ナレーション
オーディオブックやポッドキャストを生き生きとさせる表現豊かな音声
ナレーション
オーディオブックやポッドキャストを生き生きとさせる表現豊かな音声

会話型
インフォーマルなシナリオに最適なナチュラルボイス。
キャラクター
アニメやビデオゲーム向けの遊び心あふれる魅力的な音声

SNS
短編コンテンツ向けのトレンディで注目を集める音声

エンターテインメント
番組、トレーラー、プロモ用の放送レディ音声

広告
行動を促し、ブランドを印象付ける説得力のある音声。
教育
チュートリアルやeラーニングに最適な、明瞭で信頼感のある声。

声は一瞬間を置き、[優しく]考えをまとめるかのように続けた。息づかいは意図的で、ためらいも完璧なタイミングだった。
これはもう合成音声ではなく、[暖かく笑う]タイミングや感情、言葉の間を理解する声だった。
テキストが存在感に変わる。[満足げにため息をつく]言葉に命、個性、魂が宿る。
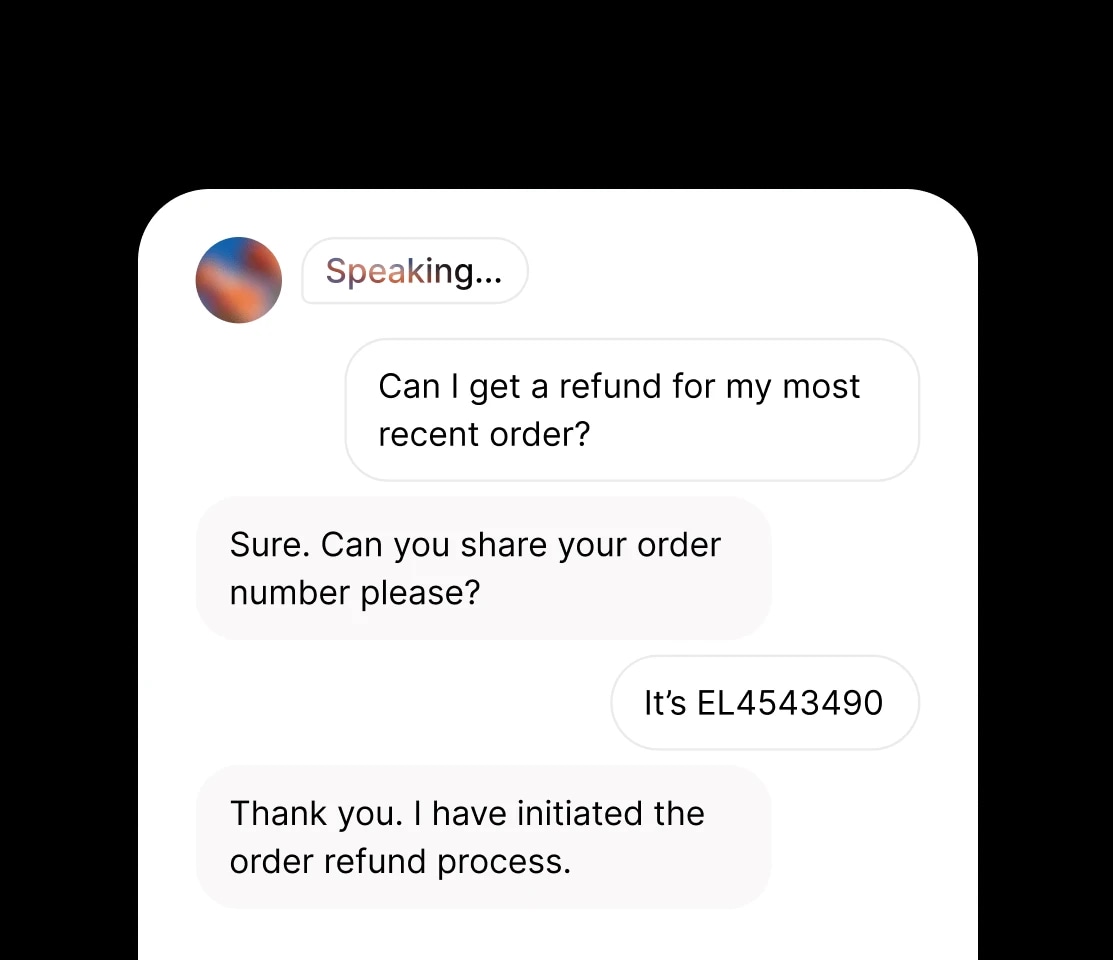
