
Your comprehensive workflow for turning books into audiobooks and scripts into podcasts
With Text to Speech, stories can be heard immediately upon publishing, in a variety of voices and delivery styles


Text to Speech (TTS) technology, at its core, transforms written content into audible speech. Over recent years, with substantial advancements in machine learning, TTS technology has evolved to a point where synthesized speech is practically indistinguishable from human narration. The realism and expressiveness achieved by modern TTS systems offer unmatched potential, particularly for the publishing industry.
For news publishers, the sonic landscape is not just an emerging field but a requisite to engagement. Growing an audio presence has proven to enhance user retention and satisfaction. While the traditional route would involve hiring voice actors or getting reporters to narrate, these methods are neither time nor cost-efficient. With Text to Speech, stories can be vocalized immediately upon publishing, ensuring that the content remains fresh, relevant, and of high quality.
How we achieve human delivery even on very long texts is down to the way we’ve built our model. It’s trained to understand what is being said and to adjust delivery accordingly. It does this by taking into account not just the meaning of words but also the context surrounding each utterance.
Traditional speech generation algorithms produce utterances on a sentence-by-sentence basis. This is computationally less demanding but immediately comes across as robotic. Emotions and intonation often need to stretch and resonate across a number of sentences to tie a particular train of thought together. Tone and pacing convey intent which is really what makes speech sound human in the first place. So rather than generate each utterance separately, our model takes the surrounding context into account, maintaining appropriate flow and prosody across the entire generated material. This emotional depth, coupled with prime audio quality, provides users with the most genuine and compelling narrating tool out there.
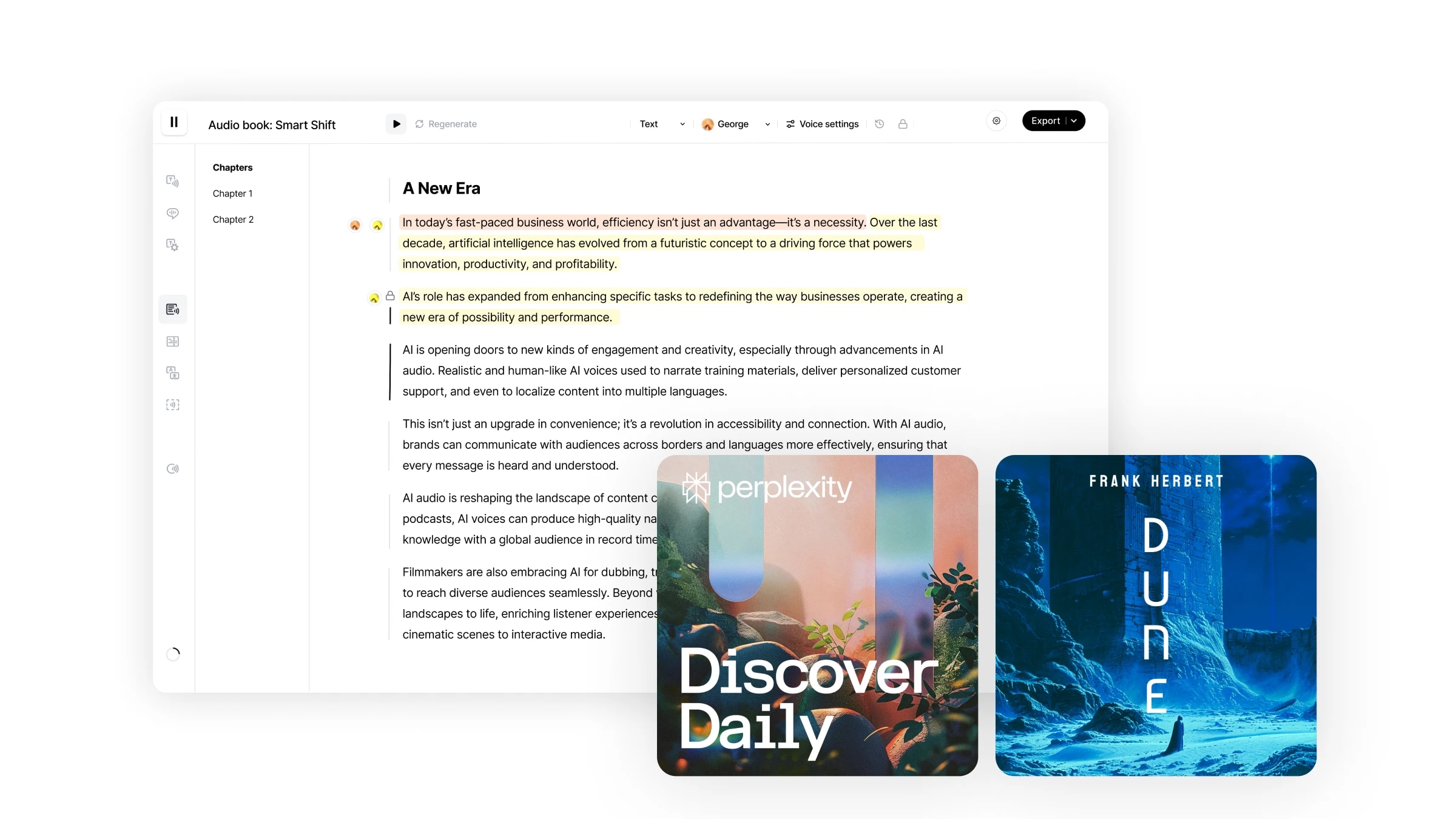
Studio is our end-to-end workflow for crafting audiobooks in minutes. It offers an unprecedented level of control over your audio creations with the ability to regenerate specific audio chunks, assign different speakers to particular text fragments, directly import multiple format files, and more.
Navigating Studio is easy and intuitive.
Studio provides a straightforward user experience, akin to using Google Docs, with an intuitive, user-centric interface supporting a variety of editing features:
Your comprehensive workflow for turning books into audiobooks and scripts into podcasts
