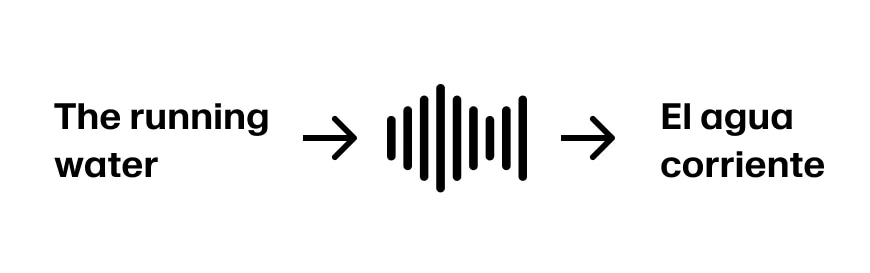
假如说话人继续说“The running water”,这时就可以把前三个词翻译成“El agua corriente”。如果句子继续是“The running water is too cold for swimming”,那就没问题。
但如果说话人接着说“The running water buffalo...”,就需要回头修改翻译。
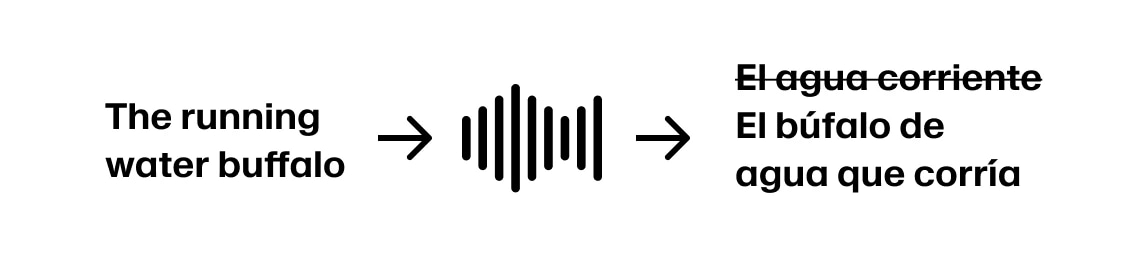
再进一步,如果说的是“The running water buffalo protected her calf”,其实句首应该用“La búfala”而不是“El búfalo”。
这些“花园小径”句子,也就是开头让听众误解意思的句子,在很多语言中都存在。
在某些场景下,可能会接受因配音过快而需要回退的情况。对于其他场景,可以选择增加延迟以提升准确性。由于所有配音场景都不可避免存在一定延迟,我们将“实时”配音定义为:可以持续流式传输音频并实时返回翻译内容的服务。

实时配音的最佳应用场景
实时配音最适合这些商业场景:
- 有全球观众
- 内容为直播
- 允许有一定 播出延迟
体育赛事
据 Forbes 2019 年报道,NBA 国际电视转播权收入达 5 亿美元。NFL 也已在 巴西、英国、德国和墨西哥举办比赛,将国际扩展视为未来核心收入来源。
大多数体育赛事本就以直播为主,观众其实已经习惯了延迟,无论是否意识到。从现场画面传到家中屏幕,延迟通常在 5 秒到几分钟之间。
现场通常有多位摄像和音频人员,将素材传回制作中心。制作中心切换画面、混音、加图文、加解说,有时还会故意增加延迟,以便及时消音不当内容。
主制作信号会传给播出网络,网络方再加品牌和广告,分发到各地。最后一公里由有线、卫星或流媒体服务送达观众。

许多制作方表示,为配音增加最多 20 秒延迟是可以接受的。观众能听到母语解说,这点远超延迟带来的影响。
体育公司最看重的是内容质量,而情感和时机的还原是关键。“He shoots, he scores!” 需要充满激情地表达。
我们的语音克隆模型能还原原说话人的情感和表达方式。与翻译不同,更多上下文不一定带来更好效果。但我们距离西班牙足球解说员的情感表现还有差距。
每个语音克隆其实是输入样本的平均值。如果把平淡的“他们只剩 2 分钟,需要更主动”与激情的“He shoots, he scores!”混合,最终的克隆效果会趋于中间。

目前,可以通过为
新闻直播
和“直播”体育类似,新闻直播也有制作流程和延迟。与媒体公司交流后发现,情感还原虽然重要,但由于新闻主播表达稳定,难度较低。最关键的是翻译要准确且有细微差别。
除了自动翻译服务可能出错外,有些概念本身就无法直接翻译。比如:
“社区聚集在一起进行纪念活动,幸存者分享了他们的故事,长者为大家祈福。”
西班牙语:“La comunidad se reunió para un día conmemorativo, donde los sobrevivientes compartieron sus historias y los ancianos realizaron oraciones tradicionales para la sanación.”
虽然技术上准确,但“survivors”和“sobrevivientes”在历史创伤语境下含义不同——英语中常带有坚韧和尊严,而西班牙语更强调受害者。同样,“performed prayers”和“realizaron oraciones”在敬意上也有差别——前者强调仪式感,后者更像流程。
补充——迈向对话式配音之路
要让不同语言的人能自然面对面交流,几乎需要瞬时翻译。
利用大语言模型的下一个 token 预测概率,可以实时判断句子走向。

图片来源 - Hugging Face “How to generate text”
如果将下一个 token 预测模型针对个人说话风格微调,就能较好预测其后续内容。这样一来,当我们对说话人接下来要说的内容有较高把握时,就可以提前进行翻译和语音生成,实现“抢跑”。
如果你对这些内容感兴趣,想和我们一起探索 AI 音频的未来,欢迎查看开放职位.