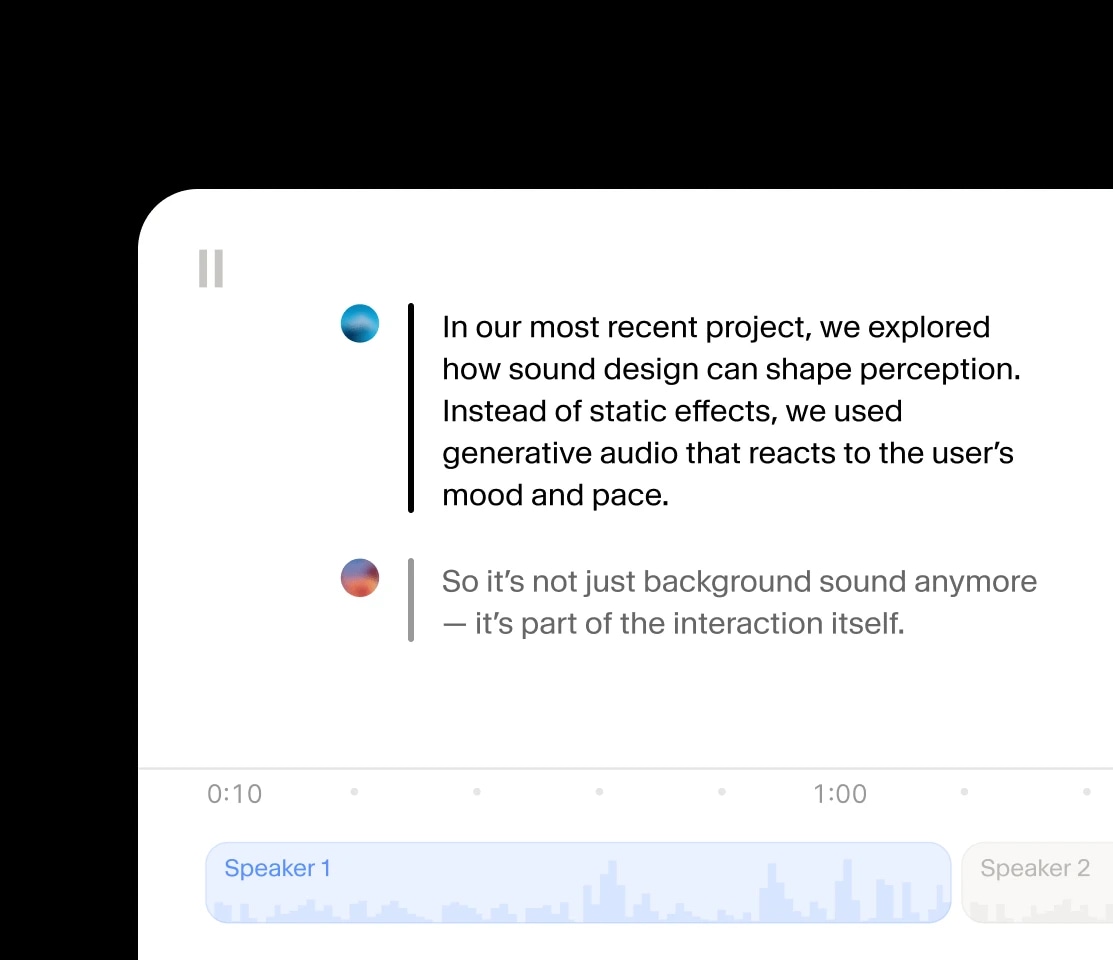
感情やオーディオイベント、没入感のあるサウンドスケープを重ねた、コントロール可能で表現豊かな音声を作成できます。
話者同士が文脈や感情を共有する音声会話を作成できます。
自分の声をすぐに再現したり、独自のAI音声を自由に作成できます。
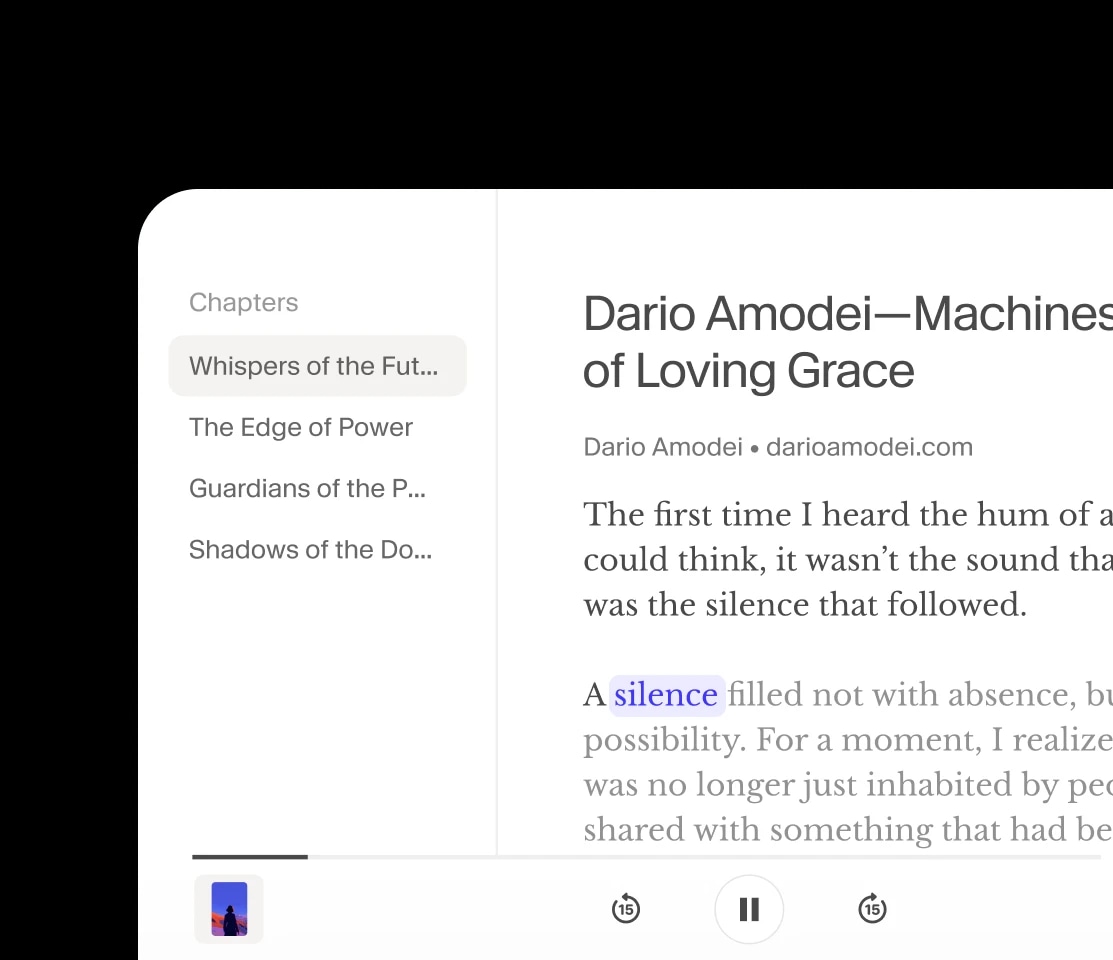
70以上の言語で、ネイティブレベルの感情と明瞭さでストーリーを表現。



