Apresentando a IA Conversacional Multimodal
- Escrito por
- Angelo Giacco
- Publicado
OuvirOuça este artigo
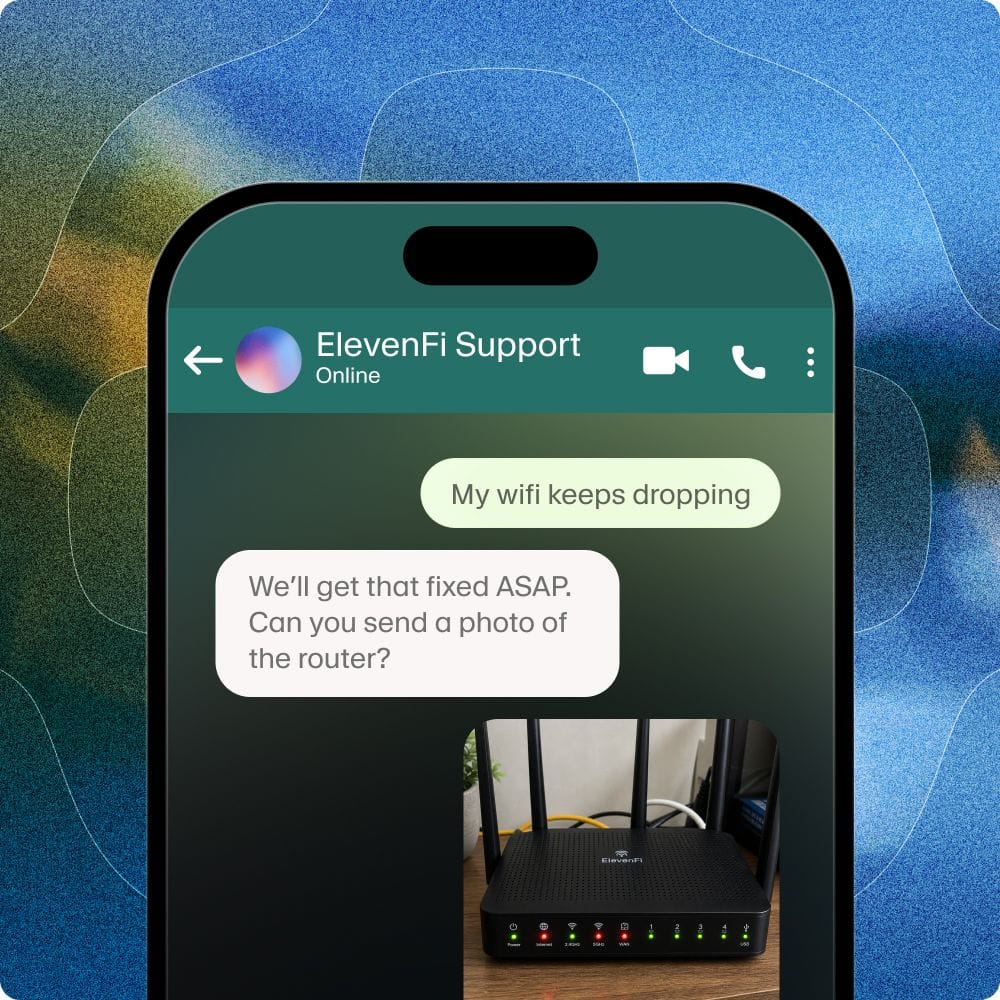
Hoje, a ElevenLabs tem o prazer de anunciar uma grande melhoria na nossa plataforma de Conversational AI: a chegada da multimodalidade real de texto e voz. Nossos agentes de IA agora entendem e processam linguagem falada e texto digitado ao mesmo tempo. Essa novidade foi criada para tornar as interações mais naturais, flexíveis e eficazes em diversas situações.
Superando Limitações das Interações Apenas por Voz
Apesar da voz ser uma forma poderosa e intuitiva de comunicação, agentes de IA apenas por voz podem enfrentar desafios em algumas situações. Observamos problemas comuns em implantações empresariais, como:
- Imprecisões na Transcrição: Capturar dados alfanuméricos específicos, como e-mails, IDs ou códigos de rastreamento apenas por voz pode ser difícil. Erros podem causar problemas sérios, como buscar registros de clientes errados.
- Experiência do Usuário para Entradas Complexas: Pedir para o usuário informar longas sequências de números, como dados de cartão de crédito, pode ser frustrante e gerar erros.
O Poder da Multimodalidade: Texto e Voz Juntos
Ao permitir que os agentes processem texto e voz, damos ao usuário a liberdade de escolher o método de entrada que preferir. Essa abordagem híbrida torna as conversas mais fluidas e robustas. O usuário pode falar normalmente e, quando precisar de mais precisão ou achar mais prático, pode digitar o texto na mesma interação.
Principais Benefícios
A chegada da multimodalidade de texto e voz traz várias vantagens importantes:
- Mais Precisão nas Interações: Permite que o usuário digite informações difíceis de falar ou que podem gerar erros na transcrição.
- Melhor Experiência do Usuário: Oferece flexibilidade, tornando as interações mais naturais e menos limitadas, especialmente para dados sensíveis ou complexos.
- Maior Taxa de Conclusão de Tarefas: Reduz erros e frustrações, aumentando o sucesso das interações.
- Conversas Mais Naturais: Permite alternar facilmente entre tipos de entrada, como em uma conversa humana.
Principais Funcionalidades
Nossa IA Conversacional multimodal inclui as seguintes funções:
- Processamento Simultâneo: Os agentes interpretam e respondem a entradas de voz e texto ao mesmo tempo, em tempo real.
- Configuração Fácil: A entrada de texto pode ser ativada facilmente nas configurações do widget.
- Modo Apenas Texto: Os agentes podem ser configurados para funcionar como chatbots tradicionais, só com texto, se necessário.
Integração e Implantação Simples
Essa nova funcionalidade multimodal já é compatível em toda a nossa plataforma:
- Widget: Pode ser implementado com uma única linha de HTML.
- SDKs: Suporte completo para desenvolvedores que querem integrar de forma avançada.
- WebSocket: Comunicação bidirecional em tempo real com recursos multimodais.
Baseado em uma Plataforma de Referência
As interações multimodais aproveitam todas as inovações já presentes na nossa plataforma de Conversational AI:
- Vozes de Referência no Mercado: Acesso às vozes de mais alta qualidade em mais de 32 idiomas.
- Modelos Avançados de Fala: Aproveitando nossa tecnologia avançada de Speech to Text e
- Infraestrutura Global: Já disponível em todo lugar com infraestrutura Twilio e SIP trunking.
Como Começar
Para usar a multimodalidade de texto e voz com seus agentes de Conversational AI da ElevenLabs,acesse as configurações do seu widget.:
- Ative a opção "Permitir entrada de texto".
- Acreditamos que a multimodalidade texto+voz vai ampliar muito as possibilidades e a experiência dos usuários de
Conversational AI. Estamos animados para ver como nossos usuários vão aproveitar esse novo recurso.
.jpg&w=3840&q=80)