Obsługa obrazów i dokumentów w ElevenAgents
- Opublikowano
- Ostatnia aktualizacja
PosłuchajPosłuchaj tego artykułu
Kierownik budowy zauważa brak materiałów na placu. Robi zdjęcie, wysyła je agentowi ds. zamówień na WhatsAppie i potwierdza adres dostawy głosowo. Agent analizuje zdjęcie, rozpoznaje brakujące rzeczy i składa pilne zamówienie – wszystko w jednej rozmowie. W firmach często liczy się kontekst, którego nie da się przekazać samymi słowami. Potrzebne informacje mogą być zdjęciem uszkodzonego przedmiotu albo PDF-em z regulaminem. Przekazanie ich bezpośrednio agentowi skraca rozmowę i przyspiesza rozwiązanie sprawy. Gdy klient może coś pokazać zamiast opisywać, agent szybciej rozwiązuje problem bez proszenia o zmianę kanału.Rohlik, jedna z największych platform spożywczych online w Europie, obsługuje swojego agenta przez telefon, web, aplikację i WhatsApp w sześciu językach i automatycznie rozwiązuje 90% zgłoszeń klientów. Multimodalne wejście pozwala osiągnąć taki sam poziom obsługi także wtedy, gdy klient musi coś pokazać, a nie tylko opisać. ElevenAgents traktuje pliki jako pełnoprawne dane wejściowe w tym samym agencie, który obsługuje już głos, WhatsApp, web i mobile. Pliki trafiają do modelu jako natywne wiadomości, więc jeden agent obsługuje każdy typ wejścia w jednej rozmowie.
W tym wpisie wyjaśniamy, czym jest multimodalność na platformie, jak pliki trafiają z urządzenia klienta do modelu, co obsługuje każdy kanał i jak przenosić kontekst między sesjami, gdy klient wraca.
Kanały i wejścia
ElevenAgents działa w kanałach, z których firmy już korzystają, by docierać do klientów: aplikacje webowe i mobilne, platformy wsparcia, telefon, SMS, e-mail, WhatsApp i inne. Konfiguracja agenta (prompt, model, narzędzia, baza wiedzy i głos) jest ustawiana raz i działa we wszystkich kanałach. Dwie rzeczy różnią się w zależności od kanału: warstwa transportowa i obsługiwane typy wejścia. Aplikacje webowe i mobilne łączą się przez osadzany widget, jedno z SDK lub Agents WebSocket. Rozmowy telefoniczne łączą się przez natywną integrację z Twilio, SIP trunking lub natywny websocket-based
Wejścia plikowe (obrazy i PDF-y) są obecnie obsługiwane na webie, mobile i WhatsAppie. Obsługa wejść zależy od typu, nie od kanału: zdjęcie i notatka głosowa wysłane w tej samej sesji WhatsApp trafiają do modelu różnymi ścieżkami. Niezależnie od kanału i typu wejścia, wszystko trafia do tej samej warstwy przetwarzania przed przekazaniem do modelu jako natywny kontekst, gdzie idzie jedną z dwóch dróg.
Reprezentacja wejścia: plikowa vs. inline
Niezależnie od typu wejścia czy kanału, platforma normalizuje każde wejście do jednej z dwóch wewnętrznych reprezentacji przed przekazaniem do modelu. To, jak zostanie zaklasyfikowane, decyduje o tym, jak wejście jest kodowane w oknie kontekstu modelu i co musi obsłużyć twoja integracja.
Wejścia plikowe
Obrazy i PDF-y trafiają do modelu jako natywne odwołania do plików, a nie streszczenia tekstowe. Platforma zapisuje plik, nadaje mu file_id i przypisuje ten identyfikator do danej tury użytkownika. Model obsługujący obrazy lub dokumenty dostaje surowy plik w swoim oknie kontekstu, a nie przetworzoną wersję. Integracja jest prosta: pobierz file_id zwrócone przez endpoint uploadu i dołącz je do wiadomości. Jeśli wiadomość zostanie wysłana bez file_id, model nie ma dostępu do pliku, nawet jeśli upload się udał. Pliki są powiązane z rozmową. Jeśli coś ma przetrwać poza sesją (sam plik, wyodrębnione dane lub wynik w strukturze), musisz to obsłużyć po swojej stronie. Sposób zależy od kanału i zastosowania.