感情を細かくコントロールできるオーディオタグ付きの最先端・表現力豊かなモデル。ストーリーテリングやゲーム、70以上の言語でのメディア制作に最適。

29言語対応で最もリアルかつ感情豊かなテキスト読み上げモデル。ボイスオーバーやオーディオブック、ポストプロダクションやコンテンツ制作に最適。

32言語対応の高品質・低遅延TTSモデル。スピード重視や非英語用途のデベロッパーに最適

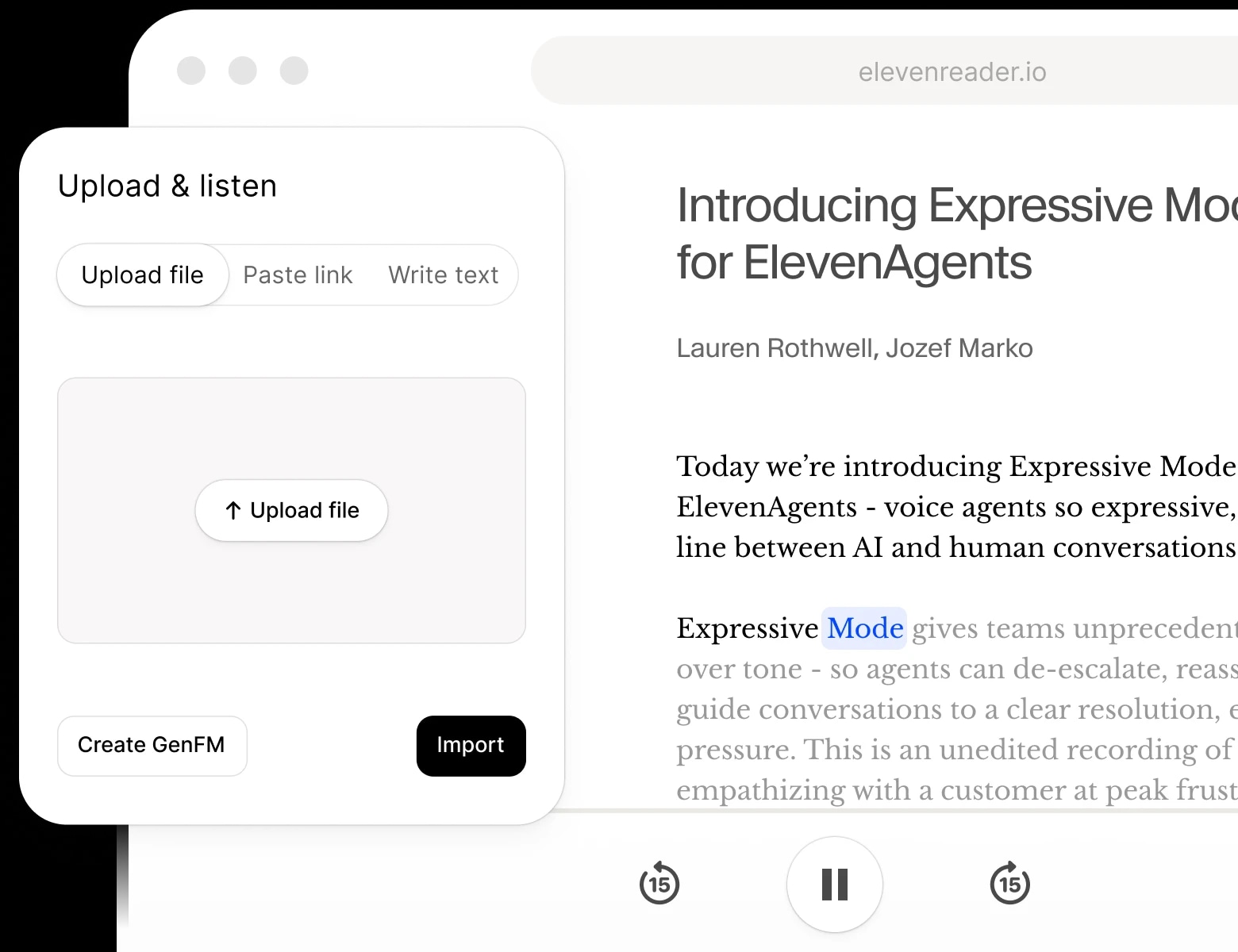
記事やPDF、電子書籍、ウェブページを、ElevenReader(iOS・Android・Chrome対応の無料読み上げアプリ)の驚くほど自然なAI音声で聴けます。ご自分のコンテンツをアップロードしたり、収録済みの本から選んだり、お好きな声を選んで、通勤・勉強・リラックスタイムに聴いてみてください。




.webp&w=3840&q=80)