Studio stands alongside Speech Synthesis, VoiceLab, and Voice Library, serving as a comprehensive solution for long-form audio synthesis. Additionally, it's seamlessly integrated with Professional Voice Cloning, Voice Library, and our multilingual model.
At ElevenLabs, our commitment to innovation has led to the launch of a new multilingual model. This allows the same narrative to be translated and vocalized in up to 28 languages. For publishers, this means unprecedented global reach, with stories resonating across different cultures and regions, all in a consistent and unified voice.
Supported languages now include: English, Korean, Dutch, Chinese, Turkish, Swedish, Indonesian, Filipino, Japanese, Ukrainian, Greek, Czech, Finnish, Romanian, Danish, Bulgarian, Malay, Slovak, Croatian, Classic Arabic, Polish, German, Spanish, French, Italian, Hindi, Portuguese, and Tamil.
Our proprietary Voice Design tool provides a transformative experience for publishers. It facilitates the creation of completely unique voices based on selected parameters, such as age, gender and accent. Every generated voice is unique, ensuring that publishers can choose a particular voice to become synonymous with their brand or publication.
Professional Voice Cloning (PVC) technology at ElevenLabs offers another layer of customization. By cloning the voices of a publication's reporters, we can produce audio stories in their unique tones. This not only provides authenticity but also significantly reduces costs and time spent on traditional recording processes. What's more, our multilingual model is compatible with Professional Voice Cloning, ensuring that a reporter's voice can now speak all the supported languages.

Automate video voiceovers, ad reads, podcasts, and more, in your own voice
Listen to a podcast episode generated with our Professional Voice Cloning tool:
For publishers, Professional Voice Cloning (PVC) offers numerous advantages:
When combined with Text to Voice technology, publishers are equipped with a state-of-the-art toolkit to produce rich, varied, and global auditory content. Adopting the capabilities of Professional Voice cloning Technology is a progressive move for publishers, opening a myriad of opportunities.
The future of publishing is not just in the written word but in how those words are conveyed. With tools like Text to Voice, publishers have the potential to revolutionize their content delivery, ensuring accessibility, uniqueness, and global reach. At ElevenLabs, we're at the forefront of this transformation, offering technology that paves the way for a richer, more diverse auditory experience.
Update: as of January 2025, Projects is now called Studio and is available to all free users.

AI-generated videos created with avatars & dubbed voice have grown 7x

The Dutch DJ, producer, and founder uses ElevenLabs to create voice content anywhere - backstage, in transit, or between shows
Powered by ElevenLabs Conversational AI