W linii
Druga reprezentacja to inline i obejmuje całą resztę. Głos i notatki głosowe są transkrybowane. Tekst wpisany, transkrypcje mowy, pinezki lokalizacji WhatsApp i wizytówki są normalizowane do zwykłego tekstu w transkrypcji przed uruchomieniem modelu. Pinezka lokalizacji to współrzędne i opcjonalny adres, kontakt to imię i numer telefonu. Nic z tego nie jest przechowywane jako plik ani nie tworzy odwołania do pliku. Te dane są bezpośrednio w transkrypcji.
Dlaczego ten podział jest ważny
Podział decyduje, gdzie musisz zintegrować swój system. Ścieżka inline nie wymaga od ciebie żadnych działań w trakcie rozmowy: platforma normalizuje wejścia do tekstu i są one od razu w transkrypcji. Ścieżka plikowa wymaga osobnej integracji. Zamiast konwertować plik na tekst przed modelem, orchestrator przekazuje surowy plik bezpośrednio do okna kontekstu modelu. Model pracuje na strukturze pliku, a nie na przetworzonym tekście czy opisie, więc zachowuje układ, strukturę wizualną i formatowanie dokumentu, które w innym przypadku by zniknęły. Mając to na uwadze, dalej opisujemy implementację: jak skonfigurować agenta, jak pliki przechodzą przez kanały i jak przenosić kontekst między sesjami.
Konfiguracja wejścia multimodalnego
Włączenie wejścia multimodalnego zaczyna się od tej samej konfiguracji agenta na webie, mobile i WhatsAppie. Dalej sposób uploadu i pobierania pliku zależy od kanału.
Włączanie wejścia plikowego
Aby wejście plikowe działało, musisz ustawić dwie rzeczy w konfiguracji agenta. Po pierwsze, ustaw conversation_config.conversation.file_input.enabled na True – przez API przy tworzeniu agenta lub w Ustawienia > Zaawansowane > Wejście plikowe w panelu. Po drugie, agent musi mieć model obsługujący obrazy i dokumenty. Sama flaga nic nie da, jeśli model nie obsługuje bloków obrazów lub dokumentów – oba ustawienia muszą być aktywne przed testami.
SDK i WebSocket
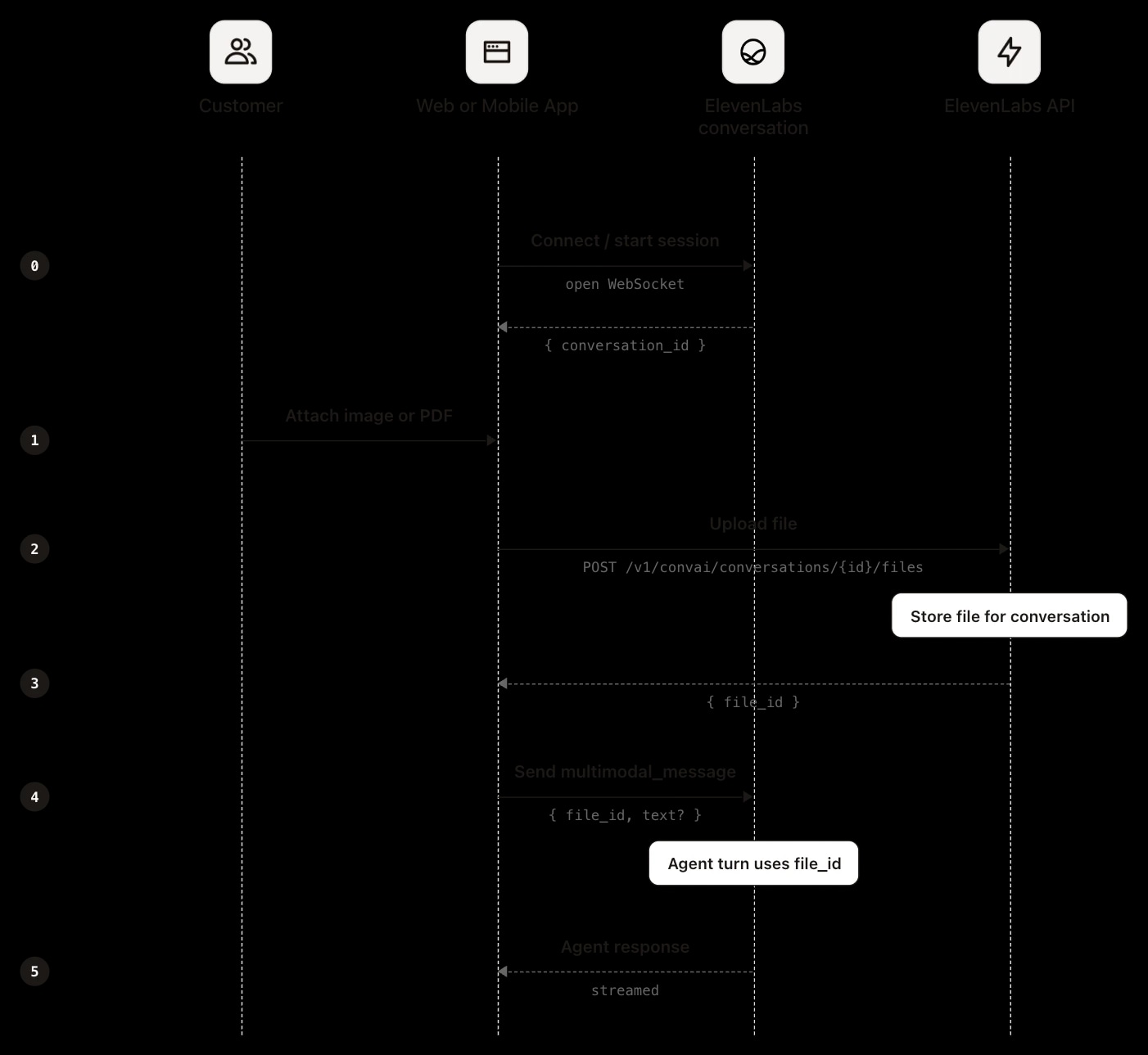
Wejście plikowe na webie lub mobile wymaga własnego klienta czatu opartego na SDK lub surowym połączeniu Agents WebSocket. Schemat jest taki sam dla wszystkich trzech, a kolejność jest kluczowa: plik musi być wrzucony przed wysłaniem wiadomości, bo payload wiadomości odwołuje się do identyfikatora z uploadu.
Najpierw wrzuć plik:
Zobacz upload pliku żeby zobaczyć pełny request i response:
Potem wyślij wiadomość przez połączenie, odwołując się do zwróconego file_id:
SDK upraszcza upload i referencję do jednego wywołania, obsługując identyfikator pliku wewnętrznie. Zobacz specyfikacjęwiadomość multimodalna żeby poznać pełny format wiadomości. Ponieważ twoja aplikacja wykonuje upload, plik masz już u siebie. Jeśli potrzebujesz go tylko do bieżącej rozmowy, wystarczy upload i referencja. Jeśli chcesz go zachować na dłużej, najlepiej zapisać go od razu przy uploadzie. Możesz też pobrać go później przez webhook po rozmowie – opisujemy to w sekcji o kontekście między sesjami.
Na WhatsAppie twoja aplikacja nie bierze udziału w uploadzie. Gdy klient wysyła obraz, dokument lub naklejkę, plik trafia najpierw do infrastruktury Meta. Meta powiadamia ElevenLabs przez webhook WhatsApp Business API, a ElevenLabs używa twoich danych konta WhatsApp Business, by pobrać plik serwer-serwer, zapisuje swoją kopię i dołącza ją do rozmowy tak samo jak upload z weba czy SDK. Agent dostaje to jako wejście multimodalne, a w transkrypcji pojawia się zdarzenie file_input.
Ponieważ twoja aplikacja nie obsługuje uploadu, nie ma bezpośredniego dostępu do pliku. Nie ma tu ścieżki pobrania pliku w momencie uploadu jak na webie czy mobile. Plik trafia do twojego systemu przez file_url w webhooku po rozmowie, który wskazuje na kopię przechowywaną przez ElevenLabs. URL od Meta służy tylko do pobrania przez ElevenLabs i nie jest udostępniany na zewnątrz. Szczegóły pobierania, w tym ograniczenia czasowe, opisujemy w sekcji o kontekście między sesjami.
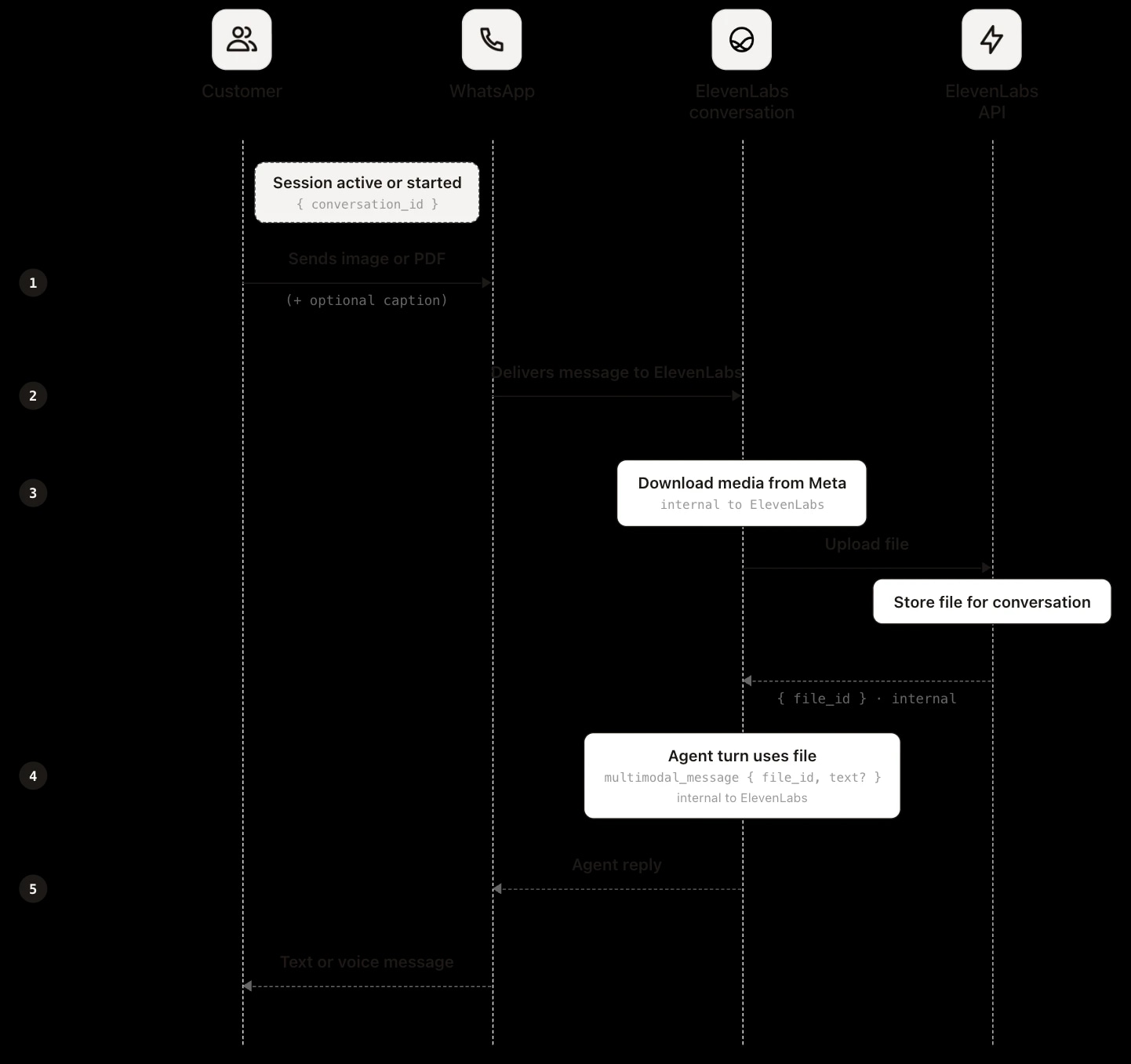
Na WhatsAppie klient wysyła plik na czacie. ElevenLabs pobiera go od Meta, zapisuje i przypisuje file_id po stronie platformy. Nie ma tu uploadu po stronie klienta. W przeciwieństwie do weba i mobile twoja aplikacja nie wywołuje POST /v1/convai/conversations/{id}/files ani nie wysyła wiadomość multimodalna przez WebSocket. ElevenLabs obsługuje dostarczenie, zapis i turę agenta.
Przenoszenie kontekstu między sesjami
ElevenAgents traktuje każdą rozmowę osobno. Nic, co klient wyśle ani co agent rozwiąże w trakcie rozmowy, nie przechodzi automatycznie do kolejnej. Agent przekazuje twojemu systemowi wszystko z zakończonej rozmowy przez webhook po rozmowie, ale pamięć między rozmowami jest już po twojej stronie. To ty odpowiadasz za ciągłość.
Ta granica architektury jest ważna i warto ją dobrze zaplanować. Rozmowy, w których multimodalność ma największe znaczenie (klient robi zdjęcie uszkodzonego produktu, wrzuca dokument, udostępnia lokalizację), rzadko kończą się w jednej sesji. Klient, który wysyła zdjęcie uszkodzonej części i umawia się na oddzwonienie, oczekuje, że agent zapamięta zdjęcie przy kolejnym kontakcie. Bez zarządzania kontekstem agent zaczyna od zera i klient musi wszystko powtarzać. Rozwiązanie składa się z dwóch części. Po zakończeniu rozmowy webhook przekazuje transkrypcję, wyniki analizy, zebrane dane i URL-e plików, które przeszły przez sesję. Twój backend zapisuje to, co ważne, pod trwałym identyfikatorem klienta, np. numerem telefonu, ID użytkownika czy kluczem konta. Gdy klient wraca, twoja aplikacja wstrzykuje zapisany kontekst na początku sesji przez zmienne dynamiczne, więc agent zaczyna rozmowę z tym, co już wie. W przypadku wejść plikowych URL pliku w webhooku wskazuje na kopię przechowywaną przez ElevenLabs i to jedyna droga pobrania po zamknięciu rozmowy. Kopia platformy jest powiązana z sesją, więc jeśli potrzebujesz pliku w przyszłej rozmowie lub swoim systemie, musisz go pobrać z payloadu webhooka zanim okno się zamknie. Jak szybko musisz działać, zależy od polityki retencji – szczegóły znajdziesz w dokumentacji. Webhook wynosi stan na zewnątrz. Zmienne dynamiczne wprowadzają go z powrotem. Cała reszta to już twoja odpowiedzialność – tu jest najwięcej pracy, jeśli klienci wracają, eskalują sprawy lub wracają do niedokończonych zgłoszeń.
Wstrzykiwanie kontekstu zależy od kanału
Mechanizm wstrzykiwania różni się w zależności od kanału, ale schemat jest ten sam. W telefonii ElevenLabs dzwoni do twojego serwera przed połączeniem, dając ci szansę wyszukać numer i zwrócić zmienne dynamiczne, np. imię, numer zamówienia czy poziom konta, zanim agent zacznie mówić. Na WhatsAppie webhook przed wiadomością odpala się przy każdym przychodzącym komunikacie, pozwalając ci wzbogacić go o dane z twojego systemu zanim agent go przetworzy. W pozostałych przypadkach te same pola przekazujesz wconversation_initiation_client_data przy otwarciu sesji. ElevenAgents nie łączy sesji z różnych kanałów w jeden wątek. Rozmowa na WhatsAppie i na webie to osobne sesje, nawet jeśli dotyczą tego samego klienta. Ale ponieważ webhook i zmienne dynamiczne działają tak samo na wszystkich kanałach, jedna warstwa zapisu obsługuje je wszystkie. Zbuduj ją raz i działa na każdym kanale, na którym działa agent. Wstrzykiwanie kontekstu dotyczy danych tekstowych: imion, numerów zamówień, podsumowań, pól strukturalnych. Pliki to osobny przypadek i wymagają innego podejścia.
Przenoszenie plików dalej
Pliki są powiązane z jedną rozmową i nie przechodzą dalej automatycznie. Co przenosić dalej, zależy od tego, czy w kolejnej rozmowie potrzebujesz informacji z pliku, czy samego pliku. Najczęściej wystarczy informacja. Agent interpretuje wrzucony plik w tej samej turze, ale nie zapisuje tej interpretacji automatycznie w żadnym trwałym miejscu. Dane strukturalne pochodzą z danych po rozmowie: transkrypcji, podsumowania i pól, które zdefiniujesz. Jeśli klient wysyła zdjęcie pękniętej uszczelki drzwi i wraca tydzień później, by dopytać o reklamację, agent nie potrzebuje już zdjęcia. Musi wiedzieć, że sprawa dotyczy pękniętej uszczelki drzwi. Wyciągasz to z danych po rozmowie, zapisujesz pod identyfikatorem klienta i wstrzykujesz jako zmienną dynamiczną, gdy wraca. Zwykle wystarczy krótkie podsumowanie lub kilka pól.
Gdy potrzebujesz oryginalnego pliku – do archiwum, zgodności czy innych systemów – webhook po rozmowie to droga pobrania. Każdy wrzucony plik pojawia się w transkrypcji jako zdarzenie file_input z podpisanym URL-em pliku. Ten URL jest ważny przez piętnaście minut, więc pobierz i zapisz plik od razu po otrzymaniu webhooka, nie odkładaj tego na później. Jeśli przegapisz okno, a rozmowa jeszcze istnieje, API GET conversation wygeneruje nowe URL-e. Planuj, że file_input może nie być w niektórych przypadkach, np. przy zerowej retencji, więc nie zakładaj, że każda tura z plikiem ma URL.
To zamyka cały cykl: plik trafia do sesji, model pracuje na nim natywnie, dane strukturalne wychodzą przez webhook, a twoja warstwa zapisu decyduje, co agent wie następnym razem.
Podsumowanie
Ta sama konfiguracja agenta przyjmuje obrazy i PDF-y na webie, mobile i WhatsAppie bez osobnej budowy na każdy kanał. Pliki są normalizowane, przypisywane do tury i przekazywane do modelu jako natywne bloki, a nie streszczenia tekstowe, więc układ, struktura i formatowanie dokumentu trafiają do modelu bez zmian. Kontekst między sesjami działa tak samo na każdym kanale: webhook po rozmowie wynosi stan na zewnątrz, zmienne dynamiczne wprowadzają go z powrotem.
Jeśli budujesz na ElevenLabs Agents i chcesz, żeby twój agent działał na obrazach i dokumentach obok głosu i tekstu, włącz wejście multimodalne i daj nam znać, co o tym myślisz.

.jpg&w=3840&q=80)

.jpg&w=3840&q=80)
